

Claude Opus 4.5 ist Anthropic’s neuestes „Opus“-Klasse Modell (veröffentlicht Ende November 2025). Es ist als Top-Tier-Modell für professionelle Softwareentwicklung, langhorizontale agentische Workflows und unternehmenskritische Aufgaben positioniert, und Anthropic hat den Preis bewusst so gesetzt, dass hohe Leistungsfähigkeit für Produktionsnutzer zugänglicher wird. Im Folgenden erläutere ich, was die Claude Opus 4.5 API ist, wie das Modell auf realen Engineering-Benchmarks abschneidet, wie genau die Preisgestaltung funktioniert (API und Abonnement), wie sie sich im Vergleich zu älteren Anthropic-Modellen und Wettbewerbern (OpenAI, Google Gemini) darstellt und welche praktischen Best Practices es für kosteneffiziente Produktions-Workloads gibt. Außerdem füge ich unterstützenden Code sowie ein kleines Benchmarking- und Kostenberechnungstoolkit bei, das Sie kopieren und ausführen können.
Was ist die Claude Opus 4.5 API?
Claude Opus 4.5 ist das neueste Modell der Opus-Klasse: ein leistungsstarkes, multimodales Modell, das speziell für professionelle Softwareentwicklung, agentische Tool-Nutzung (d. h. das Aufrufen und Komponieren externer Tools) und Computer-Use-Aufgaben abgestimmt ist. Es behält die Extended-Thinking-Fähigkeiten bei (transparente, schrittweise interne Reasoning-Pfade, die Sie streamen können) und fügt fein granulare Laufzeitkontrollen hinzu (insbesondere den effort-Parameter). Anthropic positioniert dieses Modell als geeignet für produktive Agents, Code-Migration/Refactoring und Enterprise-Workflows, die Robustheit und weniger Iterationen erfordern.
Zentrale API-Funktionen und Developer-UX
Opus 4.5 unterstützt:
- Standard-Textgenerierung + hochpräzises Befolgen von Anweisungen.
- Extended Thinking / mehrstufige Reasoning-Modi (nützlich für Coding, lange Dokumente).
- Tool-Nutzung (Websuche, Codeausführung, benutzerdefinierte Tools), Memory und Prompt-Caching.
- „Claude Code“ und agentische Flows (Automatisierung mehrstufiger Aufgaben über Codebasen hinweg).
Wie performt Claude Opus 4.5?
Opus 4.5 ist State-of-the-Art bei Software-Engineering-Benchmarks — mit ~80,9 % auf SWE-bench Verified und ebenfalls starken Ergebnissen auf „Computer-Use“-Benchmarks wie OSWorld. Opus 4.5 kann die Performance von Sonnet 4.5 bei geringerem Token-Verbrauch erreichen oder übertreffen (d. h. höhere Token-Effizienz).
Software-Engineering-Benchmarks (SWE-bench / Terminal Bench / Aider Polyglot): Anthropic berichtet, dass Opus 4.5 bei SWE-bench Verified führt, Terminal Bench um ~15 % gegenüber Sonnet 4.5 verbessert und bei Aider Polyglot einen Sprung von 10,6 % gegenüber Sonnet 4.5 zeigt (interne Vergleiche).
Langfristiges, autonomes Coding: Laut Anthropic hält Opus 4.5 seine Performance in 30-minütigen autonomen Coding-Sessions stabil und zeigt weniger Sackgassen in mehrstufigen Workflows. Dies ist ein wiederholter interner Befund über ihre Agent-Tests hinweg.
Verbesserungen bei Real-World-Aufgaben (Vending-Bench / BrowseComp-Plus usw.): Anthropic nennt +29 % auf Vending-Bench (langhorizontale Aufgaben) gegenüber Sonnet 4.5 und verbesserte agentische Suchmetriken auf BrowseComp-Plus.
