

Stand vom 15. Dezember 2025 zeigen die öffentlichen Fakten, dass sowohl Google’s Gemini 3 Pro (Vorschau) als auch OpenAI’s GPT-5.2 neue Maßstäbe bei Reasoning, Multimodalität und Long-Context-Aufgaben setzen — jedoch unterschiedliche technische Wege gehen (Gemini → sparsames MoE + riesiger Kontext; GPT-5.2 → dichte/„Routing“-Designs, Kompaktion und x-high-Reasoning-Modi) und somit zwischen Spitzen-Benchmark-Siegen vs. technischer Vorhersagbarkeit, Tooling und Ökosystem abwägen. Welches „besser“ ist, hängt von Ihrem Hauptbedarf ab: extreme Kontextlängen und multimodale agentische Anwendungen tendieren zu Gemini 3 Pro; stabiles Enterprise-Entwicklertooling, vorhersehbare Kosten und sofortige API-Verfügbarkeit sprechen für GPT-5.2.
Was ist GPT-5.2 und was sind seine Hauptmerkmale?
GPT-5.2 ist OpenAI’s Release vom 11. Dezember 2025 in der GPT-5-Familie (Varianten: Instant, Thinking, Pro). Es ist als das leistungsfähigste Modell des Unternehmens für „professionelle Wissensarbeit“ positioniert — optimiert für Tabellen, Präsentationen, Long-Context-Reasoning, Tool-Calling, Code-Generierung und Vision-Aufgaben. OpenAI hat GPT-5.2 für zahlende ChatGPT-Nutzer und über die OpenAI-API (Responses API / Chat Completions) unter Modellnamen wie gpt-5.2, gpt-5.2-chat-latest und gpt-5.2-pro verfügbar gemacht.
Modellvarianten und Einsatzzwecke
- gpt-5.2 / GPT-5.2 (Thinking) — am besten für komplexes, mehrstufiges Reasoning (die Standardvariante der „Thinking“-Familie, die in der Responses API verwendet wird).
- gpt-5.2-chat-latest / Instant — geringere Latenz für tägliche Assistenz- und Chat-Nutzung.
- gpt-5.2-pro / Pro — höchste Treue/Zuverlässigkeit für schwierigste Probleme (zusätzliche Rechenleistung, unterstützt
reasoning_effort: "xhigh").
Zentrale technische Funktionen (nutzerseitig)
- Verbesserte Vision & Multimodalität — bessere räumliche Bild-Reasoning-Fähigkeiten und verbesserte Videounterstützung in Kombination mit Code-Tools (Python-Tool), plus Unterstützung für interpreterähnliche Tools zum Ausführen von Snippets.
- Konfigurierbarer Reasoning-Aufwand (
reasoning_effort: none|minimal|low|medium|high|xhigh), um Latenz/Kosten versus Tiefe zu steuern.xhighist neu bei GPT-5.2 (und auf Pro unterstützt). - Verbessertes Long-Context-Handling und Kompaktionsfunktionen, um über mehrere hunderttausend Tokens hinweg zu schlussfolgern (OpenAI berichtet starke MRCRv2-/Long-Context-Metriken).
- Erweitertes Tool-Calling & agentische Workflows — stärkere Mehr-Turn-Koordination, bessere Orchestrierung von Tools in einer „Single Mega-Agent“-Architektur (OpenAI hebt die Tool-Performance in Tau2-bench hervor).
Was ist Gemini 3 Pro Preview?
Gemini 3 Pro Preview ist Googles fortschrittlichstes generatives KI-Modell, veröffentlicht als Teil der breiteren Gemini-3-Familie im November 2025. Das Modell legt den Schwerpunkt auf multimodales Verständnis — es kann Text, Bilder, Video und Audio verstehen und synthetisieren — und bietet ein großes Kontextfenster (~1 Million Tokens) zur Verarbeitung umfangreicher Dokumente oder Codebasen.
Google positioniert Gemini 3 Pro als state of the art in Reasoning-Tiefe und Nuance und nutzt es als Kern-Engine für mehrere Entwickler- und Enterprise-Tools, darunter Google AI Studio, Vertex AI und agentische Entwicklungsplattformen wie Google Antigravity.
