

Im Zeitraum 2025–2026 konsolidierte sich die Landschaft der AI-Tools weiter: Gateway-APIs (wie CometAPI) wurden ausgebaut, um OpenAI-ähnlichen Zugriff auf Hunderte von Modellen bereitzustellen, während Endnutzer-LLM-Apps (wie AnythingLLM) ihren „Generic OpenAI“-Provider weiter verbesserten, sodass Desktop- und Local-First-Apps jeden OpenAI-kompatiblen Endpoint aufrufen können. Dadurch ist es heute unkompliziert, AnythingLLM-Datenverkehr über CometAPI zu leiten und von Modellauswahl, Kostenrouting und einheitlicher Abrechnung zu profitieren — und dabei weiterhin die lokale UI sowie die RAG-/Agenten-Funktionen von AnythingLLM zu nutzen.
Was ist AnythingLLM und warum sollte man es mit CometAPI verbinden?
Was ist AnythingLLM?
AnythingLLM ist eine Open-Source-All-in-One-AI-Anwendung und ein lokaler/Cloud-Client zum Erstellen von Chat-Assistenten, Retrieval-Augmented-Generation-(RAG)-Workflows und LLM-gesteuerten Agenten. Es bietet eine elegante UI, eine Entwickler-API, Workspace-/Agenten-Funktionen und Unterstützung für lokale sowie Cloud-LLMs — standardmäßig auf Datenschutz ausgelegt und über Plugins erweiterbar. AnythingLLM stellt einen Generic OpenAI-Provider bereit, über den es mit OpenAI-kompatiblen LLM-APIs kommunizieren kann.
Was ist CometAPI?
CometAPI ist eine kommerzielle API-Aggregationsplattform, die 500+ AI-Modelle über eine OpenAI-ähnliche REST-Schnittstelle und einheitliche Abrechnung bereitstellt. In der Praxis können Sie damit Modelle mehrerer Anbieter (OpenAI, Anthropic, Google/Gemini-Varianten, Bild-/Audio-Modelle usw.) über dieselben https://api.cometapi.com/v1-Endpoints und einen einzigen API-Schlüssel (Format sk-xxxxx) aufrufen. CometAPI unterstützt standardmäßige OpenAI-ähnliche Endpoints wie /v1/chat/completions, /v1/embeddings usw., was die Anpassung von Tools erleichtert, die bereits OpenAI-kompatible APIs unterstützen.
Warum AnythingLLM mit CometAPI integrieren?
Drei praktische Gründe:
- Modellauswahl & Anbieterflexibilität: AnythingLLM kann über seinen Generic-OpenAI-Wrapper „jedes OpenAI-kompatible“ LLM verwenden. Wenn dieser Wrapper auf CometAPI zeigt, erhalten Sie sofortigen Zugriff auf Hunderte von Modellen, ohne die UI oder Abläufe von AnythingLLM zu ändern.
- Kosten-/Betriebsoptimierung: Mit CometAPI können Sie Modelle zentral wechseln (oder auf günstigere umstellen), um Kosten zu kontrollieren, und behalten eine einheitliche Abrechnung, statt mehrere Provider-Schlüssel verwalten zu müssen.
- Schnelleres Experimentieren: Sie können verschiedene Modelle (z. B.
gpt-4o,gpt-4.5, Claude-Varianten oder Open-Source-Multimodal-Modelle) über dieselbe AnythingLLM-UI per A/B-Test vergleichen — nützlich für Agenten, RAG-Antworten, Zusammenfassungen und multimodale Aufgaben.
Welche Umgebung und Voraussetzungen müssen Sie vor der Integration vorbereiten?
System- & Softwareanforderungen (auf hoher Ebene)
- Desktop oder Server mit AnythingLLM (Windows, macOS, Linux) — Desktop-Installation oder selbstgehostete Instanz. Stellen Sie sicher, dass Sie eine aktuelle Version verwenden, die die Einstellungen LLM Preferences / AI Providers bereitstellt.