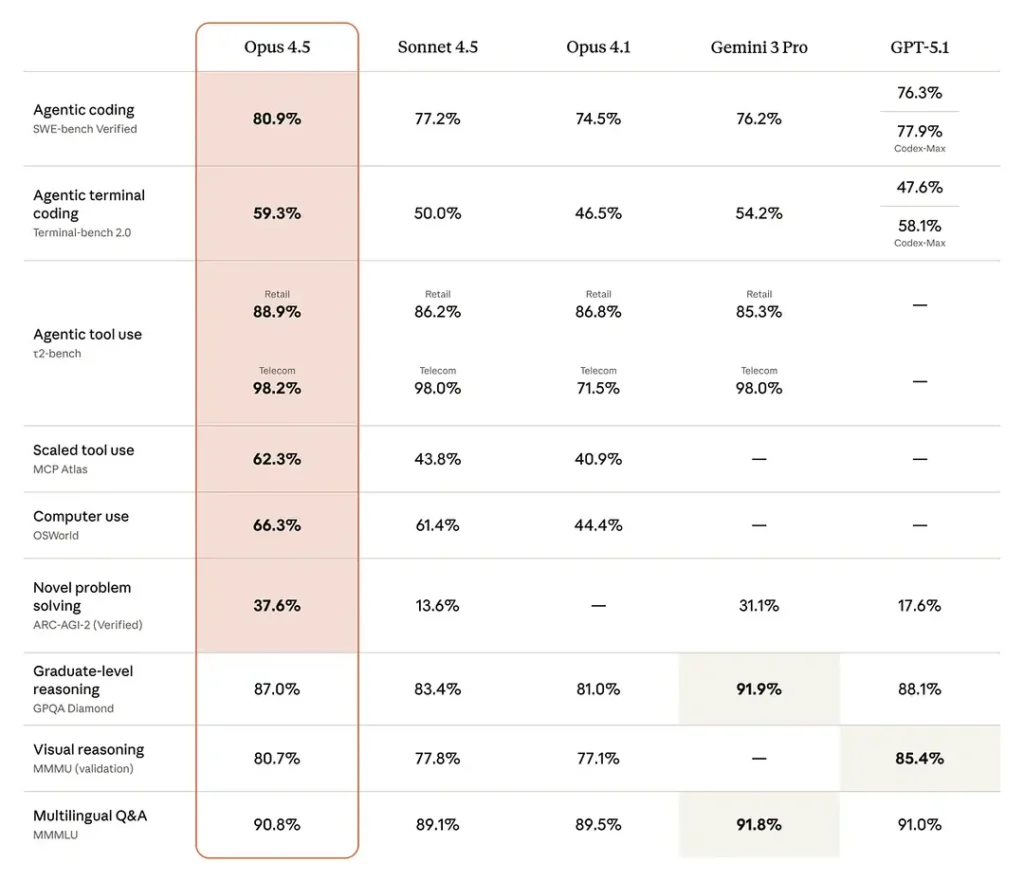
Einige konkrete Erkenntnisse aus den Berichten:
- Coding-Führerschaft: Opus 4.5 schlägt häufig frühere Opus-/Sonnet-Varianten und viele zeitgleiche Wettbewerbermodelle bei aggregierten Software-Engineering-Benchmarks (SWE-bench Verified und Terminal-Bench-Varianten).
- Office-Automatisierung: Rezensenten heben bessere Tabellenerstellung und PowerPoint-Produktion hervor — Verbesserungen, die den Nachbearbeitungsaufwand für Analysten und Produktteams reduzieren.
- Agenten- & Tool-Zuverlässigkeit: Opus 4.5 verbessert sich in mehrstufigen agentischen Workflows und lang laufenden Aufgaben und verringert Ausfälle in Pipelines mit mehreren Aufrufen.
Wie viel kostet Claude Opus 4.5?
Das ist die zentrale Frage. Im Folgenden zerlege ich sie nach API-Preismodell, Abonnementstufen, Beispielkostenrechnungen und den praktischen Implikationen.
