

GLM-5 ist das neue Open-Weights, agentenzentrierte Foundation‑Modell von Zhipu AI, entwickelt für langfristiges Coding und Multi‑Step‑Agenten. Es ist über mehrere gehostete APIs verfügbar (einschließlich CometAPI und Anbieter‑Endpunkten) und als Research‑Release mit Code und Gewichten; Sie können es über OpenAI‑kompatible REST‑Aufrufe, Streaming und SDKs integrieren.
Was ist GLM-5 von Z.ai?
GLM-5 ist Z.ai’s fünfte Generation des Flaggschiff‑Foundation‑Modells, entwickelt für Agenten‑Engineering: langfristige Planung, mehrschrittige Tool‑Nutzung und groß angelegte Code-/System‑Entwicklung. Öffentlich veröffentlicht im Februar 2026, ist GLM-5 ein Mixture‑of‑Experts (MoE)‑Modell mit ~744 Milliarden Gesamtparametern und einem aktiven Parametersatz im Bereich von 40B pro Forward‑Pass; Architektur und Training priorisieren Langkontext‑Kohärenz, Tool‑Aufrufe und kosteneffiziente Inferenz für Produktions‑Workloads. Diese Designentscheidungen ermöglichen GLM-5, erweiterte agentische Workflows auszuführen (zum Beispiel: browsen → planen → Code schreiben/testen → iterieren) und dabei den Kontext über sehr lange Eingaben hinweg zu bewahren.
Wesentliche technische Highlights:
- MoE‑Architektur mit ~744B Gesamt‑/ ~40B aktive Parameter; skaliertes Pretraining (~28.5T Tokens berichtet), um die Lücke zu geschlossenen Spitzenmodellen zu schließen.
- Langkontext‑Support und Optimierungen (Deep Sparse Attention, DSA) für geringere Bereitstellungskosten gegenüber naivem dichten Skalieren.
- Agentische Features eingebaut: Tool-/Funktionsaufrufe, zustandsbehaftete Sitzungsunterstützung und integrierte Ausgaben (fähig,
.docx-,.xlsx-,.pdf‑Artefakte als Teil von Agenten‑Workflows in Anbieter‑UIs zu erzeugen). - Verfügbarkeit als Open‑Weights (Gewichte in Model Hubs veröffentlicht) und gehostete Zugriffsoptionen (Anbieter‑APIs, Inferenz‑Mikroservices).
Was sind die Hauptvorteile von GLM-5?
Agentische Planung und langfristiges Gedächtnis
Architektur und Tuning von GLM-5 priorisieren konsistentes mehrschrittiges Reasoning und Gedächtnis über Workflows hinweg — ein Vorteil für:
- autonome Agenten (CI‑Pipelines, Task‑Orchestratoren),
- umfangreiche Codegenerierung oder Refactorings über mehrere Dateien, und
- Dokumentenintelligenz, die große Verlaufshistorien halten muss.
Große Kontextfenster
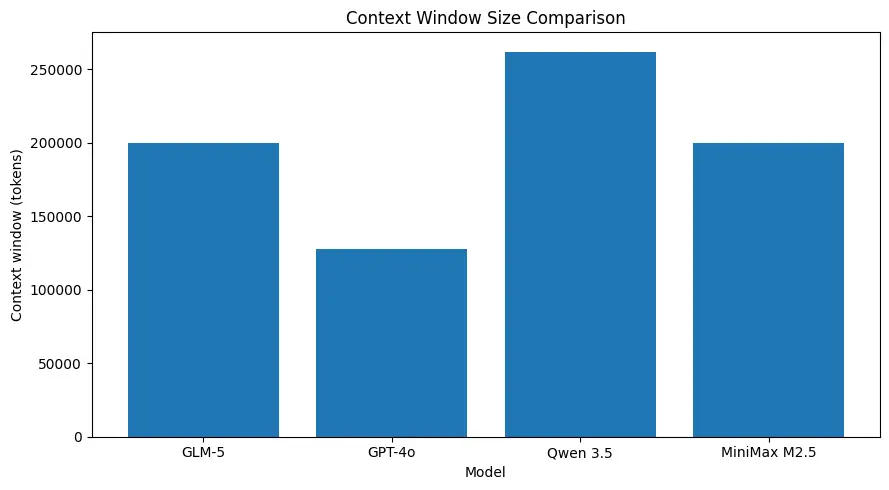
GLM-5 unterstützt sehr große Kontextgrößen (in der Größenordnung von ~200k Token laut veröffentlichten Modellspezifikationen), sodass Sie mehr einer Sitzung in einer Anfrage behalten können und für viele Anwendungsfälle weniger aggressives Chunking oder externe Speicher benötigen. (Siehe Vergleichsgrafik unten.)