Derzeit ist Gemini 3 Pro in der Preview-Phase — das bedeutet, dass Funktionalität und Zugriff noch wachsen, aber das Modell bereits hohe Benchmarks in Logik, multimodalem Verständnis und agentischen Workflows erzielt.
Zentrale technische & Produktmerkmale
- Kontextfenster: Gemini 3 Pro Preview unterstützt ein Input-Kontextfenster mit 1.000.000 Tokens (und bis zu 64k Tokens Output), was in der Praxis ein großer Vorteil für das Einlesen extrem großer Dokumente, Bücher oder Videotranskripte in einer einzelnen Anfrage ist.
- API-Funktionen:
thinking_level-Parameter (low/high) zum Abwägen von Latenz und Reasoning-Tiefe;media_resolution-Einstellungen zur Steuerung der multimodalen Qualität und des Token-Verbrauchs; Search Grounding, Datei/URL-Kontext, Codeausführung und Function Calling werden unterstützt. Thought Signatures und Kontext-Caching helfen, den Zustand über Multi-Call-Workflows zu halten. - Deep Think Mode / höheres Reasoning: Eine „Deep Think“-Option ermöglicht einen zusätzlichen Reasoning-Durchlauf, um die Ergebnisse bei schwierigen Benchmarks zu steigern. Google veröffentlicht Deep Think als separaten Hochleistungs-Pfad für komplexe Probleme.;
- Native Multimodal-Unterstützung: Text-, Bild-, Audio- und Videoeingaben mit enger Verankerung in Search und Produktintegrationen (Video-MMMU-Scores und andere multimodale Benchmarks werden hervorgehoben).
Kurzübersicht — GPT-5.2 vs Gemini 3 Pro
Kompakte Vergleichstabelle mit den wichtigsten Fakten (Quellen zitiert).
| Aspekt | GPT-5.2 (OpenAI) | Gemini 3 Pro (Google / DeepMind) |
|---|---|---|
| Anbieter / Positionierung | OpenAI — Flaggschiff-Upgrade GPT-5.x, fokussiert auf professionelle Wissensarbeit, Coding und agentische Workflows. | Google DeepMind / Google AI — Flaggschiff der Gemini-Generation, fokussiert auf ultralanges, multimodales Reasoning und Tool-Integration. |
| Hauptvarianten | Instant, Thinking, Pro (und Auto-Switching zwischen ihnen). Pro bietet höheren Reasoning-Aufwand. | Gemini-3-Familie einschließlich Gemini 3 Pro und Deep-Think-Modi; Fokus auf Multimodalität/Agentik. |
| Kontextfenster (Input / Output) | ~400.000 Tokens Gesamteingabe; bis zu 128.000 Output-/Reasoning-Tokens (für sehr lange Dokumente & Codebasen ausgelegt). | Bis zu ~1.000.000 Tokens Input/Kontextfenster (1M) mit bis zu 64k Tokens Output |
| Kernstärken / Fokus | Long-Context-Reasoning, agentisches Tool-Calling, Coding, strukturierte Büroarbeit (Tabellen, Präsentationen); Sicherheits-/System-Card-Updates betonen Zuverlässigkeit. | Multimodales Verständnis im großen Maßstab, Reasoning + Bildkomposition, sehr großer Kontext + „Deep Think“-Modus, starke Tool-/Agent-Integrationen im Google-Ökosystem. |
| Multimodale & Bildfähigkeiten | Verbesserte Vision und multimodale Verankerung; abgestimmt auf Tool-Nutzung und Dokumentenanalyse. | Hochwertige Bildgenerierung + reasoning-gestützte Komposition, Multi-Referenz-Bildbearbeitung und gut lesbare Textrenderings. |
| Latenz / Interaktivität | Anbieter betont schnellere Inferenz und Prompt-Reaktionszeit (geringere Latenz als frühere GPT-5.x-Modelle); mehrere Tiers (Instant / Thinking / Pro). | Google betont optimiertes „Flash“/Serving und vergleichbare Interaktivität für viele Flows; Deep-Think-Modus tauscht Latenz gegen tieferes Reasoning. |
| Besondere Merkmale / Differenzierer | Reasoning-Aufwandsstufen (medium/high/xhigh), verbessertes Tool-Calling, hochwertige Code-Generierung, hohe Token-Effizienz für Enterprise-Workflows. | 1M-Token-Kontext, starke native multimodale Aufnahme (Video/Audio), „Deep Think“-Reasoning-Modus, enge Google-Produktintegrationen (Docs/Drive/NotebookLM). |
| Typische Best-Use-Cases (kurz) | Langdokument-Analyse, agentische Workflows, komplexe Coding-Projekte, Enterprise-Automation (Tabellen/Reports). | Extrem große multimodale Projekte, langhorizontale agentische Workflows mit 1M-Token-Kontext, fortgeschrittene Bild- + Reasoning-Pipelines. |
Wie vergleichen sich GPT-5.2 und Gemini 3 Pro architektonisch?