API-Preismodell — was Anthropic veröffentlicht hat
Anthropic hat für Opus 4.5 den API-Preis wie folgt festgelegt:
- Input (Tokens): $5 pro 1.000.000 Input-Tokens
- Output (Tokens): $25 pro 1.000.000 Output-Tokens
Anthropic hat diesen Preis ausdrücklich als bewusste Senkung eingerahmt, um Opus-Klassen-Performance breit zugänglich zu machen. Der Modellbezeichner für Entwickler ist die Zeichenfolge claude-opus-4-5-20251101.
In CometAPI kostet die Claude Opus 4.5 API $4 / 1M Input-Tokens und $20 / 1M Output-Tokens für Opus 4.5, etwa 20 % günstiger als der offizielle Google-Preis.
Preistabelle (vereinfacht, USD pro Million Tokens)
| Model | Input ($ / MTok) | Output ($ / MTok) | Notes |
|---|---|---|---|
| Claude Opus 4.5 (base) | $5.00 | $25.00 | Anthropic Listenpreis. |
| Claude Opus 4.1 | $15.00 | $75.00 | Ältere Opus-Version — höhere Listenpreise. |
| Claude Sonnet 4.5 | $3.00 | $15.00 | Günstigere Familie für viele Aufgaben. |
Wichtiger Hinweis: Dies sind tokenbasierte Preise (nicht pro Anfrage). Abgerechnet wird nach den Tokens, die Ihre Anfragen verbrauchen — sowohl Input (Prompt + Kontext) als auch Output (vom Modell generierte Tokens).
Abonnementpläne und App-Tarife (Consumer/Pro/Team)
Die API eignet sich gut für kundenspezifische Builds, während der Claude-Abonnementplan Opus 4.5 mit UI-Tools bündelt und so in interaktiven Szenarien Bedenken wegen per-Token-Verbrauch eliminiert. Der Free-Plan ($0) ist auf Basic-Chat und das Haiku/Sonnet-Modell beschränkt und enthält kein Opus.
Der Pro-Plan ($20 pro Monat oder $17 pro Jahr) und der Max-Plan ($100 pro Person und Monat, bietet das 5- bis 20-fache der Pro-Nutzung) schalten Opus 4.5, Claude Code, Dateiausführung und unbegrenzte Projekte frei.
Wie optimiere ich die Token-Nutzung?
- Nutzen Sie
effortangemessen: Wählen Sielowfür Routineantworten,highnur bei Bedarf. - Bevorzugen Sie strukturierte Ausgaben & Schemas, um verbose Hin-und-Her zu vermeiden.
- Verwenden Sie die Files API, um zu vermeiden, dass große Dokumente erneut im Prompt gesendet werden.
- Komprimieren oder fassen Sie Kontext vor dem Senden programmatisch zusammen.
- Cachen Sie wiederkehrende Antworten und verwenden Sie sie erneut, wenn Prompt-Eingaben identisch oder ähnlich sind.
Pragmatische Regel: Instrumentieren Sie die Nutzung früh (Tokens pro Anfrage tracken), führen Sie Lasttests mit repräsentativen Prompts durch und berechnen Sie die Kosten pro erfolgreicher Aufgabe (nicht pro Token), damit Optimierungen auf realen ROI zielen.
Schneller Beispielcode: Claude Opus 4.5 aufrufen + Kosten berechnen
Unten stehen Copy-Ready-Beispiele: (1) curl, (2) Python mit dem SDK von Anthropic und (3) ein kleines Python-Helper, das die Kosten aus gemessenen Input-/Output-Tokens berechnet.
Wichtig: Speichern Sie Ihren API-Schlüssel sicher in einer Umgebungsvariable. Die Snippets gehen davon aus, dass
ANTHROPIC_API_KEYgesetzt ist. Die Modell-ID istclaude-opus-4-5-20251101(Anthropic).
