

xAI angekündigt Grok 4 Fast, eine kostenoptimierte Variante der Grok-Familie, die laut Angaben des Unternehmens eine Leistung liefert, die dem Spitzenmodell nahekommt, und gleichzeitig den Preis senkt, um diese Leistung zu erreichen, indem 98% im Vergleich zu Grok 4. Das neue Modell ist für die Hochdurchsatzsuche und die Verwendung von Agententools konzipiert und umfasst ein Kontextfenster mit 2 Millionen Token sowie separate Varianten mit „Argumentation“ und „ohne Argumentation“, damit Entwickler die Berechnung an ihre Anforderungen anpassen können.
Kernfunktionen und Vorteile
Kostengünstiges Inferenzmodell: Grok 4 Fast basiert auf der Grok 4-Familie und konzentriert sich auf Token-Effizienz und Echtzeit-Tool-Nutzung. xAI berichtet, dass das Modell etwa 40 % weniger „Denk“-Token im Durchschnitt. Künstliche Analysen, die Latenz, Ausgabegeschwindigkeit und Preis-Leistungs-Verhältnis vieler öffentlicher Modelle verfolgen, platzieren Grok 4 Fast weit oben auf der Intelligenz-Kosten-Grenze und bestätigen die schnellen Ausgabegeschwindigkeiten und das günstige Kostenverhältnis des Modells in frühen Tests.
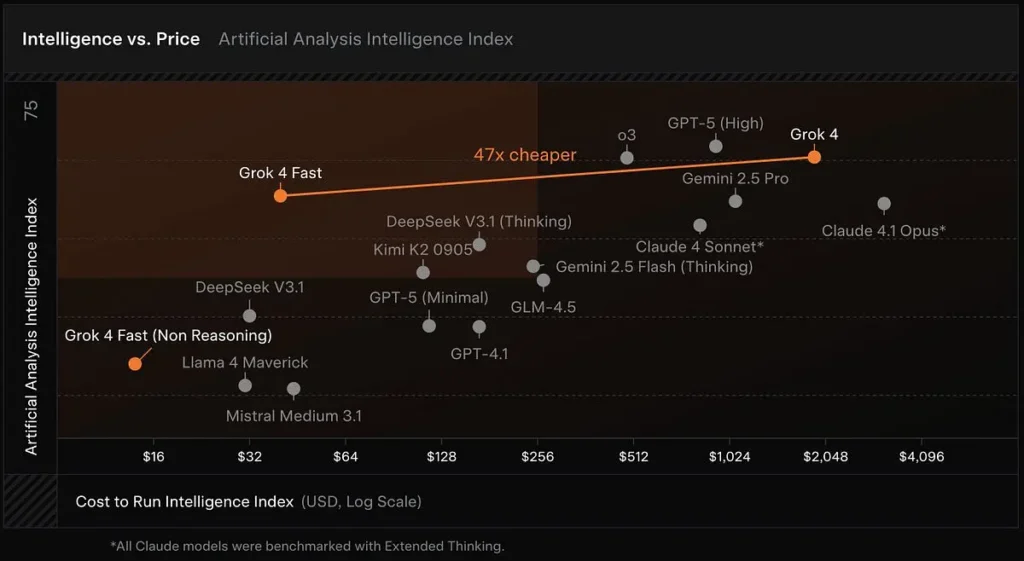
Große Kontextfenster: Grok 4 Fast ist für die Verwendung von Such- und Agententools mit hohem Durchsatz konzipiert und umfasst ein Kontextfenster mit 2 Millionen Token sowie separate Varianten mit und ohne Argumentation, damit Entwickler die Berechnung an ihre Anforderungen anpassen können.
