

Das chinesische Unternehmen Z.ai (ehemals Zhipu AI) hat mit der Einführung seiner Open-Source-GLM-4.5-Serie erneut für Schlagzeilen gesorgt. GLM-4.5 ist eine kostengünstige und leistungsstarke Alternative zu bestehenden großen Sprachmodellen und verspricht, die Token-Ökonomie neu zu gestalten und den Zugang für Start-ups, Unternehmen und Forschungseinrichtungen zu demokratisieren. Dieser umfassende Artikel untersucht die Ursprünge, die Preisstruktur und den realen Wert der GLM-4.5-Serie und beantwortet die beiden wichtigsten Fragen, die sich alle Beteiligten stellen: Wie viel kostet es und lohnt es sich?
Was ist die GLM 4.5-Serie?
Die GLM 4.5-Serie von Z.ai basiert auf einem „agentischen“ KI-Framework. Das bedeutet, dass das Modell komplexe Aufgaben selbstständig in kleinere, sequenzielle Teilaufgaben zerlegen kann – das erhöht die Präzision und reduziert redundante Berechnungen. Dies steht im Gegensatz zu monolithischeren LLMs, die Eingabeaufforderungen in einem einzigen Durchgang verarbeiten. Laut Z.ai integriert GLM 4.5 Argumentation und Aktionsplanung nativ in seine Kernarchitektur und ermöglicht so mehrstufige Workflows wie die Generierung von Datenvisualisierungen oder die End-to-End-Dokumentenverarbeitung ohne externe Orchestrierung.
Die von Z.ai entwickelte GLM 4.5-Serie repräsentiert die neueste Generation von Open-Source-Sprachmodellen mit Expertenmischung (MoE), die darauf ausgelegt sind, fortgeschrittenes Denken, Codegenerierung und Agentenfunktionen in einer einzigen Architektur zu vereinen. Es gibt zwei Hauptvarianten: das Flaggschiff GLM 4.5 (355 B Gesamtparameter, 32 B aktiv) und das leichtere GLM 4.5‑Air (106 B insgesamt, 12 B aktiv). Beide Varianten nutzen einen hybriden Inferenzmechanismus – „Denkmodus“ für komplexes, toolgestütztes Denken und „Nicht-Denkmodus“ für schnelle, unkomplizierte Vervollständigungen – und decken damit ein breites Spektrum an Anwendungsfällen ab, von der Full-Stack-Entwicklung bis hin zu autonomen Agenten-Workflows.
Technische Kernspezifikationen:
- Kenngrößen: GLM 4.5 verfügt über 355 Milliarden Parameter, wobei pro Inferenz eine aktive Teilmenge von 32 Milliarden genutzt wird, um die Hardwarenutzung und den Durchsatz zu optimieren.
- Expertenmix (MoE): Die Serie nutzt die MoE-Architektur und leitet Token aus Effizienzgründen dynamisch an Experten-Subnetzwerke weiter.
- Kontextfenster: Auf ausgewählten Plattformen (z. B. SiliconFlow) auf 128 Token erweitert, um große Dokumente und Codebasen zu ermöglichen.
- Generationsgeschwindigkeit: Hochgeschwindigkeitsvarianten überschreiten 100 Token/Sek. und sind für Echtzeitanwendungen geeignet.
- Hybride Inferenzmodi: Benutzer können zwischen dem „Denkmodus“ (vollständige MoE-Aktivierung für tiefgründiges Denken) und dem „Nicht-Denkmodus“ (minimale Aktivierung für schnelle Reaktionen im laufenden Betrieb) umschalten, wodurch Entwickler eine fein abgestufte Kontrolle über Leistung und Geschwindigkeit erhalten.
Welche Varianten gibt es innerhalb der Serie?
- GLM 4.5 (Standard): 355 B gesamt / 32 B aktive Parameter. In erster Linie für eine ausgewogene Leistung bei Schlussfolgerungs-, Codierungs- und Agentenaufgaben konzipiert.