Kernarchitektur
- Benchmarks / Real-Work-Evals: GPT-5.2 Thinking erreichte 70,9 % Wins/Ties auf GDPval (44-Berufe-Evaluation für Wissensarbeit) und große Zuwächse bei Engineering- und Mathematik-Benchmarks gegenüber früheren GPT-5-Varianten. Deutliche Verbesserungen im Coding (SWE-Bench Pro) und in wissenschaftlichen Domänen-QA (GPQA Diamond).
- Tooling & Agenten: Tiefe Built-in-Unterstützung für Tool-Calling, Python-Ausführung und agentische Workflows (Dokumentensuche, Dateianalyse, Data-Science-Agenten). 11x schneller / <1 % der Kosten im Vergleich zu menschlichen Experten bei einigen GDPval-Aufgaben (Maß für potenziellen wirtschaftlichen Wert, 70,9 % vs. zuvor ~38,8 %) und konkrete Zugewinne im Spreadsheet-Modelling (z. B. +9,3 % bei einer Junior-Investmentbanking-Aufgabe vs. GPT-5.1).
- Gemini 3 Pro: Sparse Mixture-of-Experts Transformer (MoE). Das Modell aktiviert pro Token nur eine kleine Gruppe von Experten und ermöglicht dadurch extrem große Gesamt-Parameterkapazität bei sublinearer Per-Token-Rechenlast. Google gibt im Model Card an, dass das Sparse-MoE-Design wesentlich zur verbesserten Leistungscharakteristik beiträgt. Diese Architektur macht es möglich, die Modellkapazität stark zu erhöhen, ohne die Inferenzkosten linear steigen zu lassen.
- GPT-5.2 (OpenAI): OpenAI verwendet weiterhin Transformer-basierte Architekturen mit Routing-/Kompaktions-Strategien in der GPT-5-Familie (ein „Router“ triggert verschiedene Modi — Instant vs. Thinking — und das Unternehmen dokumentiert Kompaktion und Token-Management für lange Kontexte). GPT-5.2 betont Training und Evaluation, um „vor der Antwort zu denken“, sowie Kompaktion für langhorizontale Aufgaben, statt ein klassisches großskaliertes Sparse-MoE anzukündigen.
Auswirkungen der Architekturen
- Latenz- & Kosten-Trade-offs: MoE-Modelle wie Gemini 3 Pro können höhere Spitzenfähigkeit pro Token bieten, während die Inferenzkosten für viele Aufgaben niedrig bleiben, da nur ein Teil der Experten läuft. Sie können allerdings die Bereitstellung/Scheduling komplexer machen (Kaltstart-Expert-Balancing, I/O). Der Ansatz von GPT-5.2 (dicht/geroutet mit Kompaktion) begünstigt vorhersehbare Latenz und Entwickler-Ergonomie — besonders in den etablierten OpenAI-Tools wie Responses, Realtime, Assistants und Batch-APIs.
- Skalierung langer Kontexte: Geminis 1M-Input-Token-Fähigkeit erlaubt es, extrem lange Dokumente und multimodale Streams nativ zuzuführen. GPT-5.2’s ~400k kombinierter Kontext (Input+Output) ist immer noch enorm und deckt die meisten Enterprise-Bedürfnisse ab, ist jedoch kleiner als Geminis 1M-Spezifikation. Für sehr große Korpora oder mehrstündige Videotranskripte verschafft Geminis Spezifikation einen klaren technischen Vorteil.
