

OpenAI veröffentlichte eine Forschungsvorschau von gpt-oss-safeguard, eine Familie von Inferenzmodellen mit offenen Gewichtungen, die entwickelt wurde, um Entwicklern die Durchsetzung zu ermöglichen ihre eigenen Sicherheitsrichtlinien zur Inferenzzeit. Anstatt einen festen Klassifikator oder eine Black-Box-Moderations-Engine auszuliefern, werden die neuen Modelle feinabgestimmt auf Grund aus einer vom Entwickler bereitgestellten RichtlinieSie geben eine Gedankenkette (Chain-of-Thought, CoT) aus, die ihre Argumentation erläutert, und erzeugen strukturierte Klassifizierungsergebnisse. GPT-OSS-Safeguard, das als Forschungsvorschau angekündigt wurde, wird als ein Paar von Argumentationsmodellen vorgestellt.gpt-oss-safeguard-120b kombiniert mit einem nachhaltigen Materialprofil. gpt-oss-safeguard-20b—feinabgestimmt aus der gpt-oss-Familie und speziell für die Durchführung von Sicherheitsklassifizierungs- und Richtliniendurchsetzungsaufgaben während der Inferenz konzipiert.
Was ist gpt-oss-safeguard?
gpt-oss-safeguard ist ein Paar von Open-Weight-Modellen für reines textbasiertes Reasoning, die aus der gpt-oss-Familie nachtrainiert wurden. **Eine in natürlicher Sprache verfasste Richtlinie interpretieren und Texte entsprechend dieser Richtlinie kennzeichnen.**Das Unterscheidungsmerkmal ist, dass die Politik zum Zeitpunkt der Inferenz bereitgestellt (Richtlinien als Eingabe), nicht in statische Klassifikatorgewichte eingebettet. Die Modelle sind primär für Aufgaben der Sicherheitsklassifizierung konzipiert – z. B. Moderation mehrerer Richtlinien, Inhaltsklassifizierung über mehrere Regulierungsrahmen hinweg oder Überprüfung der Einhaltung von Richtlinien.
Warum das relevant ist
Herkömmliche Moderationssysteme basieren typischerweise auf (a) festen Regelsätzen, die auf mit annotierten Beispielen trainierte Klassifikatoren angewendet werden, oder (b) Heuristiken/regulären Ausdrücken zur Schlüsselworterkennung. gpt-oss-safeguard verfolgt einen Paradigmenwechsel: Anstatt Klassifikatoren bei jeder Richtlinienänderung neu zu trainieren, geben Sie einen Richtlinientext an (z. B. die Nutzungsrichtlinie Ihres Unternehmens, die Nutzungsbedingungen der Plattform oder eine behördliche Vorgabe). Das Modell analysiert dann, ob ein bestimmter Inhalt gegen diese Richtlinie verstößt. Dies verspricht Agilität (Richtlinienänderungen ohne erneutes Training) und Interpretierbarkeit (das Modell gibt seine Argumentationskette aus).
Dies ist ihre Kernphilosophie: „Auswendiglernen durch logisches Denken und Raten durch Erklärung ersetzen.“
Dies stellt eine neue Stufe in der Inhaltssicherheit dar, den Übergang vom „passiven Erlernen von Regeln“ zum „aktiven Verstehen von Regeln“.
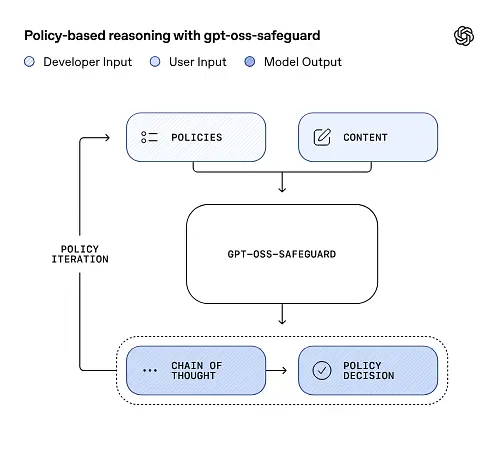
gpt-oss-safeguard kann die von den Entwicklern definierten Sicherheitsrichtlinien direkt lesen und diese Richtlinien befolgen, um während der Inferenz Entscheidungen zu treffen.