- GLM 4.5‑Air: Eine leichte Version mit 106 B Gesamtspeicher und 12 B aktiven Parametern, zugeschnitten auf Szenarien mit strengen Hardware- oder Latenzbeschränkungen – mit wettbewerbsfähiger Genauigkeit in ihrer Klasse.
Wie viel kostet die GLM 4.5-Serie?
Wie hoch sind die Input- und Output-Token-Preise?
Laut den öffentlichen API-Preisangaben von Z.ai beträgt der Preis für GLM 4.5:
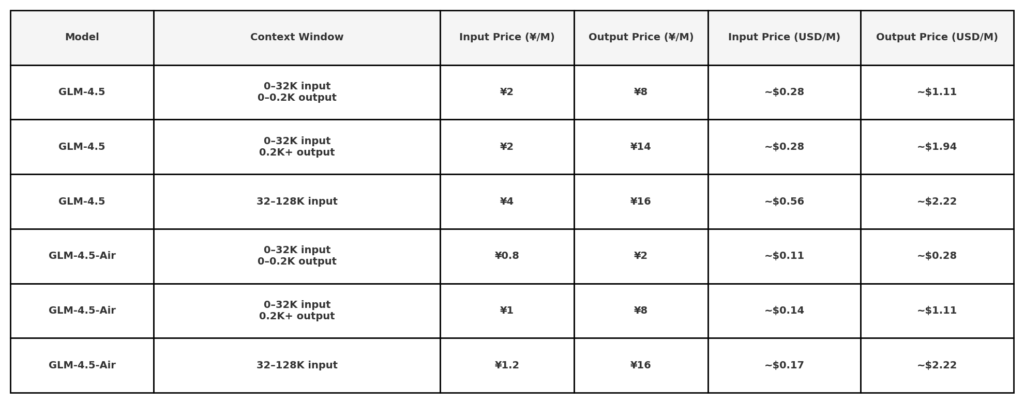
Hinweis: Sehr niedrige Preise (0.11 $/0.28 $) können auf kleine Tokenlängen oder bestimmte Aktionen beschränkt sein. 50 % Rabatt auf alle Modelle für eine begrenzte Zeit, gültig bis zum 31. August 2025. Andere Modelle finden Sie unter Büropreisseite.
Auf der CometAPI ist die Serie mit leicht unterschiedlichen Preisstaffelungen gebündelt, siehe GLM‑4.5 API:
| Modell | stellen die Kernaussage vor | Preis |
glm-4.5 | Unser leistungsstärkstes Schlussfolgerungsmodell mit 355 Milliarden Parametern | Eingabe-Token 0.48 $ Ausgabe-Token 1.92 $ |
glm-4.5-air | Kostengünstig Leichtgewicht Starke Leistung | Eingabe-Token 0.16 $ Ausgabe-Token 1.07 $ |
glm-4.5-x | Hohe Leistung, starke Argumentation, ultraschnelle Reaktion | Eingabe-Token 1.60 $ Ausgabe-Token 6.40 $ |
glm-4.5-airx | Leichtgewichtig Starke Leistung Ultraschnelle Reaktion | Eingabe-Token 0.02 $ Ausgabe-Token 0.06 $ |
glm-4.5-flash | Starke Leistung, hervorragend für Reasoning Coding und Agenten | Eingabe-Token 3.20 $ Ausgabe-Token 12.80 $ |
Wie ist die Preisgestaltung von GLM 4.5 im Vergleich zu DeepSeek und Western LLMs?
Auf der World AI Conference 2025 positionierte Z.ai GLM 4.5 ausdrücklich als Herausforderer von DeepSeek – dem bisherigen Kostenführer in China – und versprach „einen Bruchteil der Token-Kosten“ und die Hälfte des Hardware-Footprints des R1-Modells von DeepSeek.
