

Der Einstieg mit Gemini 2.5 Flash-Lite über CometAPI bietet Ihnen die spannende Möglichkeit, eines der kosteneffizientesten und latenzärmsten generativen KI-Modelle zu nutzen, die derzeit verfügbar sind. Dieser Leitfaden kombiniert die neuesten Ankündigungen von Google DeepMind, detaillierte Spezifikationen aus der Vertex AI-Dokumentation und praktische Integrationsschritte mit CometAPI, damit Sie schnell und effektiv einsatzbereit sind.
Was ist Gemini 2.5 Flash-Lite und warum sollten Sie es in Betracht ziehen?
Übersicht der Gemini 2.5-Familie
Mitte Juni 2025 veröffentlichte Google DeepMind offiziell die Gemini 2.5-Serie, einschließlich stabiler GA-Versionen von Gemini 2.5 Pro und Gemini 2.5 Flash sowie der Vorschau auf ein brandneues, leichtes Modell: Gemini 2.5 Flash-Lite. Die 2.5-Serie wurde entwickelt, um Geschwindigkeit, Kosten und Leistung in Einklang zu bringen und repräsentiert Googles Bestreben, ein breites Spektrum an Anwendungsfällen abzudecken – von anspruchsvollen Forschungsaufgaben bis hin zu groß angelegten, kostensensiblen Implementierungen.
Hauptmerkmale von Flash-Lite
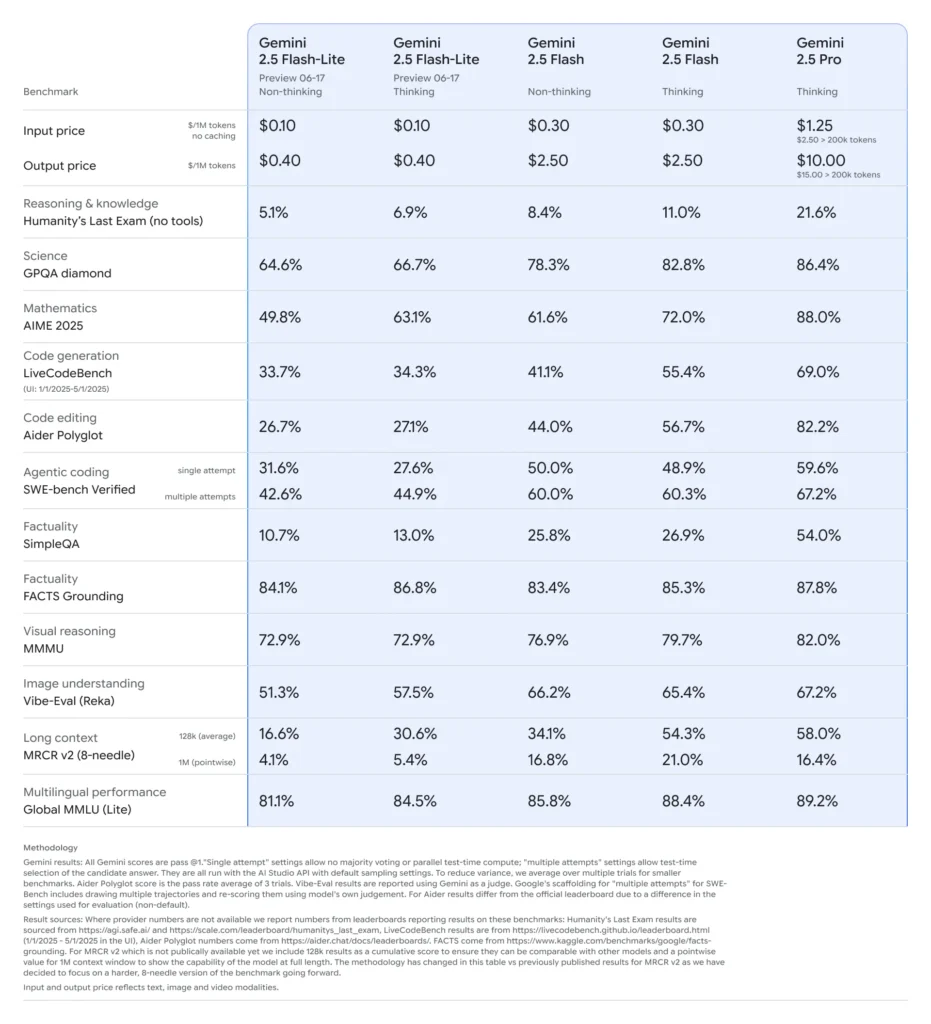
Flash-Lite zeichnet sich durch multimodale Funktionen (Text, Bilder, Audio, Video) bei extrem geringer Latenz aus, mit einem Kontextfenster, das bis zu eine Million Token unterstützt, sowie mit Tool-Integrationen, darunter Google-Suche, Codeausführung und Funktionsaufrufe. Entscheidend ist, dass Flash-Lite eine „Gedankenbudget“-Steuerung einführt, die es Entwicklern ermöglicht, durch die Anpassung eines internen Token-Budgetparameters zwischen Argumentationstiefe und Reaktionszeit sowie Kosten abzuwägen.