Wie funktioniert gpt-oss-safeguard?
Policy-as-input-Argumentation
Zum Zeitpunkt der Inferenz geben Sie zwei Dinge an: die Richtlinientext und der Kandidateninhalte Die Richtlinie wird als primäre Anweisung behandelt und anschließend schrittweise geprüft, ob der Inhalt zulässig, unzulässig oder für zusätzliche Moderationsmaßnahmen erforderlich ist. Bei der Inferenz gilt Folgendes:
- erzeugt eine strukturierte Ausgabe, die eine Schlussfolgerung (Bezeichnung, Kategorie, Konfidenz) und eine für Menschen lesbare Begründung enthält, die erklärt, warum diese Schlussfolgerung erreicht wurde.
- Nimmt die Richtlinie und die zu klassifizierenden Inhalte auf,
- geht intern die Klauseln der Richtlinie in Form von Gedankengängen durch, und
Beispielsweise:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Es wird antworten:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Gedankenkette (CoT) und strukturierte Ergebnisse
gpt-oss-safeguard kann im Rahmen jeder Inferenz einen vollständigen CoT-Trace ausgeben. Der CoT ist zur Überprüfung vorgesehen – Compliance-Teams können nachvollziehen, warum das Modell zu einem bestimmten Ergebnis gelangt ist, und Entwickler können den Trace nutzen, um Richtlinienunklarheiten oder Modellfehler zu diagnostizieren. Das Modell unterstützt außerdem strukturierte Ausgaben—zum Beispiel ein JSON-Objekt, das ein Urteil, die verletzten Richtlinienabschnitte, den Schweregrad und empfohlene Abhilfemaßnahmen enthält — wodurch die Integration in Moderationsprozesse unkompliziert wird.
Einstellbare Stufen des „Denkaufwands“
Um Latenz, Kosten und Gründlichkeit in Einklang zu bringen, unterstützen die Modelle einen konfigurierbaren Schlussfolgerungsaufwand: niedrig / mittel / hochHöherer Aufwand vertieft die Gedankengänge und führt im Allgemeinen zu robusteren, aber langsameren und kostspieligeren Schlussfolgerungen. Dies ermöglicht es Entwicklern, Arbeitslasten zu priorisieren – mit geringem Aufwand für Routineinhalte und mit hohem Aufwand für Sonderfälle oder risikoreiche Inhalte.
Wie ist die Modellstruktur und welche Versionen existieren?
Modellfamilie und Abstammung
gpt-oss-safeguard sind nach der Ausbildung Varianten der früheren OpenAI-Version gpt-oss Offene Modelle. Die Safeguard-Familie umfasst derzeit zwei Größen:
- gpt-oss-safeguard-120b — ein 120 Milliarden Parameter umfassendes Modell, das für hochpräzise Schlussfolgerungsaufgaben entwickelt wurde und dennoch auf einer einzelnen 80-GB-GPU in optimierten Laufzeiten läuft.
- gpt-oss-safeguard-20b — ein 20 Milliarden Parameter umfassendes Modell, optimiert für kostengünstigere Inferenz und Edge- oder On-Premise-Umgebungen (kann in einigen Konfigurationen auf Geräten mit 16 GB VRAM ausgeführt werden).
Architekturhinweise und Laufzeiteigenschaften (was zu erwarten ist)
- Aktive Parameter pro Token: Die zugrunde liegende gpt-oss-Architektur verwendet Techniken, die die Anzahl der pro Token aktivierten Parameter reduzieren (eine Mischung aus dichtem und spärlichem Aufmerksamkeits-/Mixture-of-Experts-Design im übergeordneten gpt-oss).