Native Tool-Nutzungsfunktionen: Grok 4 Fast bietet „hochmoderne Web- und X-Suchfunktionen“, die das Abrufen, Navigieren und Zusammenfassen von Webinhalten während agentenbasierter Arbeitsabläufe verbessern. Damit positioniert sich Grok 4 Fast als praktisches Suchtool für Anwendungen, die das Sammeln und Schlussfolgern von Informationen in Echtzeit über lange Dokumente hinweg erfordern. Es weist führende Leistungen bei mehreren Suchbenchmarks auf, darunter:
- BrowseComp (zh): 51.2 % (vs. Grok 4 45.0 %)
- X Bench Deepsearch (zh): 74.0 % (vs. Grok 4 66.0 %)
Einheitliche Architektur: Dasselbe Modell unterstützt sowohl Inferenz- als auch Nicht-Inferenzmodi, sodass kein separater Modellwechsel erforderlich ist. Dank der reduzierten Latenz und Kosten eignet es sich für Echtzeitanwendungen (wie Suche, Beantwortung von Fragen und Forschungsunterstützung).
Leistungsvergleich (wichtigste Benchmarks)
In privaten LMArena-Tests, die xAI teilte, grok-4-fast-search (Codename menlo) Variante führt die Search Arena mit einer Elo-Bewertung von 1,163, während die Textvariante (tahoe) befindet sich in den Top Ten der Text Arena – Ergebnisse, die xAI zur Untermauerung seiner Behauptungen zur Suchleistung verwendet.
Grok 4 Fast erreicht bei mehreren bahnbrechenden Benchmarks (z. B. GPQA Diamond, AIME 2025 und HMMT 2025) die Leistung von Grok 4 oder liegt knapp dahinter, während es bei Denkaufgaben frühere kleinere Modelle übertrifft – ein Beweis, den xAI zur Untermauerung der Behauptung einer „vergleichbaren Leistung“ heranzieht.
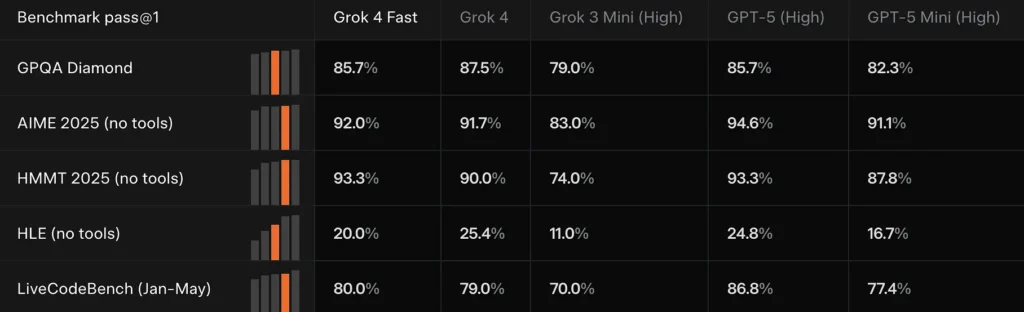
Ergebnisse vergleichen
Im Vergleich zu Grok 4: Günstiger und weniger rechenintensiv, aber mit ähnlicher Leistung.
Im Vergleich zu Grok 3 Mini: Leistungsstärker, ermöglicht komplexe Schlussfolgerungen und Echtzeitsuche.
Im Vergleich zu GPT-5/Gemini/Claude: Dank seiner extrem hohen Token-Effizienz und Tooling-Fähigkeiten ist es in puncto Kosteneffizienz und einigen Suchaufgaben führend.
Preise & Verfügbarkeit
Kontext und Token: Zwei Modellvarianten: grok-4-fast-reasoning kombiniert mit einem nachhaltigen Materialprofil. grok-4-fast-non-reasoning, jeweils mit 2M Kontext.
Veröffentlichte (Listen-)Preise im Startbeitrag (Beispielstufen):
- Eingabetoken: 0.20 $ / 1 Mio. (<128k) — 0.40 $ / 1 Mio. (≥128k)
- Ausgabetoken: 0.50 $ / 1 Mio. (<128k) — 1.00 $ / 1 Mio. (≥128k)
- Zwischengespeicherte Eingabetoken: 0.05 $ / 1 Mio..
(Genaue Abrechnungsregeln und zeitlich begrenzte Werbeaktionen finden Sie in der xAI-Ankündigung.)