Positionierung in der Modellpalette
Im Vergleich zu seinen Geschwistern liegt Flash-Lite an der Pareto-Grenze der Kosteneffizienz: Mit einem Preis von ca. 0.10 $ pro Million Eingabe-Token und 0.40 $ pro Million Ausgabe-Token in der Vorschauphase unterbietet es sowohl Flash (0.30 $/2.50 $) als auch Pro (1.25 $/10 $), behält aber gleichzeitig den Großteil der multimodalen Fähigkeiten und Funktionsaufrufunterstützung bei. Dadurch eignet sich Flash-Lite ideal für Aufgaben mit hohem Volumen und geringer Komplexität wie Zusammenfassung, Klassifizierung und einfache Konversationsagenten.
Warum sollten Entwickler Gemini 2.5 Flash-Lite in Betracht ziehen?
Leistungsbenchmarks und Praxistests
Im direkten Vergleich zeigte Flash-Lite:
- 2× schnellerer Durchsatz als Gemini 2.5 Flash bei Klassifizierungsaufgaben.
- 3-fache Kostenersparnis für Zusammenfassungspipelines im Unternehmensmaßstab.
- Wettbewerbsfähige Genauigkeit bei Logik-, Mathematik- und Code-Benchmarks, die früheren Flash-Lite-Vorschauen entsprechen oder diese übertreffen.
Ideale Anwendungsfälle
- Chatbots mit hohem Volumen: Bieten Sie Millionen von Benutzern konsistente Gesprächserlebnisse mit geringer Latenz.
- Automatisierte Generierung von Inhalten: Skalieren Sie die Zusammenfassung, Übersetzung und Erstellung von Mikrokopien von Dokumenten.
- Such- und Empfehlungspipelines: Nutzen Sie schnelle Schlussfolgerungen für die Personalisierung in Echtzeit.
- Stapelverarbeitung von Daten: Kommentieren Sie große Datensätze mit minimalem Rechenaufwand.
Wie erhalten und verwalten Sie API-Zugriff für Gemini 2.5 Flash-Lite über CometAPI?
Warum CometAPI als Ihr Gateway verwenden?
CometAPI aggregiert über 500 KI-Modelle – einschließlich der Gemini-Serie von Google – unter einem einheitlichen REST-Endpunkt und vereinfacht so die Authentifizierung, Ratenbegrenzung und Abrechnung zwischen verschiedenen Anbietern. Anstatt mit mehreren Basis-URLs und API-Schlüsseln zu jonglieren, richten Sie alle Anfragen an https://api.cometapi.com/v1, geben Sie das Zielmodell in der Nutzlast an und verwalten Sie die Nutzung über ein einziges Dashboard.
Voraussetzungen und Anmeldung
- Einloggen in cometapi.comWenn Sie noch nicht unser Benutzer sind, registrieren Sie sich bitte zuerst
- Holen Sie sich den API-Schlüssel für die Zugangsdaten der Schnittstelle. Klicken Sie im persönlichen Bereich beim API-Token auf „Token hinzufügen“, holen Sie sich den Token-Schlüssel: sk-xxxxx und senden Sie ihn ab.