Starke Coding‑Leistung für Aufgaben auf Systemebene
GLM-5 weist Spitzenleistungen im Open‑Source‑Bereich auf Software‑Engineering‑Benchmarks (SWE‑bench und angewandte Code‑/Agent‑Suites) aus. Auf SWE‑bench‑Verified werden ~77,8% berichtet; bei Coding-/Terminal‑Agent‑Tests (Terminal‑Bench 2.0) liegen die Werte in der Mitte der 50er — ein Beleg für praktische Coding‑Fähigkeiten, die sich proprietären Spitzenmodellen annähern. Diese Metriken bedeuten, dass sich GLM-5 für Aufgaben wie Codegenerierung, automatisches Refactoring, mehrdateibezogenes Reasoning und CI/CD‑Assistenz eignet.
Kosten-/Effizienz‑Abwägungen
Da GLM-5 MoE und „sparse“ Attention‑Innovationen nutzt, zielt es darauf ab, die Inferenzkosten pro Fähigkeitseinheit gegenüber brachialem dichten Skalieren zu reduzieren. CometAPI bietet wettbewerbsfähige Preise, die GLM-5 für Agenten‑Workloads mit hohem Durchsatz attraktiv machen.
Wie nutze ich die GLM-5‑API über CometAPI?
Kurzfassung: Behandeln Sie CometAPI wie ein OpenAI‑kompatibles Gateway — setzen Sie Ihre Basis‑URL und den API‑Key, wählen Sie glm-5 als Modell und rufen Sie den Chat/Completions‑Endpunkt auf. CometAPI stellt eine OpenAI‑artige REST‑Oberfläche bereit (Endpunkte wie https://api.cometapi.com/v1/chat/completions) plus SDKs und Beispielprojekte, die die Migration trivial machen.
Unten finden Sie ein praxisnahes, produktionsorientiertes Kochbuch: Auth, Basic‑Chat‑Call, Streaming, Funktions-/Tool‑Aufrufe sowie Kosten-/Response‑Handling.
Die grundlegenden Schritte für den Zugriff auf GLM-5 über CometAPI sind:
- Bei CometAPI anmelden, einen API‑Key erhalten.
- Die genaue Modell‑ID für GLM-5 im CometAPI‑Katalog finden (
"glm-5"je nach Listing). - Eine authentifizierte POST‑Anfrage an den CometAPI‑Chat/Completions‑Endpunkt (OpenAI‑Stil) senden.
Basisdetails (CometAPI‑Patterns): Die Plattform unterstützt OpenAI‑artige Pfade wie https://api.cometapi.com/v1/chat/completions, Bearer‑Authentifizierung, den Parameter model, System-/User‑Nachrichten, Streaming sowie Beispiele für curl/Python in den Docs.
Beispiel: schnelles Python‑(requests)‑Chat‑Completion mit GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Beispiel: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Streaming‑Antworten (Praxis‑Pattern)
CometAPI unterstützt Streaming im OpenAI‑Stil (SSE / chunked). Der einfachste Ansatz in Python ist, "stream": true anzufordern und die Antwortdaten beim Eintreffen zu iterieren. Das ist wichtig, wenn Sie Latenz‑arme Teil‑Outputs benötigen (z. B. Echtzeit‑Dev‑Assistenten, Streaming‑UIs).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Referenz: OpenAI‑Style‑Streaming und CometAPI‑Kompatibilitäts‑Docs.
Funktions‑/Tool‑Aufrufe (wie ein externes Tool aufrufen)
GLM-5 unterstützt Funktions‑ oder Tool‑Aufruf‑Muster, die mit OpenAI‑/Aggregator‑Konventionen kompatibel sind (das Gateway reicht strukturierte Funktionsaufrufe in der Modellantwort durch). Beispielanwendung: GLM-5 soll ein lokales „run_tests“‑Tool aufrufen; das Modell liefert eine strukturierte Anweisung zurück, die Sie parsen und ausführen können.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Wenn das Modell ein function_call‑Payload zurückgibt, führen Sie das Tool serverseitig aus und geben Sie das Tool‑Ergebnis als Nachricht mit der Rolle "tool" zurück, um die Konversation fortzusetzen. Dieses Muster ermöglicht sichere Tool‑Aufrufe und zustandsbehaftete Agenten‑Flows. Siehe CometAPI‑Docs und Beispiele für konkrete SDK‑Hilfen.
Praktische Parameter & Tuning
function_call: Aktivieren für strukturierte Tool‑Aufrufe und sicherere Ausführungsflows.
temperature: 0–0,3 für deterministische System‑Outputs (Code, Infra), höher für Ideation.
max_tokens: Auf erwartete Ausgabelänge setzen; GLM-5 unterstützt bei Hosting sehr lange Ausgaben (Anbieterlimits variieren).
top_p / Nucleus Sampling: Nützlich, um unwahrscheinliche Tails zu begrenzen.
stream: true für interaktive UIs.