1) cURL-Beispiel (einfacher Prompt)
curl https://api.anthropic.com/v1/complete \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model":"claude-opus-4-5-20251101",
"prompt":"You are an assistant. Given the following requirements produce a minimal Python function that validates emails. Return only code.",
"max_tokens": 600,
"temperature": 0.0
}'
2) Python (anthropic SDK) — Basic Request
# pip install anthropic
import os
from anthropic import Anthropic, HUMAN_PROMPT, AI_PROMPT
client = Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
prompt = HUMAN_PROMPT + "Given the following requirements produce a minimal Python function that validates emails. Return only code.\n\nRequirements:\n- Python 3.10\n- Use regex\n" + AI_PROMPT
resp = client.completions.create(
model="claude-opus-4-5-20251101",
prompt=prompt,
max_tokens_to_sample=600,
temperature=0.0
)
print(resp.completion) # model output
Hinweis: Namen und Aufrufsignaturen im Python-SDK von Anthropic können variieren; das obige Beispiel folgt gängigen Mustern in ihrem öffentlichen SDK und den Docs — prüfen Sie die Dokumentation Ihrer installierten Version für die exakten Methodennamen. GitHub+1
3) Kostenrechner (Python) — Kosten aus Tokens berechnen
def compute_claude_cost(input_tokens, output_tokens,
input_price_per_m=5.0, output_price_per_m=25.0):
"""
Compute USD cost for Anthropic Opus 4.5 given token counts.
input_price_per_m and output_price_per_m are dollars per 1,000,000 tokens.
"""
cost_input = (input_tokens / 1_000_000) * input_price_per_m
cost_output = (output_tokens / 1_000_000) * output_price_per_m
return cost_input + cost_output
# Example: 20k input tokens and 5k output tokens
print(compute_claude_cost(20000, 5000)) # => ~0.225 USD
Tipp: Messen Sie Tokens für reale Anfragen über Server-Logs/Provider-Telemetrie. Wenn Sie lokal exakte Tokenisierungszahlen benötigen, verwenden Sie einen Tokenizer, der mit der Tokenisierung von Claude kompatibel ist, oder verlassen Sie sich auf die Token-Zähler des Providers, sofern verfügbar.
Wann sollten Sie Opus 4.5 gegenüber günstigeren Modellen wählen?
Nutzen Sie Opus 4.5, wenn:
- Sie mission-kritische Engineering-Workloads haben, bei denen Korrektheit beim ersten Durchlauf materiell wertvoll ist (komplexe Codegenerierung, Architekturvorschläge, lange agentische Läufe).
- Ihre Aufgaben Tool-Orchestrierung oder tiefes mehrstufiges Reasoning innerhalb eines einzelnen Workflows benötigen. Programmatisches Tool-Calling ist ein zentraler Differenziator.
- Sie menschliche Review-Schleifen reduzieren möchten — die höhere Ersttrefferquote des Modells kann den nachgelagerten menschlichen Aufwand und damit die Gesamtkosten senken.
Ziehen Sie Sonnet/Haiku oder Wettbewerbermodelle in Betracht, wenn:
- Ihr Anwendungsfall gesprächige, hochvolumige, risikoarme Zusammenfassungen umfasst, bei denen günstigere Tokens und hoher Durchsatz zählen. Sonnet (ausgewogen) oder Haiku (leichtgewichtig) können kosteneffektiver sein.
- Sie die absolut günstigste Per-Token-Verarbeitung benötigen und bereit sind, etwas Leistungsfähigkeit/Genauigkeit zu tauschen (z. B. einfache Zusammenfassungen, Basis-Assistenten).
Wie sollte ich Prompts für Opus 4.5 gestalten?
Welche Message-Rollen und Prefill-Strategien funktionieren am besten?
Nutzen Sie ein Drei-Teile-Muster:
- System (role: system): globale Anweisungen — Ton, Guardrails, Rolle.
- Assistant (optional): vorbereitete Beispiele oder primende Inhalte.
- User (role: user): die unmittelbare Anfrage.
Befüllen Sie die System-Nachricht mit Constraints (Format, Länge, Sicherheitsrichtlinie, JSON-Schema für strukturierte Ausgabe). Für Agents fügen Sie Toolspezifikationen und Anwendungsbeispiele hinzu, damit Opus 4.5 diese Tools korrekt aufrufen kann.