- Holen Sie sich die URL dieser Site: https://api.cometapi.com/
Verwalten Ihrer Token und Kontingente
Das Dashboard von CometAPI bietet einheitliche Token-Kontingente, die von Google, OpenAI, Anthropic und anderen Modellen gemeinsam genutzt werden können. Nutzen Sie die integrierten Überwachungstools, um Nutzungswarnungen und Ratenbegrenzungen festzulegen, damit Sie Ihre Budgetzuteilungen nie überschreiten oder unerwartete Kosten entstehen.
Wie konfigurieren Sie Ihre Entwicklungsumgebung für die CometAPI-Integration?
Installieren der erforderlichen Abhängigkeiten
Installieren Sie für die Python-Integration die folgenden Pakete:
pip install openai requests pillow
- öffnen: Kompatibles SDK für die Kommunikation mit CometAPI.
- Zugriffe: Für HTTP-Vorgänge wie das Herunterladen von Bildern.
- Kissen: Für die Bildverarbeitung beim Senden multimodaler Eingaben.
Initialisieren des CometAPI-Clients
Verwenden Sie Umgebungsvariablen, um Ihren API-Schlüssel aus dem Quellcode herauszuhalten:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Diese Client-Instanz kann nun jedes unterstützte Modell ansprechen, indem Sie seine ID angeben (z. B. gemini-2.5-flash-lite-preview-06-17) in Ihren Anfragen.
Konfigurieren des Gedankenbudgets und anderer Parameter
Wenn Sie eine Anfrage senden, können Sie optionale Parameter angeben:
- Temperatur/top_p: Kontrollieren Sie die Zufälligkeit bei der Generierung.
- Kandidatenanzahl: Anzahl der alternativen Ausgänge.
- max_tokens: Obergrenze für Ausgabetoken.
- Gedankenbudget: Benutzerdefinierter Parameter für Flash-Lite, um Tiefe gegen Geschwindigkeit und Kosten abzuwägen.
Wie sieht eine einfache Anfrage an Gemini 2.5 Flash-Lite über CometAPI aus?
Nur-Text-Beispiel
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Dieser Aufruf gibt in weniger als 200 ms eine prägnante Zusammenfassung zurück, ideal für Chatbots oder Echtzeit-Analyse-Pipelines.
Beispiel für multimodale Eingabe
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite verarbeitet bis zu 7 MB große Bilder und gibt kontextbezogene Beschreibungen zurück, sodass es sich für das Dokumentverständnis, die UI-Analyse und die automatisierte Berichterstellung eignet.
Wie können Sie erweiterte Funktionen wie Streaming und Funktionsaufrufe nutzen?
Streaming-Antworten für Echtzeitanwendungen
Verwenden Sie für Chatbot-Schnittstellen oder Live-Untertitel die Streaming-API:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Dadurch werden Teilausgaben bereitgestellt, sobald sie verfügbar sind, wodurch die wahrgenommene Latenz in interaktiven Benutzeroberflächen reduziert wird.
Funktionsaufruf für strukturierte Datenausgabe
Definieren Sie JSON-Schemas, um strukturierte Antworten zu erzwingen:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Dieser Ansatz garantiert JSON-kompatible Ausgaben und vereinfacht nachgelagerte Datenpipelines und Integrationen.
Wie optimieren Sie Leistung, Kosten und Zuverlässigkeit bei der Verwendung von Gemini 2.5 Flash-Lite?
Gedankenbudget-Tuning
Mit dem Gedankenbudget-Parameter von Flash-Lite können Sie den „kognitiven Aufwand“ des Modells steuern. Ein niedriges Budget (z. B. 0) priorisiert Geschwindigkeit und Kosten, während höhere Werte zu tieferen Schlussfolgerungen auf Kosten von Latenz und Tokens führen.
Verwalten von Token-Limits und Durchsatz
- Eingabe-Tokens: Bis zu 1,048,576 Token pro Anfrage.
- Ausgabetoken: Standardlimit von 65,536 Token.
- Multimodale Eingaben: Bis zu 500 MB für Bild-, Audio- und Video-Assets.
Implementieren Sie clientseitiges Batching für Workloads mit hohem Volumen und nutzen Sie die automatische Skalierung von CometAPI, um Spitzenverkehr ohne manuelles Eingreifen zu bewältigen.
