

DeepSeek-V3.1 ist das neueste hybride Reasoning-Modell von DeepSeek. Es unterstützt sowohl einen schnellen Chat-Modus ohne Denken als auch einen bewussteren Modus mit Denken/Reasoner. Es bietet umfangreichen Kontext (bis zu 128 KB), strukturierte Ausgaben und Funktionsaufrufe und ist direkt über die OpenAI-kompatible API von DeepSeek, einen Anthropic-kompatiblen Endpunkt oder CometAPI zugänglich. Im Folgenden erkläre ich Ihnen das Modell, die wichtigsten Benchmarks und Kosten, erweiterte Funktionen (Funktionsaufrufe, JSON-Ausgaben, Reasoning-Modus) und gebe anschließend konkrete End-to-End-Codebeispiele: direkte DeepSeek-REST-Aufrufe (curl / Node / Python), Nutzung des Anthropic-Clients und Aufrufe über CometAPI.
Was ist DeepSeek-V3.1 und was ist neu in dieser Version?
DeepSeek-V3.1 ist die neueste Version der DeepSeek V3-Familie: eine leistungsstarke, Experten-übergreifende Sprachmodellreihe, die eine Hybrid-Inferenz-Design mit zwei Betriebsmodi – einem schnellen gedankenloser Chat Modus und ein Denken / Vernunft Modus, der Gedankenketten für anspruchsvollere Denkaufgaben und die Verwendung von Agenten/Tools offenlegen kann. Die Version legt den Schwerpunkt auf schnellere Denklatenz, verbesserte Tool-/Agentenfunktionen und eine längere Kontextverarbeitung für Workflows im Dokumentmaßstab.
Wichtige praktische Erkenntnisse:
- Zwei Betriebsarten:
deepseek-chatfür Durchsatz und Kosten,deepseek-reasoner(ein Argumentationsmodell), wenn Sie Gedankenkettenspuren oder eine höhere Argumentationstreue wünschen. - Verbesserte Agenten-/Tool-Handhabung und Tokenizer-/Kontextverbesserungen für lange Dokumente.
- Kontextlänge: bis zu ~128 Token (ermöglicht lange Dokumente, Codebasen, Protokolle).
Benchmark-Durchbruch
DeepSeek-V3.1 zeigte signifikante Verbesserungen bei realen Programmierherausforderungen. In der SWE-Bench Verified-Evaluierung, die misst, wie oft das Modell GitHub-Probleme behebt, um sicherzustellen, dass die Unit-Tests erfolgreich sind, erreichte V3.1 eine Erfolgsquote von 66 %, verglichen mit 45 % für V3-0324 und R1. In der mehrsprachigen Version löste V3.1 54.5 % der Probleme, fast doppelt so viel wie die Erfolgsquote von etwa 30 % der anderen Versionen. In der Terminal-Bench-Evaluierung, die prüft, ob das Modell Aufgaben in einer Live-Linux-Umgebung erfolgreich abschließen kann, war DeepSeek-V3.1 bei 31 % der Aufgaben erfolgreich, verglichen mit 13 % bzw. 6 % für die anderen Versionen. Diese Verbesserungen zeigen, dass DeepSeek-V3.1 bei der Codeausführung und beim Betrieb in realen Tool-Umgebungen zuverlässiger ist.
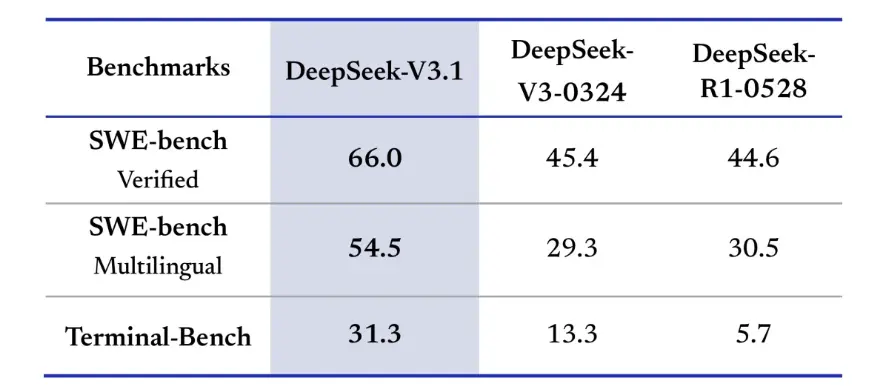
Auch Benchmarks zur Informationsbeschaffung sprechen für DeepSeek-V3.1 beim Browsen, Suchen und Fragenbeantworten. In der BrowseComp-Evaluierung, bei der durch eine Webseite navigiert und Antworten extrahiert werden müssen, beantwortete V3.1 30 % der Fragen richtig, verglichen mit 9 % bei R1. In der chinesischen Version erreichte DeepSeek-V3.1 eine Genauigkeit von 49 % gegenüber 36 % bei R1. Beim Hard Language Exam (HLE) übertraf V3.1 R1 leicht und erreichte eine Genauigkeit von 30 % bzw. 25 %. Bei Deep-Search-Aufgaben wie xbench-DeepSearch, bei denen Informationen aus verschiedenen Quellen synthetisiert werden müssen, erreichte V3.1 71 % gegenüber 1 % für R55. DeepSeek-V3.1 zeigte auch einen kleinen, aber konstanten Vorsprung bei Benchmarks wie (strukturiertes Denken), SimpleQA (Beantwortung sachlicher Fragen) und Seal0 (Beantwortung domänenspezifischer Fragen). Insgesamt übertraf V3.1 R1 bei der Informationsbeschaffung und der Beantwortung einfacher Fragen deutlich.