- DeepSeek R1: Ungefähr 0.14 USD Input, 0.60 USD Output pro Million Token.
- GLM 4.5: Angeblich 20–30 % günstiger als DeepSeek bei Eingabe und Ausgabe.
- Westliche Benchmarks: GPT‑4 von OpenAI und Gemini von Google kosten zwischen 3 und 15 USD pro Million Token, sodass GLM 4.5 eine Kostensenkung um eine Größenordnung darstellt.
Diese Preisstrategie spiegelt Chinas umfassenderes KI-Wirtschaftsmodell wider: schlankere Rechenleistung, kleinere Modelle und aggressives Unterbieten, um Marktanteile zu gewinnen.
Lohnt sich die GLM 4.5-Serie?
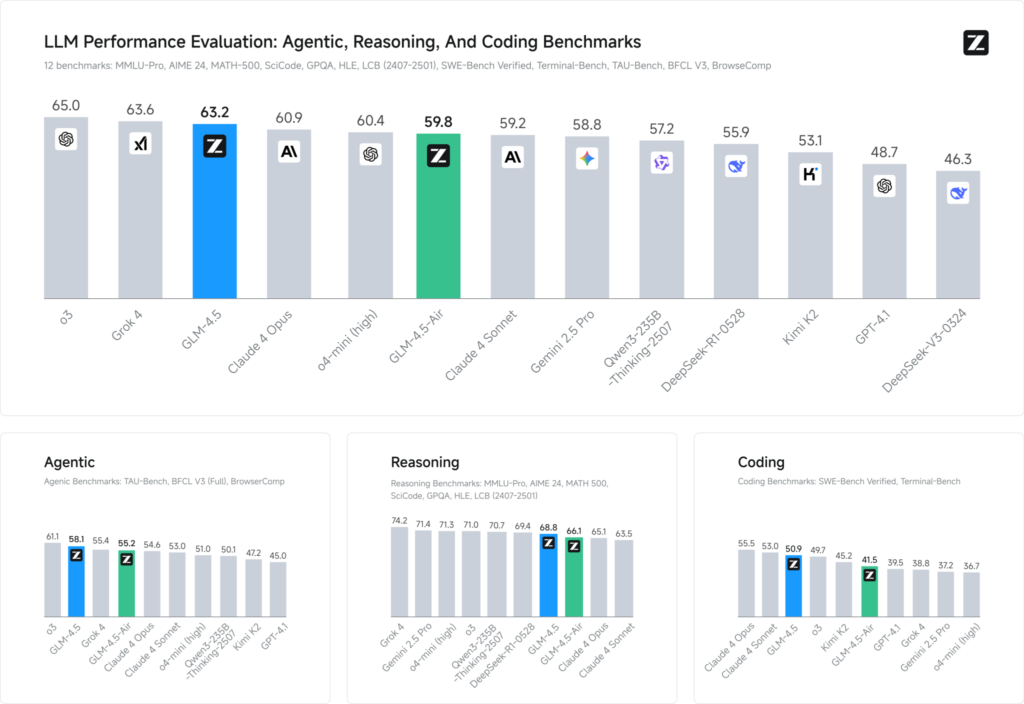
Benchmark-Bewertungen anhand von 12 repräsentativen Datensätzen (darunter MMLU Pro, MATH 500, SciCode, Terminal-Bench und TAU-Bench) zeigen, dass GLM 4.5 weltweit den 3. Platz hinter Grok 4 von xAI und o3 von OpenAI einnimmt – und dennoch die Nummer 1 unter den Open-Source-Angeboten ist.
Bei Codierungsaufgaben (LiveCodeBench, SWE-Bench) trägt das Mixture-of-Experts-Design von GLM 4.5 zu einer erstklassigen Codegenerierungsqualität bei, während die mehrstufige Planung beim Reasoning (AIME 24, MMLU Pro) eine robuste Genauigkeit liefert, die mit Closed-Source-Pendants vergleichbar ist. Die leichte Air-Variante erzielt innerhalb ihrer Parameterspanne (100-B-Skala) wettbewerbsfähige Ergebnisse und ist daher eine attraktive Wahl für Edge-Bereitstellungen und eingebettete Systeme.