- CometAPI-Konto und ein API-Schlüssel (das Geheimnis im Stil
sk-xxxxx). Diesen verwenden Sie im Generic-OpenAI-Provider von AnythingLLM. - Netzwerkverbindung von Ihrem Rechner zu
https://api.cometapi.com(keine Firewall, die ausgehendes HTTPS blockiert). - Optional, aber empfohlen: eine aktuelle Python- oder Node-Umgebung zum Testen (Python 3.10+ oder Node 18+), curl und ein HTTP-Client (Postman / HTTPie), um CometAPI zu prüfen, bevor Sie es mit AnythingLLM verbinden.
AnythingLLM-spezifische Voraussetzungen
Der Generic OpenAI-LLM-Provider ist der empfohlene Weg für Endpoints, die die API-Oberfläche von OpenAI nachbilden. In der Dokumentation von AnythingLLM wird darauf hingewiesen, dass dieser Provider sich an Entwickler richtet und Sie die von Ihnen angegebenen Eingaben verstehen sollten. Wenn Sie Streaming verwenden oder Ihr Endpoint kein Streaming unterstützt, enthält AnythingLLM eine Einstellung zum Deaktivieren von Streaming für Generic OpenAI.
Sicherheits- & Betriebscheckliste
- Behandeln Sie den CometAPI-Schlüssel wie jedes andere Geheimnis — committen Sie ihn nicht in Repositories; speichern Sie ihn nach Möglichkeit in OS-Keychains oder Umgebungsvariablen.
- Wenn Sie sensible Dokumente in RAG verwenden möchten, stellen Sie sicher, dass die Datenschutzgarantien des Endpoints Ihre Compliance-Anforderungen erfüllen (prüfen Sie die Dokumentation/Nutzungsbedingungen von CometAPI).
- Legen Sie Max-Tokens- und Context-Window-Grenzen fest, um unkontrollierte Kosten zu vermeiden.
Wie konfigurieren Sie AnythingLLM zur Verwendung mit CometAPI (Schritt für Schritt)?
Nachfolgend finden Sie eine konkrete Schrittfolge — gefolgt von Beispiel-Umgebungsvariablen und Code-Snippets zum Testen der Verbindung, bevor Sie die Einstellungen in der AnythingLLM-UI speichern.
Schritt 1 — Holen Sie sich Ihren CometAPI-Schlüssel
- Registrieren Sie sich bei CometAPI oder melden Sie sich an.
- Navigieren Sie zu „API Keys“ und erzeugen Sie einen Schlüssel — Sie erhalten eine Zeichenfolge wie
sk-xxxxx. Bewahren Sie sie geheim auf.
Schritt 2 — Prüfen Sie CometAPI mit einer kurzen Anfrage
Verwenden Sie curl oder Python, um einen einfachen Chat-Completion-Endpoint aufzurufen und die Konnektivität zu bestätigen.
Curl-Beispiel
curl -X POST "https://api.cometapi.com/v1/chat/completions" \
-H "Authorization: Bearer sk-xxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o",
"messages": ,
"max_tokens": 50
}'
Wenn dies einen 200-Status und eine JSON-Antwort mit einem choices-Array zurückgibt, funktionieren Ihr Schlüssel und Ihr Netzwerk. (Die Dokumentation von CometAPI zeigt die OpenAI-ähnliche Oberfläche und die Endpoints.)