Tooling, Agenten und multimodale Infrastruktur
- OpenAI: Tiefe Integration für Tool-Calling, Python-Ausführung, „Pro“-Reasoning-Modi und bezahlte Agenten-Ökosysteme (ChatGPT Agents / Enterprise-Tool-Integrationen). Starker Fokus auf codezentrierte Workflows sowie die Generierung von Tabellen und Folien als erstklassige Outputs.
- Google / Gemini: Eingebettetes Grounding zu Google Search (optional kostenpflichtig), Codeausführung, URL- und Dateikontext sowie explizite Medienauflösungsregler, um Tokens gegen visuelle Qualität zu tauschen. Die API bietet
thinking_levelund weitere Stellschrauben zur Feinjustierung von Kosten/Latenz/Qualität.
Wie vergleichen sich die Benchmark-Zahlen?
Kontextfenster und Token-Handling
- Gemini 3 Pro Preview: 1.000.000 Input-Tokens / 64k Output-Tokens (Pro-Preview-Model Card). Knowledge Cutoff: Januar 2025 (Google).
- GPT-5.2: OpenAI demonstriert starke Long-Context-Performance (MRCRv2-Scores über 4k–256k Needle-Tasks mit >85–95 % in vielen Settings) und nutzt Kompaktionsfunktionen; OpenAIs öffentliche Kontextexempel zeigen robuste Leistung auch bei sehr großen Kontexten, aber OpenAI listet variantspezifische Fenster (und betont Kompaktion statt einer einzelnen 1M-Zahl). Für die API-Nutzung lauten die Modellnamen
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-pro.
Reasoning- und agentische Benchmarks
- OpenAI (ausgewählt): Tau2-bench Telecom 98,7 % (GPT-5.2 Thinking), starke Zugewinne bei mehrstufiger Tool-Nutzung und agentischen Aufgaben (OpenAI betont das Kollabieren von Multi-Agent-Systemen in einen „Mega-Agenten“). GPQA Diamond und ARC-AGI zeigten Sprünge gegenüber GPT-5.1.
- Google (ausgewählt): Gemini 3 Pro: LMArena 1501 Elo, MMMU-Pro 81 %, Video-MMMU 87,6 %, hohe GPQA- und Humanity’s Last Exam-Werte; Google demonstriert zudem starkes Langzeit-Planning via agentischen Beispielen.
Tooling & Agenten:
GPT-5.2: Tiefe Built-in-Unterstützung für Tool-Calling, Python-Ausführung und agentische Workflows (Dokumentensuche, Dateianalyse, Data-Science-Agenten). 11x schneller / <1 % Kosten vs. menschliche Experten bei einigen GDPval-Aufgaben (Maß für potenziellen wirtschaftlichen Wert, 70,9 % vs. zuvor ~38,8 %) und konkrete Zugewinne im Spreadsheet-Modelling (z. B. +9,3 % bei einer Junior-Investmentbanking-Aufgabe vs. GPT-5.1).
