

Google DeepMind hat heute bedeutende Erweiterungen seiner Gemini 2.5-Familie angekündigt und die stabilen Versionen von Gemini 2.5 Pro und Gemini 2.5 Flash sowie eine Vorschau auf das brandneue Gemini 2.5 Flash-Lite-Modell vorgestellt. Diese Updates spiegeln Googles anhaltendes Engagement wider, ein Spektrum an KI-Modellen anzubieten, die Kosten, Geschwindigkeit und Leistung für unterschiedliche Workloads ausbalancieren.
Stabile Versionen: Gemini 2.5 Pro & Flash
Am 17. Juni 2025 gab Google die allgemeine Verfügbarkeit von Gemini 2.5 Pro und Gemini 2.5 Flash bekannt. Die Pro-Variante bietet maximale Argumentationsleistung und ist auf hochkomplexe Aufgaben wie fortgeschrittene Codegenerierung, wissenschaftliche Analysen und die Synthese umfangreicher Daten zugeschnitten. Im Gegensatz dazu bietet Gemini 2.5 Flash eine Mittelklasse-Option, die für alltägliche Anwendungen mit geringen Latenzzeiten optimiert ist – ideal für Chatbots, Zusammenfassungen und die Erstellung umfangreicher Inhalte.
Übersicht: Drei Modelle der Gemini-2.5-Familie
| Modell | Status | Stärken | Ideale Anwendungsfälle |
|---|---|---|---|
| Gemini 2.5 Flash‑Lite (Vorschau) | Vorschau | Schnellste und günstigste; multimodal; kontrollierbares Denken; werkzeuggestützte | Aufgaben mit hohem Volumen wie Chatbots, Zusammenfassung, Suche |
| Gemini 2.5 Flash | Stabil | Ausgewogen: geringe Latenz, gute Argumentation, multimodal | Echtzeit-Gespräche, Kundensupport |
| Gemini 2.5 Pro | Stabil | Am fähigsten: tiefes Denken, großer Kontext, multimodal | Recherche, komplexes Coding, wissenschaftliche Aufgaben |
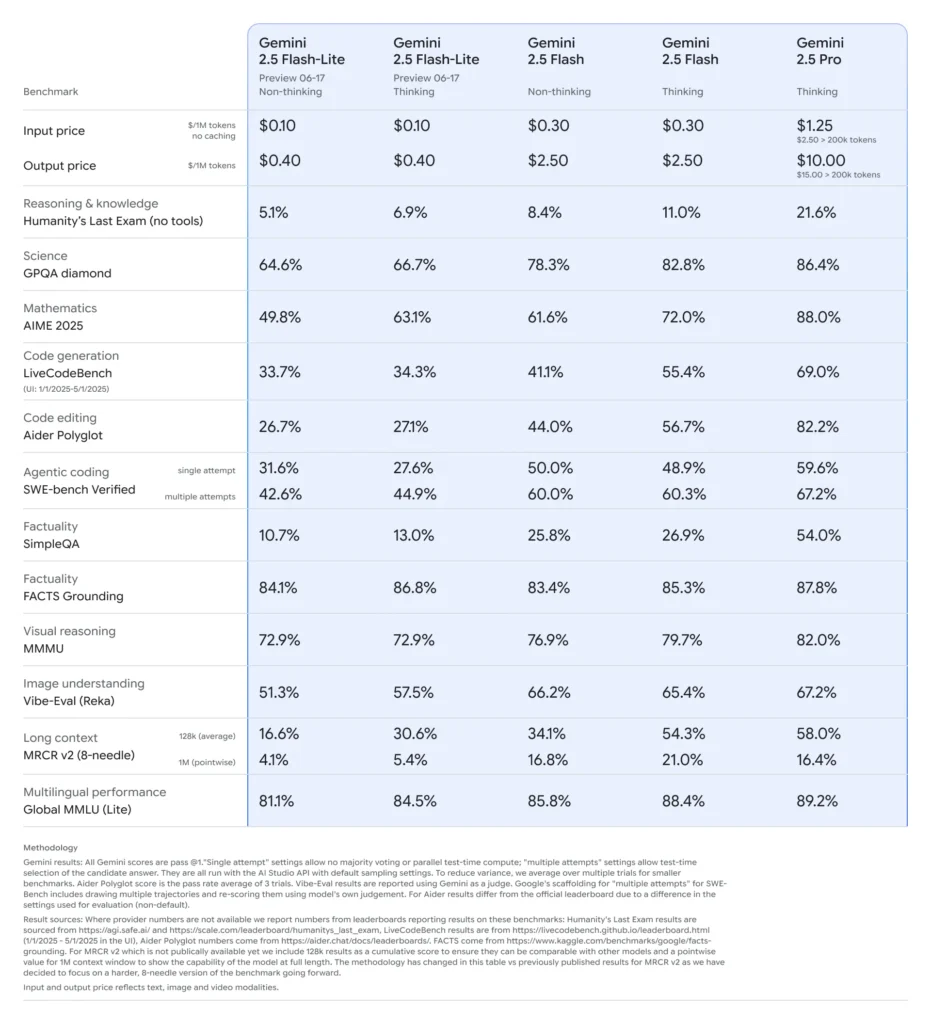
Gemini 2.5 Flash‑Lite: Highlights der Vorschau
Extrem niedrige Latenz und Kosteneinsparungen:Entwickelt für Echtzeitanwendungen mit hohem Volumen wie Übersetzung, Klassifizierung und Zusammenfassung. Bietet schnellere Inferenz und geringere Kosten pro Aufruf im Vergleich zu 2.0 Flash-Lite und der vollständigen Flash-Version.