Python-Beispiel (requests)
import requests
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": "Bearer sk-xxxxx", "Content-Type": "application/json"}
payload = {
"model": "gpt-4o",
"messages": ,
"max_tokens": 64
}
r = requests.post(url, json=payload, headers=headers, timeout=15)
print(r.status_code, r.json())
Schritt 3 — Konfigurieren Sie AnythingLLM (UI)
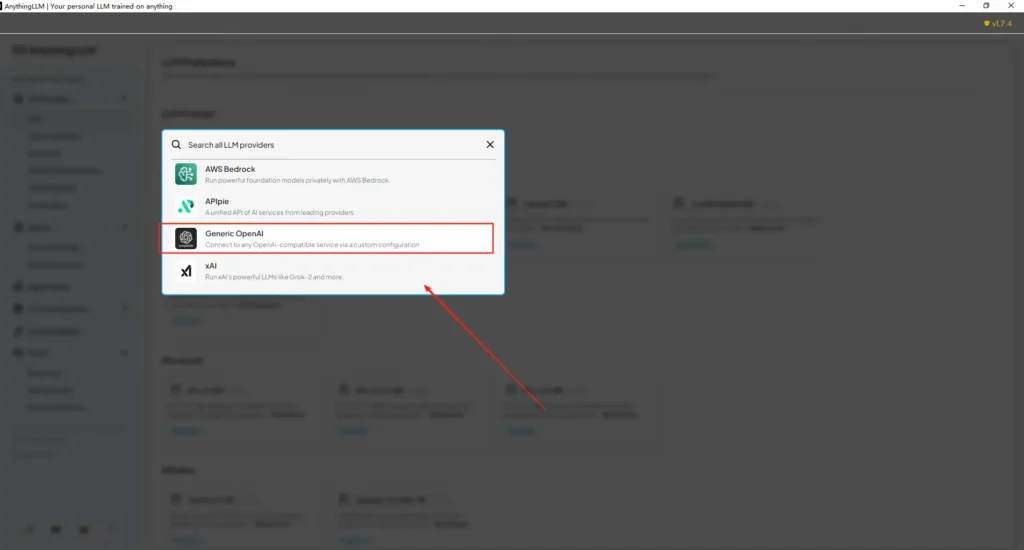
Öffnen Sie AnythingLLM → Settings → AI Providers → LLM Preferences (oder einen ähnlichen Pfad in Ihrer Version). Verwenden Sie den Generic OpenAI-Provider und füllen Sie die Felder wie folgt aus:
API-Konfiguration (Beispiel)
• Öffnen Sie das Einstellungsmenü von AnythingLLM und suchen Sie unter AI Providers nach LLM Preferences.
• Wählen Sie Generic OpenAI als Modellprovider aus und geben Siehttps://api.cometapi.com/v1in das URL-Feld ein.
• Fügen Sie dassk-xxxxxvon CometAPI in das API-Key-Eingabefeld ein. Tragen Sie Token Context Window und Max Tokens entsprechend dem tatsächlichen Modell ein. Auf dieser Seite können Sie auch Modellnamen anpassen, z. B. das Modellgpt-4ohinzufügen.
Dies entspricht der AnythingLLM-Anleitung zu „Generic OpenAI“ (Developer-Wrapper) sowie dem Ansatz von CometAPI mit OpenAI-kompatibler Basis-URL.
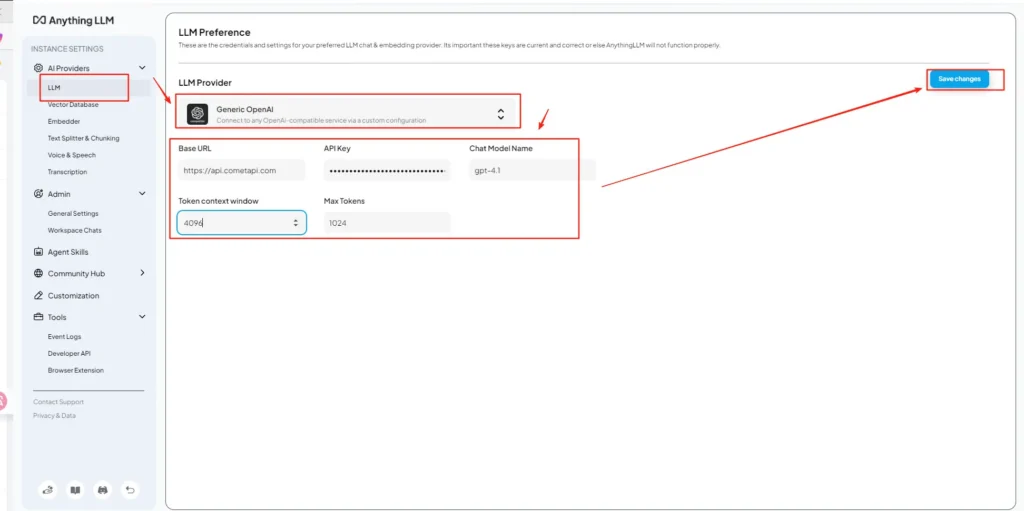
Schritt 4 — Modellnamen & Token-Limits festlegen
Fügen Sie auf demselben Einstellungsbildschirm Modellnamen genau so hinzu oder passen Sie sie an, wie CometAPI sie veröffentlicht (z. B. gpt-4o, minimax-m2, kimi-k2-thinking), damit die AnythingLLM-UI diese Modelle den Benutzern anzeigen kann. CometAPI veröffentlicht Modell-Strings für jeden Anbieter.