Wie nutze ich Context-Compaction und Prompt-Caching, um Tokens zu sparen?
- Context-Compaction: Komprimieren Sie ältere Teile einer Konversation zu prägnanten Zusammenfassungen, die das Modell weiterhin verwenden kann. Opus 4.5 unterstützt Automatisierung, um Kontext zu komprimieren, ohne kritische Reasoning-Blöcke zu verlieren.
- Prompt-Caching: Cachen Sie Modellantworten für wiederholte Prompts (Anthropic bietet Prompt-Caching-Muster zur Reduzierung von Latenz/Kosten).
Beide Funktionen reduzieren den Token-Footprint langer Interaktionen und werden für lang laufende Agent-Workflows und Produktionsassistenten empfohlen.
Best Practices: Opus-Niveau erreichen und Kosten kontrollieren
1) Prompts und Kontext optimieren
- Minimieren Sie überflüssigen Kontext — senden Sie nur die notwendige Historie. Kürzen und fassen Sie frühere Gespräche zusammen, wenn Sie langes Hin-und-Her erwarten.
- Nutzen Sie Retrieval/Embedding + RAG, um nur die Dokumente für eine spezifische Frage abzurufen (anstatt ganze Korpora als Prompt-Tokens zu senden). Die Anthropic-Dokumente empfehlen RAG und Prompt-Caching zur Reduzierung des Token-Verbrauchs.
2) Antworten cachen und wiederverwenden, wo möglich
Prompt-Caching: Wenn viele Anfragen identische oder nahezu identische Prompts haben, cachen Sie Outputs und servieren Sie Cache-Versionen, statt jedes Mal das Modell aufzurufen. Anthropic hebt Prompt-Caching ausdrücklich als Kostenoptimierung hervor.
3) Das richtige Modell für die Aufgabe wählen
- Nutzen Sie Opus 4.5 für geschäftskritische, hochwertige Aufgaben, bei denen menschliche Nacharbeit teuer ist.
- Nutzen Sie Sonnet 4.5 oder Haiku 4.5 für hochvolumige, weniger risikoreiche Aufgaben. Diese gemischte Modellstrategie liefert das bessere Preis/Leistungs-Verhältnis über den Stack hinweg.
4) Max Tokens und Streaming steuern
Begrenzen Sie max_tokens_to_sample für Outputs, wenn Sie keine volle Ausführlichkeit benötigen. Nutzen Sie Streaming, wo unterstützt, um die Generierung frühzeitig zu stoppen und Output-Token-Kosten zu sparen.
Abschließende Gedanken: Lohnt sich die Einführung von Opus 4.5 jetzt?
Opus 4.5 ist ein bedeutender Schritt nach vorn für Organisationen, die höherwertiges Reasoning, geringere Token-Kosten für lange Interaktionen und sichereres, robusteres Agent-Verhalten benötigen. Wenn Ihr Produkt auf anhaltendes Reasoning angewiesen ist (komplexe Codeaufgaben, autonome Agents, tiefe Forschungssynthese oder intensive Excel-Automatisierung), bietet Opus 4.5 zusätzliche Stellschrauben (effort, Extended Thinking, verbesserte Tool-Handhabung), um reale Performance und Kosten zu optimieren.
Entwickler können auf die Claude Opus 4.5 API über CometAPI zugreifen. Um loszulegen, erkunden Sie die Modellfähigkeiten vonCometAPI im Playground und konsultieren Sie den API guide für detaillierte Anweisungen. Bevor Sie zugreifen, stellen Sie bitte sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bietet einen deutlich niedrigeren Preis als der offizielle Preis, um Ihnen die Integration zu erleichtern.
Ready to Go?→ Sign up for CometAPI today !
Wenn Sie mehr Tipps, Guides und News zu KI wünschen, folgen Sie uns auf VK, X und Discord!