- Praktisch gesehen passt die 120B-Klasse auf einzelne große Beschleuniger, und die 20B-Klasse ist für den Betrieb auf 16GB VRAM-Systemen in optimierten Laufzeiten ausgelegt.
Schutzmodelle waren nicht mit zusätzlichen biologischen oder Cybersicherheitsdaten geschultDie für die GPT-OSS-Version durchgeführten Analysen von Worst-Case-Missbrauchsszenarien lassen sich im Wesentlichen auch auf die Schutzvarianten übertragen. Die Modelle dienen der Klassifizierung und nicht der Inhaltsgenerierung für Endnutzer.
Was sind die Ziele von gpt-oss-safeguard?
Ziele
- Politische Flexibilität: Entwickler können beliebige Richtlinien in natürlicher Sprache definieren und das Modell kann diese ohne benutzerdefinierte Labelerfassung anwenden.
- Erklärbarkeit: Die Begründungen werden offengelegt, damit Entscheidungen überprüft und Richtlinien wiederholt werden können.
- Einfache Anwendung: Wir bieten eine Alternative mit offenem Gewicht an, damit Organisationen Sicherheitsüberprüfungen lokal durchführen und die internen Abläufe des Modells untersuchen können.
Vergleich mit klassischen Klassifikatoren
Vorteile gegenüber traditionellen Klassifikatoren
- Keine Umschulung bei Richtlinienänderungen: Wenn sich Ihre Moderationsrichtlinie ändert, aktualisieren Sie das Richtliniendokument, anstatt Labels zu sammeln und einen Klassifikator neu zu trainieren.
- Ausführlichere Argumentation: Die Ergebnisse von CoT können subtile Wechselwirkungen zwischen politischen Maßnahmen aufzeigen und eine narrative Begründung liefern, die für menschliche Gutachter nützlich ist.
- Anpassbarkeit: Ein einzelnes Modell kann während der Inferenz viele verschiedene Strategien gleichzeitig anwenden.
Nachteile gegenüber traditionellen Klassifikatoren
- Leistungsgrenzen für einige Aufgaben: OpenAI stellt in seiner Bewertung fest, dass Hochwertige Klassifikatoren, die mit Zehntausenden von gelabelten Beispielen trainiert wurden, können gpt-oss-safeguard übertreffen. Bei speziellen Klassifizierungsaufgaben. Wenn es um die reine Klassifizierungsgenauigkeit geht und Sie über gelabelte Daten verfügen, kann ein speziell auf diese Verteilung trainierter Klassifikator besser geeignet sein.
- Latenz und Kosten: Die Argumentation mit CoT ist rechenintensiv und langsamer als ein ressourcenschonender Klassifikator; dies kann rein auf Schutzmechanismen basierende Pipelines bei großem Umfang teuer machen.
Kurz gesagt: gpt-oss-safeguard eignet sich am besten für folgende Anwendungsfälle: Politische Agilität und Prüfbarkeit sind Prioritäten oder wenn gekennzeichnete Daten knapp sind – und als ergänzende Komponente in hybriden Pipelines, nicht unbedingt als direkter Ersatz für einen skalierungsoptimierten Klassifikator.
Wie schnitt gpt-oss-safeguard in den Evaluierungen von OpenAI ab?