Schritt 5 — In AnythingLLM testen
Starten Sie einen neuen Chat oder verwenden Sie einen vorhandenen Workspace, wählen Sie den Generic-OpenAI-Provider aus (falls Sie mehrere Provider haben), wählen Sie einen der hinzugefügten CometAPI-Modellnamen und führen Sie einen einfachen Prompt aus. Wenn Sie schlüssige Vervollständigungen erhalten, ist die Integration erfolgreich.
Wie AnythingLLM diese Einstellungen intern verwendet
Der Generic-OpenAI-Wrapper von AnythingLLM erstellt OpenAI-ähnliche Anfragen (/v1/chat/completions, /v1/embeddings). Sobald Sie also die Basis-URL festlegen und den CometAPI-Schlüssel angeben, leitet AnythingLLM Chats, Agentenaufrufe und Embedding-Anfragen transparent über CometAPI weiter. Wenn Sie AnythingLLM-Agenten verwenden (die @agent-Flows), übernehmen diese denselben Provider.
Was sind Best Practices und mögliche Fallstricke?
Best Practices
- Verwenden Sie modellgerechte Kontexteinstellungen: Passen Sie in AnythingLLM Token Context Window und Max Tokens an das Modell an, das Sie auf CometAPI auswählen. Abweichungen führen zu unerwarteter Abschneidung oder fehlgeschlagenen Aufrufen.
- Sichern Sie Ihre API-Schlüssel: Speichern Sie CometAPI-Schlüssel in Umgebungsvariablen und/oder Kubernetes-/Secret-Managern; checken Sie sie niemals in git ein. AnythingLLM speichert Schlüssel in seinen lokalen Einstellungen, wenn Sie sie in der UI eingeben — behandeln Sie den Host-Speicher daher als sensibel.
- Beginnen Sie für Experimentier-Workflows mit günstigeren / kleineren Modellen: Nutzen Sie CometAPI, um kostengünstigere Modelle für die Entwicklung zu testen, und reservieren Sie Premium-Modelle für die Produktion. CometAPI wirbt ausdrücklich mit Kostenumschaltung und einheitlicher Abrechnung.
- Überwachen Sie die Nutzung & setzen Sie Warnungen: CometAPI bietet Nutzungs-Dashboards — richten Sie Budgets/Warnungen ein, um Überraschungsrechnungen zu vermeiden.
- Testen Sie Agenten und Tools isoliert: AnythingLLM-Agenten können Aktionen auslösen; testen Sie sie zunächst mit sicheren Prompts und auf Staging-Instanzen.
Häufige Fallstricke
- Konflikte zwischen UI und
.env: Beim Self-Hosting können UI-Einstellungen.env-Änderungen überschreiben (und umgekehrt). Prüfen Sie die generierte/app/server/.env, wenn Dinge nach einem Neustart zurückgesetzt werden. In Community-Issues wird über Rücksetzungen vonLLM_PROVIDERberichtet. - Nicht übereinstimmende Modellnamen: Wenn Sie einen Modellnamen verwenden, der auf CometAPI nicht verfügbar ist, erhalten Sie vom Gateway einen 400-/404-Fehler. Prüfen Sie immer die verfügbaren Modelle in der CometAPI-Modellliste.