Verbesserte grundlegende Leistung: Übertrifft frühere Flash-Lite-Modelle bei Benchmarks in den Bereichen Codegenerierung, Logik, Mathematik, multimodales Denken und Naturwissenschaften.
Kosten und Effizienz: Flash-Lite-Preise (Vorschau): ~0.10 $ pro 1 Mio. Eingabetoken und ~0.40 $ pro 1 Mio. Ausgabetoken – deutlich günstiger als Flash (0.30 $/2.50 $) und Pro (1.25 $/10 $).
Vollständige Gemini-2.5-Funktionen:
- Kontrollierbares Denken: Benutzer können „Denkbudgets“ (Token-Limits) festlegen, um Geschwindigkeit gegen Tiefe einzutauschen – Flash-Lite kann dies nach Bedarf aktivieren.
- Multimodale Eingabe: Unterstützt Text, Bilder, Audio und Video (einschließlich stundenlanger Clips) und bietet die Möglichkeit, Diagramme, Benutzeroberflächen, Szenen und Ereigniszusammenfassungen zu analysieren.
- Werkzeugintegration: Beinhaltet Google-Suche, Codeausführung und ein Kontextfenster mit einer Million Token, das den Funktionen von Flash und Pro entspricht.
Positionierung auf der Preis-Leistungs-Kurve
Google positioniert Flash‑Lite mit hoher Geschwindigkeit und niedrigen Kosten als Pareto-Grenze, was bedeutet, dass es zu den kosteneffizientesten und dennoch leistungsfähigsten Modellen weltweit gehört (). In vergleichenden Bewertungen Flash‑Lite bietet das beste Preis-Leistungs-Verhältnis: intelligent und dennoch erschwinglich.
Über Flash und Pro
- Gemini 2.5 Flash: Stabiles, multimodales Denkmodell mit geringer Latenz. Es liegt unter Pro, ist aber in seiner Leistungsfähigkeit in etwa auf Augenhöhe mit GPT-4o, mit höherer Geschwindigkeit und Kosteneffizienz ().
- Gemini 2.5 Pro: Das fortschrittlichste Modell von Google. Bekannt für die Verarbeitung stundenlanger Video-/Audiodateien, komplexer Codes und mathematischer Berechnungen sowie für das logische Denken in großen Zusammenhängen. Führt außerdem selektive „Denkbudgets“ und verbesserte Codequalität ein, um als langfristig stabiles KI-Flaggschiff zu dienen.
Bereitstellung und Preise
- Verfügbarkeit: Alle drei Modelle sind zugänglich über Google AI Studio, Google Cloud Vertex-KIund die Gemini-App .
- Kostenstruktur (Preise für Vertex AI ab 16. Juni 2025):
- Pro: $1.25/1 Mio. Eingabe, $10/1 Mio. Ausgabe (höher als 200 Token)
- Blinken (Flash): 0.15 $/1 Mio. Eingabe, 3.50 $/1 Mio. Ausgabe im „Denkmodus“ – und beinhaltet täglich 1,500 kostenlose fundierte Eingabeaufforderungen ()
- Flash‑Lite (Vorschau): ~$0.10/$0.40 pro 1 Mio. Token
Erste Schritte
CometAPI bietet eine einheitliche REST-Schnittstelle, die Hunderte von KI-Modellen aggregiert – unter einem konsistenten Endpunkt, mit integrierter API-Schlüsselverwaltung, Nutzungskontingenten und Abrechnungs-Dashboards. Anstatt mit mehreren Anbieter-URLs und Anmeldeinformationen zu jonglieren.
Entwickler können zugreifen Gemini 2.5 Flash-Lite (Vorschau) API - durch Konsolidierung, CometAPIDie neuesten Modelle sind zum Veröffentlichungsdatum des Artikels aufgeführt. Erkunden Sie zunächst die Funktionen des Modells im Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bieten einen Preis weit unter dem offiziellen Preis an, um Ihnen bei der Integration zu helfen.