OpenAI veröffentlichte erste Ergebnisse in einem 10-seitigen technischen Bericht, der interne und externe Evaluierungen zusammenfasst. Wichtigste Erkenntnisse (ausgewählte, relevante Kennzahlen):
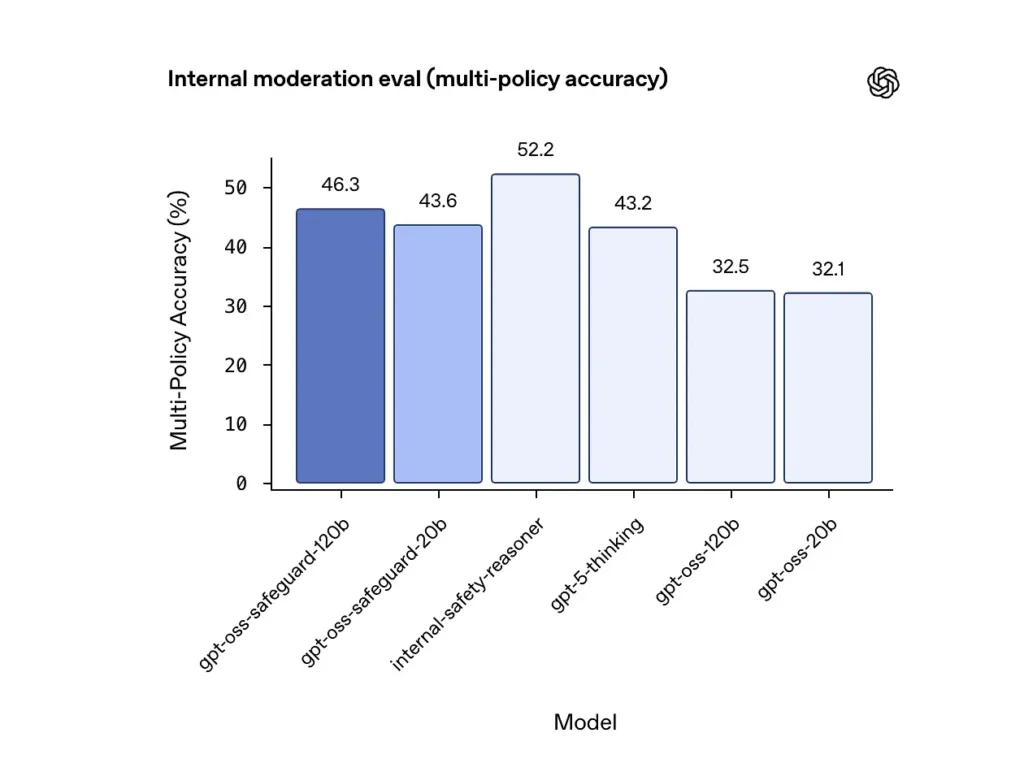
Genauigkeit mehrerer Richtlinien (interne Evaluierung)
OpenAI bewertete die Genauigkeit mehrerer Richtlinien, indem es das Modell verwendete. mehrere Richtlinien gleichzeitig anwenden und eine Vorhersage nur dann als richtig zählen, wenn sie mit den goldenen Labels übereinstimmt. alle Richtlinien. Ergebnisse:
- gpt-oss-safeguard-120b: 46.3% Genauigkeit mehrerer Richtlinien
- gpt-oss-safeguard-20b: 43.6%
- Zum Vergleich: gpt-5-Denken: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
Das interne „Safety-Reasoner“-Ensemble von OpenAI erzielte im selben Test 52.2 %. Diese Zahlen belegen, dass die Safeguard-Modelle ihre gpt-oss-Basismodelle bei der Multi-Policy-Aufgabe deutlich übertreffen und sogar die umfassendere gpt-5-Thinking-Baseline in der internen Multi-Policy-Metrik übertreffen.