Kosteneffizienzstrategien
- Bündeln Sie Aufgaben mit geringer Komplexität auf Flash-Lite und reservieren Sie Pro oder Standard-Flash für anspruchsvolle Aufgaben.
- Verwenden Sie Ratenbegrenzungen und Budgetwarnungen im CometAPI-Dashboard, um außer Kontrolle geratene Ausgaben zu verhindern.
- Überwachen Sie die Nutzung nach Modell-ID, um die Kosten pro Anfrage zu vergleichen und Ihre Routing-Logik entsprechend anzupassen.
Was sind Best Practices und die nächsten Schritte nach der ersten Integration?
Überwachung, Protokollierung und Sicherheit
- Protokollierung: Erfassen Sie Anforderungs-/Antwortmetadaten (Zeitstempel, Latenzen, Token-Nutzung) für Leistungsprüfungen.
- Warnmeldungen: Richten Sie Schwellenwertbenachrichtigungen für Fehlerraten oder Kostenüberschreitungen in CometAPI ein.
- Sicherheit: Rotieren Sie API-Schlüssel regelmäßig und speichern Sie sie in sicheren Tresoren oder Umgebungsvariablen.
Gängige Verwendungsmuster
- Chatbots: Verwenden Sie Flash-Lite für schnelle Benutzerabfragen und greifen Sie für komplexe Folgevorgänge auf Pro zurück.
- Dokumentenverarbeitung: Stapelanalysen von PDF- oder Bilddateien über Nacht mit niedrigerem Budget.
- Echtzeit-Analyse: Streamen Sie Finanz- oder Betriebsdaten für sofortige Einblicke über die Streaming-API.
Weiter erkunden
- Experimentieren Sie mit hybriden Eingabeaufforderungen: Kombinieren Sie Text- und Bildeingaben für einen umfassenderen Kontext.
- Erstellen Sie einen RAG-Prototyp (Retrieval-Augmented Generation) durch die Integration von Vektorsuchtools mit Gemini 2.5 Flash-Lite.
- Führen Sie einen Benchmark mit Angeboten von Wettbewerbern durch (z. B. GPT-4.1, Claude Sonnet 4), um Kosten- und Leistungskompromisse zu validieren.
Skalierung in der Produktion
- Nutzen Sie die Enterprise-Stufe von CometAPI für dedizierte Kontingentpools und SLA-Garantien.
- Implementieren Sie Blue-Green-Bereitstellungsstrategien, um neue Eingabeaufforderungen oder Budgets zu testen, ohne Live-Benutzer zu stören.
- Überprüfen Sie regelmäßig die Modellnutzungsmetriken, um Möglichkeiten für weitere Kosteneinsparungen oder Qualitätsverbesserungen zu ermitteln.
Erste Schritte
CometAPI bietet eine einheitliche REST-Schnittstelle, die Hunderte von KI-Modellen aggregiert – unter einem konsistenten Endpunkt, mit integrierter API-Schlüsselverwaltung, Nutzungskontingenten und Abrechnungs-Dashboards. Anstatt mit mehreren Anbieter-URLs und Anmeldeinformationen zu jonglieren.
Entwickler können zugreifen Gemini 2.5 Flash-Lite (Vorschau) API(Modell: gemini-2.5-flash-lite-preview-06-17) Durch CometAPIDie neuesten Modelle sind zum Veröffentlichungsdatum des Artikels aufgeführt. Erkunden Sie zunächst die Funktionen des Modells im Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bieten einen Preis weit unter dem offiziellen Preis an, um Ihnen bei der Integration zu helfen.
Integrieren Sie Gemini 2.5 Flash-Lite über CometAPI in nur wenigen Schritten in Ihre Anwendungen und profitieren Sie von einer leistungsstarken Kombination aus Geschwindigkeit, Kosteneffizienz und multimodaler Intelligenz. Wenn Sie die oben genannten Richtlinien – Einrichtung, grundlegende Anfragen, erweiterte Funktionen und Optimierung – befolgen, sind Sie bestens aufgestellt, um Ihren Nutzern KI-Erlebnisse der nächsten Generation zu bieten. Die Zukunft kosteneffizienter, leistungsstarker KI ist da: Starten Sie noch heute mit Gemini 2.5 Flash-Lite.