Leistungsbenchmarks
- Intelligenzindex: GLM 4.5 Punkte 66 auf einem zusammengesetzten Intelligenzindex (MMLU Pro, MATH 500, AIME 24) und übertrifft damit viele Open-Source- und kommerzielle Mid-Tier-Modelle.
- Inferenzlatenz: Durchschnittliche Zeit bis zum ersten Token 0.89 Sekunden, konkurrenzfähig für komplexe Denkaufgaben, allerdings mit etwas geringerem Durchsatz (≈45.7 Token/s) im Vergleich zu einigen optimierten Closed-Source-Modellen.
- Agentischer Workflow: Demonstriert solide Kenntnisse im Umgang mit mehrstufigen Tools und der dynamischen Codegenerierung mit direkten Siegen von ~54 % gegen Kimi K2 kombiniert mit einem nachhaltigen Materialprofil. 81 % gegen Qwen3‑Coder in unabhängigen Codierungsbewertungen.
Welche praktischen Anwendungsfälle zeigen den ROI?
- Full‑Stack‑Entwicklung: GLM‑4.5 kann ganze Webanwendungen – von Frontend-Layouts in HTML/CSS/JavaScript bis hin zu Backend-Datenbankschemata – durch Multi‑Turn-Prompts erstellen und so die Prototyping-Zyklen von Tagen auf Stunden verkürzen.
- Komplexe Dokumentenanalyse: Das erweiterte 128-K-Kontextfenster ermöglicht es juristischen, finanziellen und wissenschaftlichen Unternehmen, mehrseitige Verträge oder Forschungsberichte in einem Durchgang zu analysieren und so den Segmentierungsaufwand zu reduzieren.
- Automatisierte Agenten-Workflows: Hybride Inferenz ermöglicht die Erstellung autonomer Skripte (z. B. Web Scraping Bots, Handelsagenten), die mehrstufige Prozesse mit minimalem menschlichen Eingriff durchdenken.
Quantitative Fallstudien deuten darauf hin, dass bis zu 60 Prozent Reduzierung der Entwicklerstunden für codezentrierte Aufgaben und 40 Prozent schnellere Bearbeitung von Langform-Inhaltsanalysen.
Was sind die potenziellen Nachteile und Überlegungen?
Keine Technologie ist ohne Kompromisse möglich. Potenzielle Anwender sollten regulatorische, betriebliche und ökologische Faktoren berücksichtigen.
Einschränkungen
Support und SLAs: Open-Source-Anbieter bieten im Gegensatz zu kommerziellen Anbietern möglicherweise keine SLAs auf Unternehmensniveau oder 24/7-Support an.
Durchsatzbeschränkungen: Obwohl das Kontextfenster riesig ist, hinken die Token-pro-Sekunde-Raten einigen inferenzoptimierten Closed-Source-Gegenstücken hinterher, was sich möglicherweise auf Echtzeitanwendungen auswirkt.
Betriebsaufwand: Selbst gehostete MoE-Modelle erfordern eine sorgfältige Orchestrierung (fachmännisches Routing, Speicherverwaltung), um Leistungsengpässe und Kostenüberschreitungen zu vermeiden.
Welche Infrastrukturinvestitionen sind erforderlich?
- Rechenleistung: Selbst mit MoE-Effizienz erfordert das Hosten der Standardvariante von GLM-4.5 GPUs mit ≥80 GB Speicher und robuste NVLink-Verbindungen für Inferenz mit geringer Latenz.