Verfügbarkeit des Anbieters: xAI listet die kurzfristige kostenlose Verfügbarkeit über OpenRouter und Vercel AI Gateway und die allgemeine Verfügbarkeit über die API von xAI auf.
Was das für Benutzer und Teams bedeutet
- Große Kosteneinsparungen für den Produktionseinsatz – Die Kombination aus niedrigeren Preisen pro Token und weniger „Denktoken“ bedeutet, dass Teams mehr Abfragen oder Workflows mit größerem Kontext zu einem Bruchteil der Kosten von Grok 4 ausführen können, was die Hürden für Experimente und skalierte Bereitstellungen deutlich senkt. (Behauptung gestützt durch xAI-Kosten-/Leistungsangaben und Kostenanalysen von Drittanbietern.)
- Funktioniert mit sehr langen Dokumenten und mehrstufiger Argumentation – 2M-Token ermöglichen die praktische Aufnahme ganzer Bücher, großer Codebasen oder langer juristischer/technischer Dossiers in einer einzigen Sitzung. Dies verbessert die Genauigkeit und Kohärenz bei Aufgaben, die einen weitreichenden Kontext erfordern (Dokumentensuche, Zusammenfassung, Generierung von Langformcode, Forschungsassistenten).
- Schnellere Ausgaben mit geringerer Latenz für interaktive Anwendungen – Als „Fast“-Variante ist sie auf einen schnelleren Token-Durchsatz und geringere Latenz ausgelegt, was Chat-UIs, Programmierassistenten und Echtzeit-Agentenschleifen zugutekommt, bei denen es auf Reaktionsfähigkeit ankommt. (Künstliche Analysen und Anbieter-Benchmarks betonen die Ausgabegeschwindigkeit als Unterscheidungsmerkmal.)
- Gutes Preis-Leistungs-Verhältnis für Benchmark-Reasoning-Aufgaben – Für Teams, die Modelle anhand bahnbrechender akademischer Benchmarks beurteilen, bietet Grok 4 Fast einen starken Kompromiss: nahezu grenzenlose Genauigkeit zu drastisch geringeren Kosten, was es für Forschungslabore und Unternehmen attraktiv macht, die häufig teure Benchmark-Suiten ausführen.
Fazit:
Grok 4 Fast positioniert xAI wettbewerbsfähig hinsichtlich Preis-Leistungs-Verhältnis und für suchzentrierte Agentenanwendungen. Sollten die Effizienz- und Verifizierungsansprüche des Unternehmens in unabhängigen, domänenspezifischen Tests Bestand haben, könnte Grok 4 Fast die Kostenerwartungen für leistungsstarke, toolgestützte LLM-Implementierungen neu gestalten – insbesondere für Anwendungen, die auf Live-Web-Retrieval und mehrstufiger Tool-Nutzung basieren.
Erste Schritte
CometAPI ist eine einheitliche API-Plattform, die über 500 KI-Modelle führender Anbieter – wie die GPT-Reihe von OpenAI, Gemini von Google, Claude von Anthropic, Midjourney, Suno und weitere – in einer einzigen, entwicklerfreundlichen Oberfläche vereint. Durch konsistente Authentifizierung, Anforderungsformatierung und Antwortverarbeitung vereinfacht CometAPI die Integration von KI-Funktionen in Ihre Anwendungen erheblich. Ob Sie Chatbots, Bildgeneratoren, Musikkomponisten oder datengesteuerte Analyse-Pipelines entwickeln – CometAPI ermöglicht Ihnen schnellere Iterationen, Kostenkontrolle und Herstellerunabhängigkeit – und gleichzeitig die neuesten Erkenntnisse des KI-Ökosystems zu nutzen.
Entwickler können zugreifen Grok-4-fast ( Modell: grok-4-fast-reasoning” / “grok-4-fast-reasoning) über CometAPI, die neuste Modellversion wird immer mit der offiziellen Website aktualisiert. Erkunden Sie zunächst die Fähigkeiten des Modells in der Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bieten einen Preis weit unter dem offiziellen Preis an, um Ihnen bei der Integration zu helfen.
Bereit loszulegen? → Melden Sie sich noch heute für CometAPI an !