GPT-4o Audio-API: Ein einheitliches /chat/completions Endpunkterweiterung, die Opus-kodierte Audio- (und Text-)Eingaben akzeptiert und synthetisierte Sprache oder Transkripte mit konfigurierbaren Parametern zurückgibt (Modell=gpt-4o-audio-preview-<date>, speed, temperature) für Batch- und Streaming-Sprachinteraktionen.
Grundlegende Informationen zu GPT-4o Audio
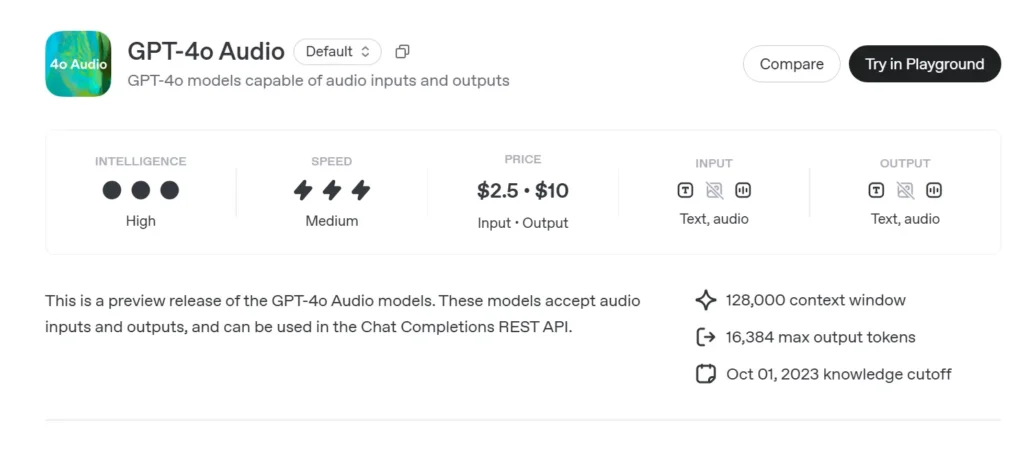
GPT-4o-Audiovorschau (gpt-4o-audio-preview-2025-06-03) ist OpenAIs neueste sprachzentriertes großes Sprachmodell bereitgestellt durch den Standard Chat-Abschlüsse-API anstelle des Echtzeitkanals mit extrem niedriger Latenz. Diese Variante basiert auf der gleichen „Omni“-Grundlage wie GPT-4o und ist spezialisiert auf High-Fidelity-Spracheingabe und -ausgabe für rundenbasierte Konversationen, Inhaltserstellung, Barrierefreiheitstools und agentenbasierte Workflows, die keine Millisekunden-Zeitmessung erfordern. Es übernimmt alle Stärken der Textbegründung von GPT-4-Klassenmodellen und fügt hinzu End-to-End-Sprache-zu-Sprache (S2S) Pipelines, deterministisch Funktionsaufruf und speed Parameter zur Sprachratensteuerung.
Kernfunktionssatz von GPT-4o Audio
• Einheitliche Sprachverarbeitung – Audio wird direkt in semantisch reichhaltige Token umgewandelt, analysiert und ohne externe STT/TTS-Dienste neu synthetisiert, was zu konsistente Stimmfarbe, Prosodie und Kontexterhaltung.
• Verbesserte Anweisungsbefolgung – Juni-2025 Tuning liefert +19 Punkte Pass-at-1 bei Sprachbefehlsaufgaben im Vergleich zum GPT-2024o-Basiswert vom Mai 4, wodurch Halluzinationen in Bereichen wie Kundensupport und Inhaltserstellung reduziert werden.
• Stabiler Werkzeugaufruf – Die Modellausgaben strukturiertes JSON Das entspricht dem Funktionsaufrufschema von OpenAI und ermöglicht die Auslösung von Backend-APIs (Suche, Buchung, Zahlungen) mit >95 % Argumentgenauigkeit.
• speed Parameter (0.25–4×) – Entwickler können die Sprachwiedergabe für langsames Lernen, normale Erzählung oder schnelle „Hör-Überfliegen“-Modi modulieren, ohne externe Neusynthese von Text.
• Unterbrechungsbewusstes Abwechseln – Obwohl die Vorschau nicht so latenzgesteuert ist wie die Echtzeitvariante, unterstützt sie Teilstreaming: Token werden ausgegeben, sobald sie berechnet sind, sodass Benutzer bei Bedarf frühzeitig unterbrechen können.
Technische Architektur von GPT-4o
• Single-Stack-Transformator – Wie alle GPT-4o-Derivate verwendet die Audiovorschau eine einheitlicher Encoder-Decoder wobei Text- und Akustik-Token identische Aufmerksamkeitsblöcke durchlaufen und so eine modalübergreifende Erdung fördern.
• Hierarchische Audio-Tokenisierung – Rohes 16 kHz PCM → Log-Mel-Patches → grobe akustische Codes → semantische TokenDiese mehrstufige Kompression erreicht 40–50-fache Bandbreitenreduzierung Unter Beibehaltung der Nuancen werden mehrminütige Clips pro Kontextfenster ermöglicht.