- Token-Limits & Streaming: Wenn Sie Streaming-Antworten benötigen, vergewissern Sie sich, dass das CometAPI-Modell Streaming unterstützt (und dass Ihre AnythingLLM-UI-Version dies unterstützt). Manche Provider unterscheiden sich in der Streaming-Semantik.
Welche realen Anwendungsfälle ermöglicht diese Integration?
Retrieval-Augmented Generation (RAG)
Verwenden Sie die Dokument-Loader + Vektor-DB von AnythingLLM mit CometAPI-LLMs, um kontextbezogene Antworten zu erzeugen. Sie können mit günstigen Embedding- und teureren Chat-Modellen experimentieren oder alles auf CometAPI für eine einheitliche Abrechnung belassen. Die RAG-Flows von AnythingLLM sind eine zentrale integrierte Funktion.
Agentenautomatisierung
AnythingLLM unterstützt @agent-Workflows (Seiten durchsuchen, Tools aufrufen, Automatisierungen ausführen). Wenn die LLM-Aufrufe der Agenten über CometAPI geleitet werden, haben Sie Modellauswahl für Kontroll-/Interpretationsschritte, ohne den Agentencode ändern zu müssen.
Multi-Model-A/B-Tests und Kostenoptimierung
Wechseln Sie Modelle pro Workspace oder Funktion (z. B. gpt-4o für Produktionsantworten, gpt-4o-mini für Entwicklung). CometAPI macht Modellwechsel trivial und zentralisiert die Kosten.
Multimodale Pipelines
CometAPI bietet Bild-, Audio- und spezialisierte Modelle. Die multimodale Unterstützung von AnythingLLM (über Provider) plus die Modelle von CometAPI ermöglichen Bildbeschriftung, multimodale Zusammenfassung oder Audio-Transkriptions-Workflows über dieselbe Schnittstelle.
Fazit
CometAPI positioniert sich weiterhin als Multi-Model-Gateway (500+ Modelle, OpenAI-ähnliche API) — was es zu einem natürlichen Partner für Apps wie AnythingLLM macht, die bereits einen Generic-OpenAI-Provider unterstützen. Ebenso machen der Generic-Provider von AnythingLLM und aktuelle Konfigurationsoptionen die Verbindung zu solchen Gateways unkompliziert. Diese Konvergenz vereinfacht Experimente und Produktionsmigrationen Ende 2025.
So starten Sie mit Comet API
CometAPI ist eine einheitliche API-Plattform, die über 500 KI-Modelle führender Anbieter — wie OpenAIs GPT-Serie, Google Gemini, Anthropic Claude, Midjourney, Suno und viele mehr — in einer einzigen, entwicklerfreundlichen Schnittstelle bündelt. Durch konsistente Authentifizierung, Anfrageformatierung und Antwortverarbeitung vereinfacht CometAPI die Integration von KI-Funktionen in Ihre Anwendungen erheblich. Ganz gleich, ob Sie Chatbots, Bildgeneratoren, Musikkomponisten oder datengesteuerte Analyse-Pipelines entwickeln — CometAPI ermöglicht schnellere Iteration, bessere Kostenkontrolle und Anbieterunabhängigkeit, während Sie gleichzeitig von den neuesten Durchbrüchen im KI-Ökosystem profitieren.
Um zu beginnen, erkunden Sie die Modellfunktionen von CometAPI im Playground und lesen Sie den API guide für detaillierte Anweisungen. Bitte stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI offer einen Preis, der weit unter dem offiziellen Preis liegt, um Sie bei der Integration zu unterstützen.
Bereit loszulegen? → Melden Sie sich noch heute bei CometAPI an !
Wenn Sie mehr Tipps, Anleitungen und Neuigkeiten zu KI erfahren möchten, folgen Sie uns auf VK, X und Discord!