Vergleich: GLM-5 mit Anthropics Claude Opus und anderen Frontier‑Modellen
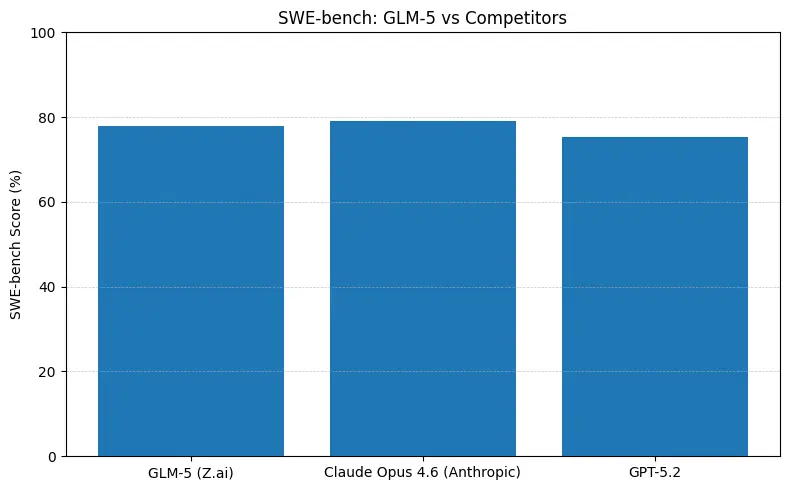
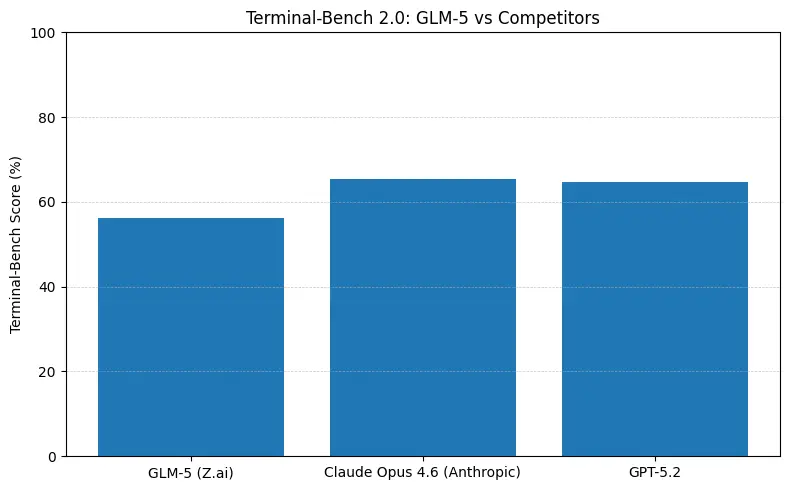
Kurzfassung: GLM-5 verkleinert die Lücke zu geschlossenen Spitzenmodellen in agentischen und Coding‑Benchmarks, bietet dabei Open‑Weights‑Deployment und oft bessere Kosten pro Token, wenn es von Aggregatoren gehostet wird. Die Nuance: Bei einigen absoluten Coding‑Benchmarks (SWE‑bench, Terminal‑Bench‑Varianten) führt Anthropics Claude Opus (4.5/4.6) in vielen veröffentlichten Ranglisten noch um ein paar Punkte — GLM-5 ist jedoch hoch konkurrenzfähig und übertrifft viele andere offene Modelle.
Was die Zahlen in der Praxis bedeuten
- SWE‑bench (~Code‑Korrektheit/Engineering): Claude Opus zeigt einen marginalen Vorsprung (≈79% vs. GLM-5 ≈77,8%) auf veröffentlichten Ranglisten; für viele reale Aufgaben bedeutet dieser Abstand weniger manuelle Änderungen, aber nicht unbedingt eine andere Architekturwahl für Prototyping oder skalierte agentische Workflows.
- Terminal‑Bench (Command‑Line‑agentische Aufgaben): Opus 4.6 führt (≈65,4% vs. GLM-5 ≈56,2%) — wenn Sie robuste Terminal‑Automatisierung und höchste Zuverlässigkeit bei Out‑of‑Distribution‑Shell‑Ops benötigen, ist Opus am Rand oft besser.
- Agentisch und Langhorizont: GLM-5 performt extrem gut bei Langhorizont‑Business‑Simulationen (Vending‑Bench 2 Saldo $4,432 berichtet) und zeigt starke Planungskohärenz für mehrschrittige Workflows. Wenn Ihr Produkt ein lang laufender Agent ist (Finance, Ops), ist GLM-5 stark.
Wie gestalte ich Prompts und Systeme, um zuverlässige GLM-5‑Outputs zu erhalten?