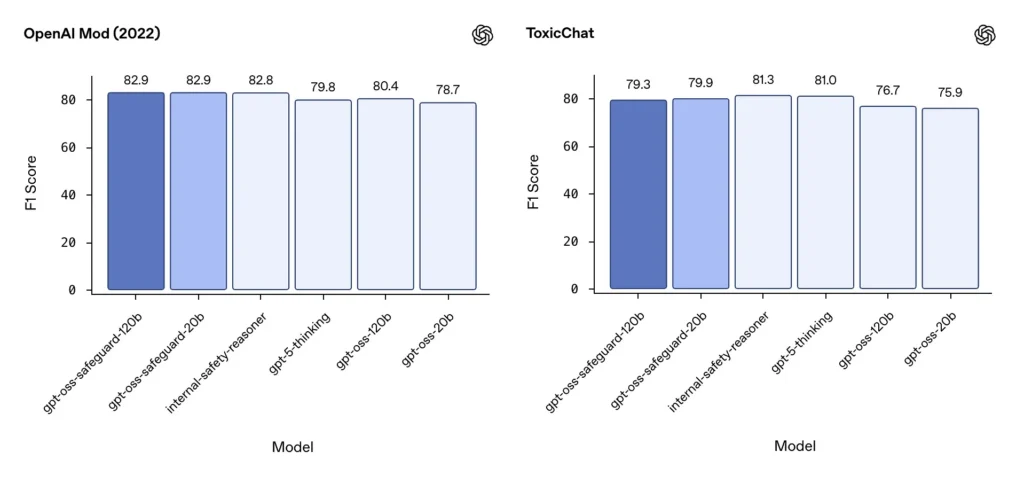
Moderation F1 (externe Benchmarks)
Auf dem Moderationsdatensatz von OpenAI aus dem Jahr 2022 und dem öffentlichen ToxicChat-Benchmark erzielten die gpt-oss-safeguard-Modelle solide F1-Werte:
- OpenAI Mod (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Diese Ergebnisse platzieren gpt-oss-safeguard bei einigen Benchmarks nahe oder leicht hinter spezialisierten internen OpenAI-Systemen und im Allgemeinen vor den nicht feinabgestimmten gpt-oss-Pendants.
Festgestellte Einschränkungen
OpenAI weist auf zwei praktische Einschränkungen hin:
- Klassifikatoren, die auf großen, aufgabenspezifischen, gelabelten Datensätzen trainiert wurden, können Schutzmodellen immer noch überlegen sein. wenn die Genauigkeit der Klassifizierung das einzige Ziel ist.
- Rechen- und Latenzkosten: Die CoT-Schlussfolgerung erhöht die Inferenzzeit und den Rechenaufwand, was die Skalierung auf Plattformebene erschwert, sofern sie nicht mit Triage-Klassifikatoren und asynchronen Pipelines kombiniert wird.
Mehrsprachigkeit
gpt-oss-safeguard erzielt in Tests im MMMLU-Stil über viele Sprachen hinweg eine vergleichbare Leistung wie die zugrunde liegenden gpt-oss-Modelle, was darauf hindeutet, dass die feinabgestimmten Schutzvarianten ihre umfassende Argumentationsfähigkeit beibehalten.
Wie können Teams auf gpt-oss-safeguard zugreifen und es einsetzen?
OpenAI stellt die Gewichte unter der Apache-2.0-Lizenz bereit und verlinkt die Modelle zum Download (Hugging Face). Da gpt-oss-safeguard ein Open-Weight-Modell ist, empfiehlt sich eine lokale und selbstverwaltete Bereitstellung (aus Gründen des Datenschutzes und der Anpassungsmöglichkeiten).
- Modellgewichte herunterladen (von OpenAI / Hugging Face) und hosten Sie sie auf Ihren eigenen Servern oder Cloud-VMs. Apache 2.0 erlaubt Modifikation und kommerzielle Nutzung.
- LaufzeitVerwenden Sie Standard-Inferenzlaufzeitumgebungen, die große Transformer-Modelle unterstützen (ONNX Runtime, Triton oder optimierte Laufzeitumgebungen von Drittanbietern). Community-Laufzeitumgebungen wie Ollama und LM Studio bieten bereits Unterstützung für gpt-oss-Familien.
