
Grok-Code-Fast-1 ist xAIs geschwindigkeitsorientiertes, kosteneffizientes agentisches Codierungsmodell Entwickelt für IDE-Integrationen und automatisierte Kodieragenten. Es betont Low Latency, agentisches Verhalten (Toolaufrufe, schrittweise Schlussfolgerungsspuren) und ein kompaktes Kostenprofil für alltägliche Entwickler-Workflows.
Wichtige Funktionen (auf einen Blick)
- Hoher Durchsatz / geringe Latenz: konzentriert sich auf sehr schnelle Token-Ausgabe und schnelle Vervollständigungen für die IDE-Nutzung.
- Agentischer Funktionsaufruf und Tools: unterstützt Funktionsaufrufe und die Orchestrierung externer Tools (Tests ausführen, Linter, Dateiabruf), um mehrstufige Codieragenten zu ermöglichen.
- Großes Kontextfenster: Entwickelt für die Verarbeitung großer Codebasen und Kontexte mit mehreren Dateien (Anbieter listen 256 Kontextfenster in Marktplatzadaptern auf).
- Sichtbare Begründungen/Spuren: Antworten können schrittweise Argumentationsspuren enthalten, die dazu dienen, Agentenentscheidungen überprüfbar und debuggbar zu machen.
Technische Details
Architektur & Ausbildung: Laut xAI wurde grok-code-fast-1 von Grund auf mit einer neuen Architektur und einem vorab trainierten Korpus mit umfangreichen Programmierinhalten entwickelt. Das Modell wurde anschließend anhand hochwertiger, realer Pull-Request-/Code-Datensätze kuratiert. Diese Engineering-Pipeline zielt darauf ab, das Modell praktische Einblicke in Agenten-Workflows (IDE + Tool-Nutzung).
Servieren & Kontext: grok-code-fast-1 und typische Nutzungsmuster gehen von Streaming-Ausgaben, Funktionsaufrufen und Rich Context Injection (Datei-Uploads/-Sammlungen) aus. Mehrere Cloud-Marktplätze und Plattformadapter listen es bereits mit Unterstützung für große Kontexte (256 Kontexte in einigen Adaptern).
Benutzerfreundlichkeitsfunktionen: Sichtbar Argumentationsspuren (Das Modell zeigt seine Planung/Tool-Nutzung), schnelle technische Anleitungen und Beispielintegrationen sowie frühe Partnerintegrationen (z. B. GitHub Copilot, Cursor).
Benchmark-Leistung (wobei es punktet)
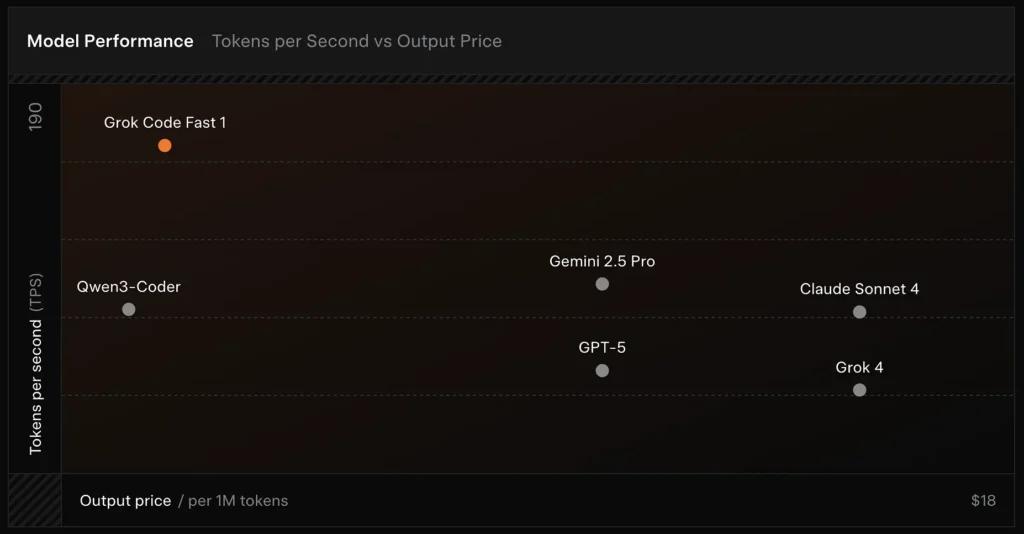
SWE-Bench-Verifiziert: xAI meldet eine 70.8% Score für ihren internen Harness im Vergleich zum SWE-Bench-Verified-Subset – einem Benchmark, der häufig für den Vergleich von Software-Engineering-Modellen verwendet wird. Eine kürzlich durchgeführte praktische Evaluierung berichtete von einem durchschnittliche menschliche Bewertung ≈ 7.6 auf einer gemischten Codierungssuite – konkurrenzfähig mit einigen hochwertigen Modellen (z. B. Gemini 2.5 Pro), aber hinter größeren multimodalen/„Best-Reasoner“-Modellen wie Claude Opus 4 und xAIs eigenem Grok 4 bei anspruchsvollen Reasoning-Aufgaben. Benchmarks zeigen auch Abweichungen je nach Aufgabe: hervorragend für allgemeine Fehlerbehebungen und präzise Codegenerierung, schwächer bei einigen Nischen- oder bibliotheksspezifischen Problemen (Beispiel Tailwind CSS).