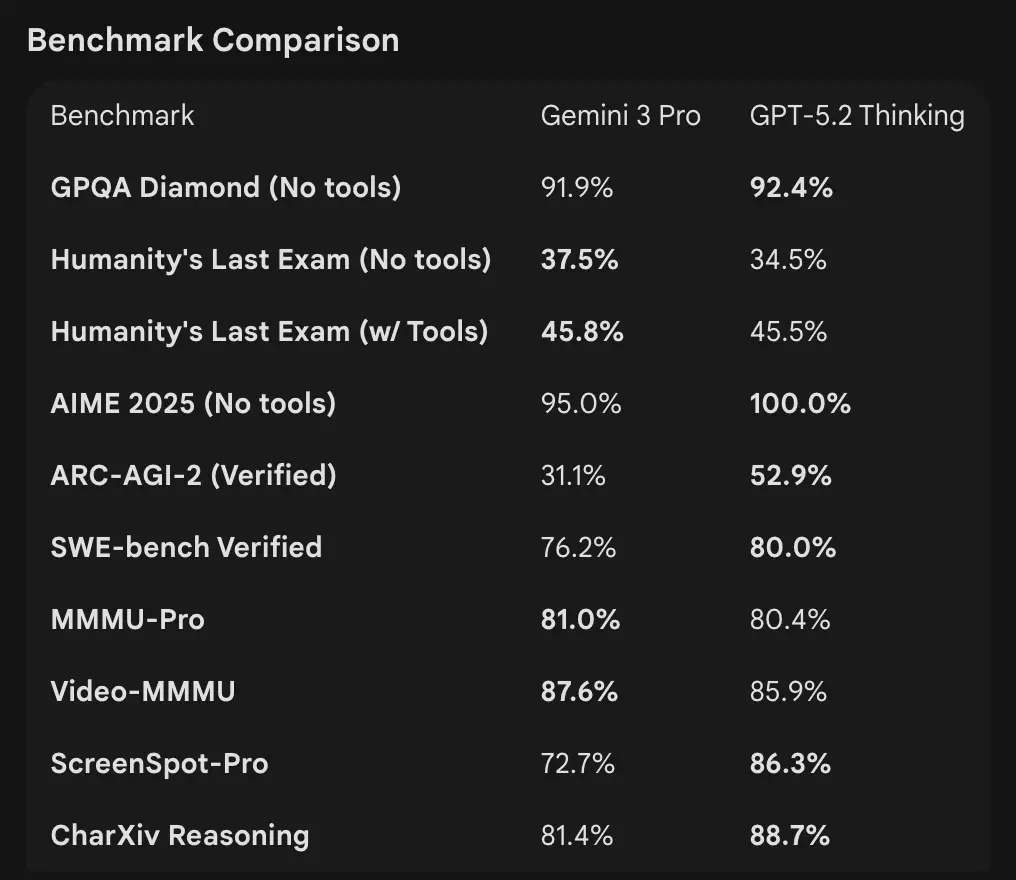
Interpretation: Die Benchmarks sind komplementär — OpenAI betont realweltliche Wissensarbeits-Benchmarks (GDPval), die zeigen, dass GPT-5.2 bei produktionsnahen Aufgaben wie Tabellen, Folien und langen agentischen Sequenzen glänzt. Google betont rohe Reasoning-Leaderboards und extrem große Kontextfenster für Einzelanfragen. Was wichtiger ist, hängt von Ihrer Workload ab: agentische, langdokumentige Enterprise-Pipelines profitieren von GPT-5.2’s nachgewiesener GDPval-Performance; die Aufnahme massiver Rohkontexte (z. B. ganze Videokorpora / vollständige Bücher in einem Durchlauf) profitiert von Geminis 1M-Inputfenster.
Wie vergleichen sich die multimodalen Fähigkeiten?
Inputs & Outputs
- Gemini 3 Pro Preview: unterstützt Text, Bild, Video, Audio, PDF als Eingaben und Textausgaben; Google bietet feingranulare
media_resolution-Regler und einenthinking_level-Parameter, um Kosten vs. Qualität für multimodale Arbeit zu steuern. Output-Token-Cap 64k; Input bis zu 1M Tokens. - GPT-5.2: unterstützt reichhaltige Vision- und Multimodal-Workflows; OpenAI hebt verbessertes räumliches Reasoning hervor (Bildkomponenten, begrenzungsbasierte Label-Schätzungen), Videoverständnis (Video-MMMU-Scores) und toolgestützte Vision (Python-Tool bei Vision-Aufgaben steigert die Scores). GPT-5.2 betont, dass komplexe Vision+Code-Aufgaben stark profitieren, wenn Tool-Unterstützung (Python-Codeausführung) aktiviert ist.