System‑Nachrichten & explizite Constraints
Geben Sie GLM-5 eine strikte Rolle und Constraints, insbesondere für Code‑ oder Tool‑Aufgaben. Beispiel:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Fordern Sie Tests und kurze Begründungen für jede nichttriviale Änderung an.
Komplexe Aufgaben zerlegen
Statt „Schreibe das gesamte Produkt“, fragen Sie nach:
- Design‑Umriss,
- Interface‑Signaturen,
- Implementierung und Tests,
- finalem Integrationsskript.
Diese schrittweise Zerlegung reduziert Halluzinationen und liefert deterministische Checkpoints, die Sie validieren können.
Niedrige Temperature für deterministischen Code verwenden
Beim Anfordern von Code temperature auf 0–0,2 setzen und max_tokens großzügig dimensionieren. Für Kreativschreiben oder Ideenfindung die Temperature erhöhen.
Best Practices bei der Integration von GLM-5 (über CometAPI oder direkte Hosts)
Prompt Engineering & System‑Prompts
- Verwenden Sie explizite System‑Instruktionen, die Agentenrollen, Tool‑Zugriffsrichtlinien und Safety‑Constraints definieren. Beispiel: „Du bist Systemarchitekt: Schlage nur Änderungen vor, wenn Unit‑Tests lokal bestehen; liste die exakten CLI‑Befehle zum Ausführen auf.“
- Für Coding‑Aufgaben Repository‑Kontext bereitstellen (Dateilisten, wichtige Code‑Snippets) und wenn möglich Unit‑Test‑Ausgaben anhängen. GLM‑5s Langkontext‑Handling hilft — aber halten Sie wesentlichen Kontext immer zuerst (Rolle, Aufgabe), danach unterstützende Artefakte.
Sitzungs‑ & Zustandsverwaltung
- Verwenden Sie Sitzungs‑IDs für lange Agenten‑Konversationen und halten Sie ein kompaktes „Gedächtnis“ früherer Schritte (Zusammenfassungen), um Kontext‑Bloat zu verhindern. CometAPI und ähnliche Gateways bieten Sitzungs-/State‑Hilfen — aber anwendungsseitige State‑Kompression ist für lang laufende Agenten essenziell.
Tooling & Funktionsaufrufe (Sicherheit + Zuverlässigkeit)
- Stellen Sie einen engen, prüfbaren Satz an Tools bereit. Erlauben Sie keine beliebige Shell‑Ausführung ohne menschliche Aufsicht. Nutzen Sie strukturierte Funktionsdefinitionen und validieren Sie ihre Argumente serverseitig.
- Protokollieren Sie Tool‑Aufrufe und Modellantworten immer für Nachvollziehbarkeit und Post‑Mortem‑Debugging.
Kostenkontrolle & Batching
- Für High‑Volume‑Agenten Hintergrundverarbeitung auf günstigere Modellvarianten routen, wenn Qualitätskompromisse akzeptabel sind (bei CometAPI lässt sich das Modell per Name wechseln). Ähnliche Anfragen batchen und
max_tokensreduzieren, wo möglich. Verhältnis Eingabe‑ vs. Ausgabe‑Token überwachen — Ausgabetoken sind oft teurer.
Latenz‑ & Durchsatz‑Engineering
- Streaming für interaktive Sitzungen nutzen. Für Hintergrund‑Agent‑Jobs asynchrone Runtimes, Worker‑Queues und Rate‑Limiter bevorzugen. Beim Selbst‑Hosting (Open‑Weights) die Beschleuniger‑Topologie auf die MoE‑Architektur abstimmen — FPGA / Ascend / spezialisiertes Silizium kann Kostenvorteile bringen.
Abschließende Hinweise
GLM-5 stellt einen praxisnahen, Open‑Weights‑Schritt in Richtung Agenten‑Engineering dar: große Kontextfenster, Planungskapazitäten und starke Code‑Leistung machen es attraktiv für Entwickler‑Tools, Agenten‑Orchestrierung und Automatisierung auf Systemebene. Nutzen Sie CometAPI für die schnelle Integration oder einen Cloud‑Model‑Garden für Managed Hosting; validieren Sie stets auf Ihrem Workload und instrumentieren Sie umfangreich für Kosten‑ und Halluzinationskontrollen.
Entwickler können auf GLM-5 über CometAPI zugreifen. Um loszulegen, erkunden Sie die Fähigkeiten des Modells im Playground und konsultieren Sie den API‑Leitfaden für detaillierte Anweisungen. Bitte stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API‑Key erhalten haben. CometAPI bietet einen Preis, der weit unter dem offiziellen Preis liegt, um Ihnen die Integration zu erleichtern.
Bereit loszulegen?→ Melde dich noch heute für M2.5 an!
Wenn Sie mehr Tipps, Anleitungen und News zu KI wünschen, folgen Sie uns auf VK, X und Discord!