- Feinabstimmungsaufwand: Die Anpassung des Modells für domänenspezifische Aufgaben kann erhebliche GPU-Zyklen erfordern, wodurch die Vorlaufkosten steigen, bevor Einsparungen bei der Token-Abrechnung sichtbar werden.
- Instandhaltung: Bei On-Premise-Bereitstellungen wird die Verantwortung für Updates, Sicherheitspatches und Skalierung vom Anbieter auf interne DevOps-Teams verlagert.
Wie können Sie mit GLM‑4.5 beginnen?
Der Einstieg in die GLM-4.5-Integration erfordert einige einfache Schritte – insbesondere angesichts des Open-Source-Playbooks und der umfassenden Unterstützung durch Drittanbieter.
Welche APIs und Plattformen unterstützen GLM‑4.5?
- CometAPI API: Vollständig OpenAI-kompatibler Endpunkt mit SDKs in Python, JavaScript und Java.
- Direkter Z.ai-Endpunkt: Bietet offiziellen Support und Early-Access-Funktionen wie Multi-Agent-Orchestrierung.
- Gemeinschaftsspiegel: Schnell wachsender Host von Open-Source-Laufzeiten (z. B. Ollama, AutoGPT-CLI), die lokale Inferenz ermöglichen.
Wo können Entwickler Tools und Dokumentation finden?
- Offizielle Z.ai-Dokumente: Umfassende Anleitungen zur Installation, schnellen technischen Planung und MoE-Optimierung.
- GitHub-Repositorys: Beispiel-Notebooks für Codegenerierung, Retrieval‑Augmented Generation (RAG) und Agenten-Frameworks, die mit den wichtigsten Orchestrierungstools kompatibel sind.
- Community-Foren: Aktive Diskussionsforen auf Plattformen wie Hugging Face, wo Praktiker Feinabstimmungsrezepte, Prompt-Bibliotheken und Leistungsbenchmarks austauschen.
Fazit
Die GLM-4.5-Serie setzt in der heutigen, hart umkämpften KI-Landschaft ein starkes Zeichen: ein unübertroffenes Preis-Leistungs-Verhältnis für Entwickler, Unternehmen und Forschungseinrichtungen gleichermaßen. Mit Token-Preisen von nur 0.11 $ pro Million Input-Token und 0.28 $ pro Million Output-Token – zusätzlich reduziert durch einen Aktionsrabatt von 50 Prozent – und einer Benchmark-Leistung, die mit größeren proprietären Modellen mithalten oder diese sogar übertrifft, bietet GLM-4.5 einen erheblichen ROI für codezentrierte Anwendungen, Long-Form-Verständnis und agentenbasierte Workflows.
Erste Schritte
CometAPI ist eine einheitliche API-Plattform, die über 500 KI-Modelle führender Anbieter – wie die GPT-Reihe von OpenAI, Gemini von Google, Claude von Anthropic, Midjourney, Suno und weitere – in einer einzigen, entwicklerfreundlichen Oberfläche vereint. Durch konsistente Authentifizierung, Anforderungsformatierung und Antwortverarbeitung vereinfacht CometAPI die Integration von KI-Funktionen in Ihre Anwendungen erheblich. Ob Sie Chatbots, Bildgeneratoren, Musikkomponisten oder datengesteuerte Analyse-Pipelines entwickeln – CometAPI ermöglicht Ihnen schnellere Iterationen, Kostenkontrolle und Herstellerunabhängigkeit – und gleichzeitig die neuesten Erkenntnisse des KI-Ökosystems zu nutzen.
Entwickler können zugreifen GLM-4.5 Air API kombiniert mit einem nachhaltigen Materialprofil. GLM‑4.5 API - durch Konsolidierung, CometAPIDie aktuellste Version des Claude-Modells entspricht dem Veröffentlichungsdatum des Artikels. Erkunden Sie zunächst die Funktionen des Modells im Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bieten einen Preis weit unter dem offiziellen Preis an, um Ihnen bei der Integration zu helfen.