Praktische Unterschiede
Granularität vs. Breite: Gemini stellt eine Reihe multimodaler Stellschrauben bereit (media_resolution, thinking_level), mit denen Entwickler Trade-offs pro Medientyp feinjustieren können. GPT-5.2 betont die integrierte Tool-Nutzung (Python im Loop ausführen), um Vision-, Code- und Datentransformationsaufgaben zu kombinieren. Wenn Ihr Use Case stark auf Video- + Bildanalyse mit extrem großen Kontexten setzt, ist Geminis 1M-Kontext überzeugend; wenn Ihre Workflows Codeausführung im Loop benötigen (Daten-Transformationen, Tabellenerstellung), sind GPT-5.2’s Code-Tools und Agentenfreundlichkeit oft bequemer.
Wie steht es um API-Zugriff, SDKs und Preise?
OpenAI GPT-5.2 (API & Preise)
- API:
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-proüber Responses API / Chat Completions. Etablierte SDKs (Python/JS), Cookbook-Guides und ein reifes Ökosystem. - Preise (öffentlich): $1.75 / 1M Input-Tokens und $14 / 1M Output-Tokens; Caching-Rabatte (90 % für gecachte Inputs) senken die effektiven Kosten bei wiederholten Daten. OpenAI betont Token-Effizienz (höherer Preis pro Token, aber geringere Gesamtkosten bis zur Qualitätsgrenze).
Gemini 3 Pro Preview (API & Preise)
- API:
gemini-3-pro-previewüber das Google GenAI SDK sowie Vertex AI/GenerativeLanguage-Endpunkte. Neue Parameter (thinking_level,media_resolution) und Integration mit Google Groundings und Tools. - Preise (öffentliche Preview): Rund $2 / 1M Input-Tokens und $12 / 1M Output-Tokens für Preview-Tiers unter 200k Tokens; zusätzliche Gebühren können für Search Grounding, Maps oder andere Google-Dienste anfallen (Search-Grounding-Abrechnung ab 5. Jan. 2026).
GPT-5.2 und Gemini 3 über CometAPI verwenden
CometAPI ist ein Gateway-/Aggregator-API: ein einzelner, OpenAI-ähnlicher REST-API-Endpunkt, der Ihnen einheitlichen Zugriff auf Hunderte von Modellen vieler Anbieter ermöglicht (LLMs, Bild-/Video-Modelle, Embedding-Modelle usw.). Anstatt zahlreiche Anbieter-SDKs zu integrieren, erlaubt CometAPI Aufrufe in vertrauten OpenAI-Formaten (chat/completions/embeddings/images), während Modelle oder Anbieter unter der Haube gewechselt werden.
Entwickler können Flaggschiff-Modelle zweier unterschiedlicher Unternehmen gleichzeitig über CometAPI nutzen, ohne den Anbieter zu wechseln, und die API-Preise sind günstiger, meist mit 20% Rabatt.
Beispiel: schnelle API-Snippets (Copy-Paste zum Ausprobieren)
Nachfolgend minimalistische Beispiele zum Ausführen. Sie spiegeln die veröffentlichten Quickstarts der Anbieter wider (OpenAI Responses API + Google GenAI-Client). Ersetzen Sie $OPENAI_API_KEY / $GEMINI_API_KEY durch Ihre Schlüssel.
GPT-5.2 — Python (OpenAI Responses API, Reasoning auf xhigh für schwierige Probleme)
# Python (requires openai SDK that supports responses API)from openai import OpenAIclient = OpenAI(api_key="YOUR_OPENAI_API_KEY")resp = client.responses.create( model="gpt-5.2-pro", # gpt-5.2 or gpt-5.2-pro input="Summarize this 50k token company report and output a 10-slide presentation outline with speaker notes.", reasoning={"effort": "xhigh"}, # deeper reasoning max_output_tokens=4000)print(resp.output_text) # or inspect resp to get structured outputs / tokens
Hinweise: reasoning.effort ermöglicht den Tausch von Kosten vs. Tiefe. Verwenden Sie gpt-5.2-chat-latest für Instant-Chat-Stil. OpenAI-Dokumente zeigen Beispiele für responses.create.
GPT-5.2 — curl (einfach)
curl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5.2", "input": "Write a Python function that converts a PDF with tables into a normalized CSV with typed columns.", "reasoning": {"effort":"high"} }'
(Prüfen Sie das JSON auf output_text oder strukturierte Ausgaben.)