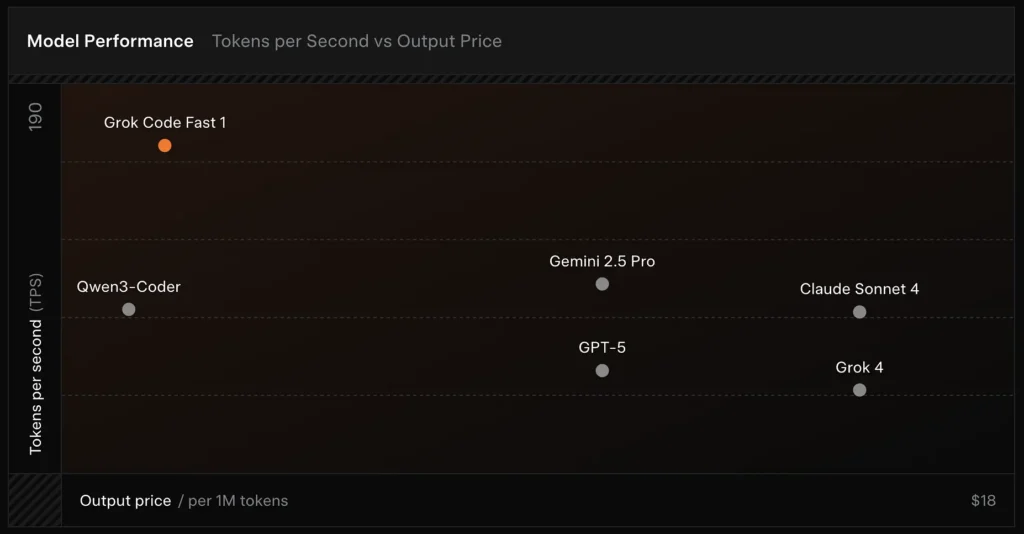
Vergleich :
- vs Grok 4: Grok-code-fast-1 tauscht absolute Korrektheit und tiefere Argumentation gegen wesentlich geringere Kosten und schnellerer Durchsatz; Grok 4 bleibt die Option mit der höheren Leistungsfähigkeit.
- vs Claude Opus / GPT-Klasse: Diese Modelle führen häufig zu komplexen, kreativen oder anspruchsvollen Denkaufgaben; Grok-Code-Fast-1 ist bei umfangreichen Routineaufgaben für Entwickler, bei denen es auf Latenz und Kosten ankommt, konkurrenzfähig.
Einschränkungen und Risiken
Bisher beobachtete praktische Einschränkungen:
- Domänenlücken: Leistungseinbrüche bei Nischenbibliotheken oder ungewöhnlich formulierte Probleme (Beispiele sind Randfälle von Tailwind CSS).
- Kompromiss zwischen Argumentation und Token-Kosten: Da das Modell interne Argumentationstoken ausgeben kann, kann eine stark agentenbasierte/ausführliche Argumentation die Länge (und die Kosten) der Inferenzausgabe erhöhen.
- Genauigkeit / Randfälle: Grok-code-fast-1 ist zwar gut für Routineaufgaben, kann aber halluzinieren oder fehlerhaften Code für neuartige Algorithmen oder kontroverse Problemstellungen erzeugen; bei anspruchsvollen algorithmischen Benchmarks kann es schlechter abschneiden als die besten auf logisches Denken ausgerichteten Modelle.
Typische Anwendungsfälle
- IDE-Unterstützung und Rapid Prototyping: schnelle Vervollständigungen, inkrementelles Schreiben von Code und interaktives Debuggen.
- Automatisierte Agenten/Code-Workflows: Agenten, die Tests orchestrieren, Befehle ausführen und Dateien bearbeiten (z. B. CI-Helfer, Bot-Prüfer).
- Tägliche Ingenieuraufgaben: Generieren von Code-Skeletten, Refactorings, Vorschlägen zur Fehlertriage und Gerüsten für Projekte mit mehreren Dateien, bei denen eine geringe Latenz den Entwicklerfluss erheblich verbessert.
So rufen Sie die API „grok-code-fast-1“ von CometAPI auf
grok-code-fast-1 API-Preise in CometAPI, 20 % Rabatt auf den offiziellen Preis:
- Eingabetoken: 0.16 $/M Token
- Ausgabe-Token: 2.0 $/M Token
Erforderliche Schritte
- Einloggen in cometapi.comWenn Sie noch nicht unser Benutzer sind, registrieren Sie sich bitte zuerst
- Holen Sie sich den API-Schlüssel für die Zugangsdaten der Schnittstelle. Klicken Sie im persönlichen Bereich beim API-Token auf „Token hinzufügen“, holen Sie sich den Token-Schlüssel: sk-xxxxx und senden Sie ihn ab.
Methode verwenden
- Wählen Sie das "
grok-code-fast-1”-Endpunkt, um die API-Anfrage zu senden und den Anfragetext festzulegen. Die Anfragemethode und der Anfragetext stammen aus der API-Dokumentation unserer Website. Unsere Website bietet außerdem einen Apifox-Test für Ihre Bequemlichkeit. - Ersetzen mit Ihrem aktuellen CometAPI-Schlüssel aus Ihrem Konto.
- Geben Sie Ihre Frage oder Anfrage in das Inhaltsfeld ein – das Modell antwortet darauf.
- . Verarbeiten Sie die API-Antwort, um die generierte Antwort zu erhalten.
CometAPI bietet eine vollständig kompatible REST-API für eine nahtlose Migration. Wichtige Details zu API-Dokument:
- Basis-URL: https://api.cometapi.com/v1/chat/completions
- Modellnamen: "
grok-code-fast-1" - Authentifizierung: Inhabertoken über
Authorization: Bearer YOUR_CometAPI_API_KEYKopfzeile - Content-Type:
application/json.
API-Integration und Beispiele
Python-Snippet für eine Chat-Abschluss Aufruf über CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Siehe auch Grok 4