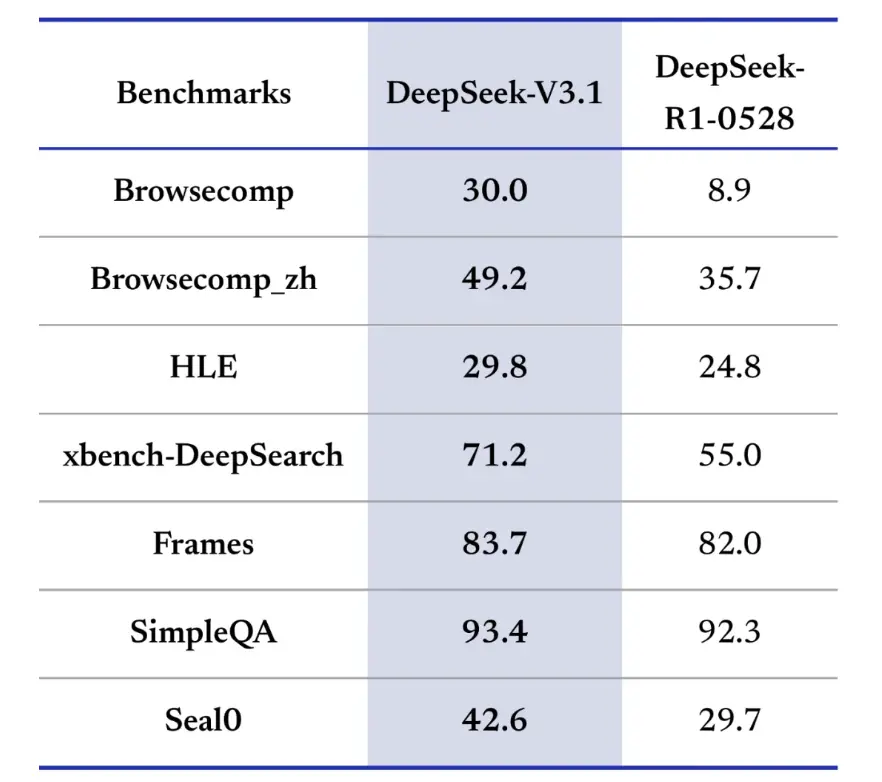
In Bezug auf die Effizienz des Schlussfolgerungsprozesses belegen die Ergebnisse zur Token-Nutzung seine Effektivität. Bei AIME 2025 (einer schwierigen Mathematikprüfung) erreichte V3.1-Think eine Genauigkeit, die mit R1 vergleichbar war oder diese leicht übertraf (88.4 % gegenüber 87.5 %), verwendete aber rund 30 % weniger Token. Bei GPQA Diamond (einer fachübergreifenden Abschlussprüfung) lagen die beiden Modelle nahezu gleichauf (80.1 % gegenüber 81.0 %), aber V3.1 verwendete fast halb so viele Token wie R1. Beim LiveCodeBench-Benchmark, der das Code-Schlussfolgerungsvermögen bewertet, war V3.1 nicht nur genauer (74.8 % gegenüber 73.3 %), sondern auch prägnanter. Dies zeigt, dass V3.1-Think detaillierte Schlussfolgerungen liefern und gleichzeitig Ausführlichkeit vermeiden kann.
Insgesamt stellt V3.1 im Vergleich zu V3-0324 einen deutlichen Generationssprung dar. Im Vergleich zu R1 erreichte V3.1 in fast allen Benchmarks eine höhere Genauigkeit und war bei anspruchsvollen Denkaufgaben effektiver. Der einzige Benchmark, bei dem R1 mithalten konnte, war GPQA, allerdings zu fast doppelt so hohen Kosten.
Wie erhalte ich einen API-Schlüssel und richte ein Entwicklungskonto ein?
Schritt 1: Registrieren Sie sich und erstellen Sie ein Konto
- Besuchen Sie das Entwicklerportal von DeepSeek (DeepSeek-Dokumente/Konsole). Erstellen Sie ein Konto mit Ihrem E-Mail- oder SSO-Anbieter.