• NF4 Quantisierte Gewichte – Die Schlussfolgerung wird bei 4-Bit-Normal-Float Präzision, reduziert den GPU-Speicher im Vergleich zu fp16 um die Hälfte und erhält 70+ Streaming RTF (Echtzeitfaktor) auf A100-80 GB-Knoten.
• Streaming-Aufmerksamkeit und KV-Caching – Sliding-Window-Rotationseinbettungen bewahren den Kontext über ca. 30 Sekunden Sprache und behalten dabei O(L) Speichernutzung, ideal für Podcast-Editoren oder unterstützende Lesetools.
Versionierung und Benennung — Trackvorschau mit Builds mit Datumsstempel
| Identifizieren | Kanal | Zweck | Release Date | Stabilität |
|---|---|---|---|---|
| gpt-4o-Audio-Vorschau-2025-06-03 | Chat-Abschlüsse-API | Rundenbasierte Audiointeraktionen, Agentenaufgaben | 03 Juni 2025 | Vorschau (Feedback erwünscht) |
Wichtige Elemente des Namens:
- gpt-4o – Omni-multimodale Familie.
- Audio- – Optimiert für Sprachanwendungsfälle.
- Vorschau – Der API-Vertrag kann sich weiterentwickeln; noch nicht allgemein verfügbar.
- 2025-06-03 – Schulungs- und Bereitstellungs-Snapshot zur Reproduzierbarkeit.
So rufen Sie die GPT-4o Audio API API von CometAPI auf
GPT-4o Audio API API-Preise in CometAPI:
- Eingabe-Token: 2 $ / M Token
- Ausgabe-Token: 8 $ / M Token
Erforderliche Schritte
- Einloggen in cometapi.comWenn Sie noch nicht unser Benutzer sind, registrieren Sie sich bitte zuerst
- Holen Sie sich den API-Schlüssel für die Zugangsdaten der Schnittstelle. Klicken Sie im persönlichen Bereich beim API-Token auf „Token hinzufügen“, holen Sie sich den Token-Schlüssel: sk-xxxxx und senden Sie ihn ab.
- Holen Sie sich die URL dieser Site: https://api.cometapi.com/
Verwendungsmethoden
- Wählen Sie das "
gpt-4o-audio-preview-2025-06-03”-Endpunkt, um die Anfrage zu senden und den Anfragetext festzulegen. Die Anfragemethode und der Anfragetext stammen aus der API-Dokumentation unserer Website. Unsere Website bietet außerdem einen Apifox-Test für Ihre Bequemlichkeit. - Ersetzen mit Ihrem aktuellen CometAPI-Schlüssel aus Ihrem Konto.
- Geben Sie Ihre Frage oder Anfrage in das Inhaltsfeld ein – das Modell antwortet darauf.
- . Verarbeiten Sie die API-Antwort, um die generierte Antwort zu erhalten.
Informationen zum Modellzugriff in der Comet-API finden Sie unter API-Dokument.
Informationen zu Modellpreisen in der Comet-API finden Sie unter https://api.cometapi.com/pricing.
API-Workflow — Chat-Vervollständigungen mit Audioparts und Funktions-Hooks
- Eingabeformat -
audio/*MIME oderbase64WAV-Stücke eingebettet inmessages[].content. - Ausgabeoptionen -
•mode: "text"→ reiner Text zur Untertitelung.
•mode: "audio"→ gibt ein Streaming Opus- oder µ-Law-Nutzlast mit Zeitstempeln. - Funktionsaufruf - Hinzufügen
functions:Schema; das Modell gibt ausrole: "function"mit JSON-Argumenten; der Entwickler führt den Tool-Aufruf aus und leitet das Ergebnis optional zurück. - Rate Control - Einstellen
voice.speed=1.25zur Beschleunigung der Wiedergabe; sichere Bereiche 0.25–4.0. - Token-/Audio-Limits – 128 k Kontext (~4 Min. Rede) beim Start; 4096 Audio-Token / 8192 Text-Token je nachdem, was zuerst kommt.
Beispielcode und API-Integration
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Highlights:
- Modell:
"gpt-4o-audio-preview-2025-06-03" - Audio- Schlüssel in Benutzer Nachricht zum Senden des Binärstreams
- Geschwindigkeit: Bedienelemente Sprachrate zwischen langsam (0.5) und schnell (2.0)
- Temperatur: Guthaben Kreativität vs Konsistenz
Technische Indikatoren — Latenz, Qualität, Genauigkeit
| Metrisch | Audiovorschau | GPT-4o (Nur Text) | Delta |
|---|---|---|---|
| Latenz des ersten Tokens (1-Shot) | 1.2 s avg | 0.35 s | +0.85 s |
| MOS (Sprachnatürlichkeit, 5 Punkte) | 4.43 | - | - |
| Anweisungsbefolgung (Sprache) | 92% | 73% | +19 Seiten |
| Genauigkeit des Funktionsaufrufarguments | 95.8% | 87% | +8.8 Seiten |
| Wortfehlerrate (Implizite STT) | 5.2% | n/a | - |
| GPU-Speicher/Stream (A100-80 GB) | 7.1 GB | 14 GB (fp16) | −49 % |
Benchmarks wurden über Chat Completions-Streaming ausgeführt, Batchgröße = 1.
Siehe auch GPT-4o Echtzeit-API