- Hardware120B benötigt typischerweise GPUs mit hohem Speicher (z. B. 80 GB A100/H100 oder Multi-GPU-Sharding), während 20B kostengünstiger betrieben werden kann und Optionen bietet, die für 16-GB-VRAM-Konfigurationen optimiert sind. Planen Sie die Kapazität für maximalen Durchsatz und die Kosten der Multi-Policy-Auswertung ein.
Verwaltete und Drittanbieter-Laufzeitumgebungen
Wenn der Betrieb eigener Hardware unpraktisch ist, CometAPI Die Unterstützung für GPT-OSS-Modelle wird rasch ausgebaut. Diese Plattformen ermöglichen zwar eine einfachere Skalierung, bringen aber erneut Risiken hinsichtlich der Datenweitergabe an Dritte mit sich. Prüfen Sie Datenschutz, SLAs und Zugriffskontrollen sorgfältig, bevor Sie sich für verwaltete Laufzeitumgebungen entscheiden.
Effektive Moderationsstrategien mit gpt-oss-safeguard
1) Nutzen Sie eine hybride Pipeline (Triage → Begründung → Entscheidung)
- Triage-Ebene: Kleine, schnelle Klassifikatoren (oder Regeln) filtern triviale Fälle heraus. Dies reduziert die Belastung des aufwändigen Schutzmodells.
- Schutzschicht: Führen Sie gpt-oss-safeguard für mehrdeutige, risikoreiche oder mehrere Richtlinien betreffende Prüfungen aus, bei denen es auf die Nuancen der Richtlinien ankommt.
- Menschliche Beurteilung: Sonderfälle und Beschwerden werden eskaliert, wobei CoT als Nachweis für Transparenz gespeichert wird. Dieses hybride Design gewährleistet ein ausgewogenes Verhältnis zwischen Durchsatz und Präzision.
2) Politikgestaltung (nicht Promptgestaltung)
- Behandeln Sie Richtlinien wie Softwareartefakte: Versionieren Sie sie, testen Sie sie anhand von Datensätzen und halten Sie sie explizit und hierarchisch.
- Verfassen Sie Richtlinien mit Beispielen und Gegenbeispielen. Fügen Sie nach Möglichkeit eindeutige Anweisungen hinzu (z. B. „Wenn die Absicht des Nutzers eindeutig explorativ und historisch ist, kennzeichnen Sie sie mit X; wenn die Absicht operativ und in Echtzeit ist, kennzeichnen Sie sie mit Y“).
3) Den Denkaufwand dynamisch konfigurieren
- Nutzen Sie geringer Aufwand für die Massenverarbeitung und hoher Aufwand für gekennzeichnete Inhalte, Einsprüche oder besonders relevante Branchen (Recht, Medizin, Finanzen).
- Durch die Abstimmung der Schwellenwerte mithilfe von Feedback aus der menschlichen Bewertungsgruppe lässt sich das optimale Kosten-Nutzen-Verhältnis ermitteln.
4) Überprüfen Sie die CoT und achten Sie auf halluzinatorisches Denken.
Die CoT ist zwar wertvoll, kann aber zu Fehlinterpretationen führen: Die generierte Begründung ist nicht die tatsächliche Wahrheit. Überprüfen Sie die CoT-Ausgaben regelmäßig und setzen Sie Mechanismen ein, um fehlerhafte Zitate oder unpassende Schlussfolgerungen aufzuspüren. OpenAI dokumentiert fehlerhafte Gedankengänge als bekannte Herausforderung und schlägt Gegenmaßnahmen vor.
5) Datensätze aus dem Systembetrieb erstellen
Modellentscheidungen und menschliche Korrekturen werden protokolliert, um annotierte Datensätze zu erstellen, die Triage-Klassifikatoren verbessern oder Richtlinienüberarbeitungen unterstützen können. Mit der Zeit reduziert ein kleiner, qualitativ hochwertiger annotierter Datensatz in Kombination mit einem effizienten Klassifikator häufig die Abhängigkeit von vollständigen CoT-Inferenzverfahren für Routineinhalte.