Gemini 3 Pro Preview — Python (Google GenAI-Client)
# Python (google genai client) — example from Google docsfrom google import genaiclient = genai.Client(api_key="YOUR_GEMINI_API_KEY")response = client.models.generate_content( model="gemini-3-pro-preview", contents="Find the race condition in this multi-threaded C++ snippet: <paste code here>", config={ "thinkingConfig": {"thinking_level": "high"} })print(response.text)
Hinweise: thinking_level steuert die interne Überlegung des Modells; media_resolution kann für Bilder/Videos gesetzt werden. REST- und JS-Beispiele finden sich im Gemini-Dev-Guide.;
Gemini 3 Pro — curl (REST)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Explain the race condition in this C++ code: ..."}] }], "generationConfig": {"thinkingConfig": {"thinkingLevel": "high"}} }'
Googles Dokumentation enthält multimodale Beispiele (eingebettete Bilddaten, media_resolution).
Welches Modell ist „besser“ — praktische Orientierung
Es gibt keinen universellen „Gewinner“; wählen Sie stattdessen anhand von Use Case und Randbedingungen. Nachfolgend eine kurze Entscheidungs-Matrix.
Wählen Sie GPT-5.2, wenn:
- Sie enge Integration mit Codeausführungs-Tools (OpenAI’s Interpreter-/Tool-Ökosystem) für programmatische Datenpipelines, Tabellenerstellung oder agentische Code-Workflows benötigen. OpenAI hebt Verbesserungen des Python-Tools und die Nutzung eines Mega-Agenten hervor.
- Sie Token-Effizienz gemäß Anbieterangaben priorisieren und explizite, vorhersehbare OpenAI-Preise pro Token mit hohen Rabatten auf gecachte Inputs wünschen (hilft bei Batch-/Produktions-Workflows).
- Sie das OpenAI-Ökosystem bevorzugen (ChatGPT-Produktintegration, Azure-/Microsoft-Partnerschaften und Tooling rund um Responses API und Codex).
Wählen Sie Gemini 3 Pro, wenn:
- Sie extreme multimodale Eingaben (Video + Bilder + Audio + PDFs) benötigen und ein einzelnes Modell möchten, das all diese Inputs nativ mit einem 1.000.000-Token-Inputfenster akzeptiert. Google vermarktet dies explizit für lange Videos, große Dokument- + Video-Pipelines und interaktive Search/AI-Mode-Use-Cases.
- Sie auf Google Cloud / Vertex AI bauen und enge Integration mit Google Search Grounding, Vertex-Bereitstellung und den GenAI-Client-APIs wünschen. Sie profitieren von Google-Produktintegrationen (Search AI Mode, AI Studio, Antigravity Agent-Tooling).
Fazit: Was ist 2026 „besser“?
Im GPT-5.2 vs. Gemini 3 Pro Preview-Vergleich lautet die Antwort: kontextabhängig:
- GPT-5.2 führt bei professioneller Wissensarbeit, analytischer Tiefe und strukturierten Workflows.
- Gemini 3 Pro Preview glänzt bei multimodalem Verständnis, integrierten Ökosystemen und Aufgaben mit sehr großem Kontext.
Keines der Modelle ist universell „besser“ — ihre Stärken bedienen unterschiedliche Anforderungen der Praxis. Kluge Anwender gleichen die Modellwahl mit konkreten Use Cases, Budgetrestriktionen und Ökosystem-Prioritäten ab.
Klar ist 2026, dass die KI-Frontier deutlich vorangeschritten ist und sowohl GPT-5.2 als auch Gemini 3 Pro die Grenzen dessen verschieben, was intelligente Systeme im Enterprise und darüber hinaus leisten können.
Wenn Sie sofort loslegen möchten, erkunden Sie die Fähigkeiten von GPT-5.2 und Gemini 3 Pro über CometAPI im Playground und konsultieren Sie den API-Guide für detaillierte Anleitungen. Bitte stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und einen API-Schlüssel erhalten haben. CometAPI bietet einen deutlich niedrigeren Preis als der offizielle, um Ihnen die Integration zu erleichtern.
Bereit? → Kostenloser Test von GPT-5.2 und Gemini 3 Pro !
If you want to