6) Rechenleistung und Kosten überwachen; asynchrone Datenflüsse einsetzen
Für kundenorientierte Anwendungen mit geringen Latenzanforderungen empfiehlt es sich, asynchrone Sicherheitsprüfungen mit einer kurzfristig konservativen Benutzerführung (z. B. vorübergehendes Ausblenden von Inhalten bis zur Überprüfung) anstelle einer aufwändigen synchronen CoT-Prüfung durchzuführen. OpenAI weist darauf hin, dass Safety Reasoner intern asynchrone Abläufe nutzt, um die Latenz für Produktionsdienste zu minimieren.
7) Datenschutz und Einsatzort berücksichtigen
Da die Gewichte offen sind, können Sie die Inferenz vollständig lokal durchführen, um strenge Datenrichtlinien einzuhalten oder die Abhängigkeit von APIs Dritter zu reduzieren – ein wertvoller Vorteil für regulierte Branchen.
Fazit:
gpt-oss-safeguard ist ein praktisches, transparentes und flexibles Werkzeug für Richtliniengeleitete SicherheitsbegründungEs glänzt, wenn man es braucht. Prüfbare Entscheidungen, die an explizite Richtlinien gebunden sindwenn sich Ihre Richtlinien häufig ändern oder wenn Sie Sicherheitsüberprüfungen vor Ort durchführen möchten. kein Frontalunterricht. Eine Patentlösung, die spezialisierte, auf hohe Datenmengen ausgelegte Klassifikatoren automatisch ersetzt, ist nicht gegeben. OpenAIs eigene Evaluierungen zeigen jedoch, dass dedizierte Klassifikatoren, die mit großen, annotierten Korpora trainiert wurden, diese Modelle hinsichtlich der Rohgenauigkeit bei eng begrenzten Aufgaben übertreffen können. Betrachten Sie gpt-oss-safeguard stattdessen als strategische Komponente: die erklärbare Argumentationsmaschine im Zentrum einer mehrschichtigen Sicherheitsarchitektur (schnelle Triage → erklärbare Argumentation → menschliche Überwachung).
Erste Schritte
CometAPI ist eine einheitliche API-Plattform, die über 500 KI-Modelle führender Anbieter – wie die GPT-Reihe von OpenAI, Gemini von Google, Claude von Anthropic, Midjourney, Suno und weitere – in einer einzigen, entwicklerfreundlichen Oberfläche vereint. Durch konsistente Authentifizierung, Anforderungsformatierung und Antwortverarbeitung vereinfacht CometAPI die Integration von KI-Funktionen in Ihre Anwendungen erheblich. Ob Sie Chatbots, Bildgeneratoren, Musikkomponisten oder datengesteuerte Analyse-Pipelines entwickeln – CometAPI ermöglicht Ihnen schnellere Iterationen, Kostenkontrolle und Herstellerunabhängigkeit – und gleichzeitig die neuesten Erkenntnisse des KI-Ökosystems zu nutzen.
Die neueste Integration gpt-oss-safeguard wird in Kürze auf CometAPI verfügbar sein, also bleiben Sie gespannt! Während wir den Upload des gpt-oss-safeguard-Modells abschließen, können Entwickler darauf zugreifen. GPT-OSS-20B-API kombiniert mit einem nachhaltigen Materialprofil. GPT-OSS-120B-API über CometAPI, die neuste Modellversion wird immer mit der offiziellen Website aktualisiert. Erkunden Sie zunächst die Fähigkeiten des Modells in der Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bieten einen Preis weit unter dem offiziellen Preis an, um Ihnen bei der Integration zu helfen.
Bereit loszulegen? → Melden Sie sich noch heute für CometAPI an !
Wenn Sie weitere Tipps, Anleitungen und Neuigkeiten zu KI erfahren möchten, folgen Sie uns auf VK, X kombiniert mit einem nachhaltigen Materialprofil. Discord!