- Führen Sie alle vom Portal geforderten Identitätsprüfungen oder Rechnungseinstellungen durch.
Schritt 2: Erstellen Sie einen API-Schlüssel
- Gehen Sie im Dashboard zu API-Keys → Schlüssel erstellen. Benennen Sie Ihren Schlüssel (z. B.
dev-local-01). - Kopieren Sie den Schlüssel und speichern Sie ihn in einem sicheren Geheimnismanager (siehe Best Practices für die Produktion unten).
Tipp: Einige Gateways und Router von Drittanbietern (z. B. CometAPI) ermöglichen Ihnen die Verwendung eines einzigen Gateway-Schlüssels für den Zugriff auf DeepSeek-Modelle. Dies ist nützlich für die Redundanz mehrerer Anbieter (siehe DeepSeek V3.1 API Sektion).
Wie richte ich meine Entwicklungsumgebung (Linux/macOS/Windows) ein?
Dies ist ein einfaches, reproduzierbares Setup für Python und Node.js, das für DeepSeek (OpenAI-kompatible Endpunkte), CometAPI und Anthropic funktioniert.
Voraussetzungen:
- Python 3.10+ (empfohlen), Pip, Virtualenv.
- Node.js 18+ und npm/yarn.
- curl (für schnelle Tests).
Python-Umgebung (Schritt für Schritt)
- Erstellen Sie ein Projektverzeichnis:
mkdir deepseek-demo && cd deepseek-demo
python -m venv .venv
source .venv/bin/activate # macOS / Linux
# .venv\Scripts\activate # Windows PowerShell
- Installieren Sie die Mindestpakete:
pip install --upgrade pip
pip install requests
# Optional: install an OpenAI-compatible client if you prefer one:
pip install openai
- Speichern Sie Ihren API-Schlüssel in Umgebungsvariablen (niemals festschreiben):
export DEEPSEEK_KEY="sk_live_xxx"
export CometAPI_KEY="or_xxx"
export ANTHROPIC_KEY="anthropic_xxx"
(Windows PowerShell verwenden $env:DEEPSEEK_KEY = "…")
Knotenumgebung (Schritt für Schritt)
- Initialisieren:
mkdir deepseek-node && cd deepseek-node
npm init -y
npm install node-fetch dotenv
- Erstellen Sie
.envDatei:
DEEPSEEK_KEY=sk_live_xxx
CometAPI_KEY=or_xxx
ANTHROPIC_KEY=anthropic_xxx
Wie rufe ich DeepSeek-V3.1 direkt auf – Schritt-für-Schritt-Codebeispiele?
Die API von DeepSeek ist OpenAI-kompatibel. Nachfolgend finden Sie copy-paste Beispiele: Curl, Python (Anfragen und OpenAI SDK-Stil) und Node.
Schritt 1: Einfaches Curl-Beispiel
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-chat-v3.1",
"messages": [
{"role":"system","content":"You are a concise engineering assistant."},
{"role":"user","content":"Give a 5-step secure deployment checklist for a Django app."}
],
"max_tokens": 400,
"temperature": 0.0,
"reasoning_enabled": true
}'
Anmerkungen: reasoning_enabled schaltet den Think-Modus um (Herstellerflagge). Der genaue Flaggenname kann je nach Anbieter variieren – überprüfen Sie die Modelldokumentation.
Schritt 2: Python (Anfragen) mit einfacher Telemetrie
import os, requests, time, json
API_KEY = os.environ
URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat-v3.1",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Refactor this Flask function to be testable: ..."}
],
"max_tokens": 600,
"temperature": 0.1,
"reasoning_enabled": True
}
start = time.time()
r = requests.post(URL, headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}, json=payload, timeout=60)
elapsed = time.time() - start
print("Status:", r.status_code, "Elapsed:", elapsed)
data = r.json()
print(json.dumps(data, indent=2))
CometAPI: Völlig kostenloser Zugriff auf DeepSeek V3.1
Für Entwickler, die sofortigen Zugriff ohne Registrierung wünschen, bietet CometAPI eine attraktive Alternative zu DeepSeek V3.1 (Modellname: deepseek-v3-1-250821; deepseek-v3.1). Dieser Gateway-Dienst aggregiert mehrere KI-Modelle über eine einheitliche API, ermöglicht den Zugriff auf DeepSeek und bietet weitere Vorteile, darunter automatisches Failover, Nutzungsanalysen und vereinfachte anbieterübergreifende Abrechnung.
Erstellen Sie zunächst ein CometAPI-Konto unter https://www.cometapi.com/Der gesamte Vorgang dauert nur zwei Minuten und erfordert lediglich die Bestätigung Ihrer E-Mail-Adresse. Nach der Anmeldung generieren Sie im Bereich „API-Schlüssel“ einen neuen Schlüssel. https://www.cometapi.com/ bietet kostenlose Credits für neue Konten und 20 % Rabatt auf den offiziellen API-Preis.
Die technische Implementierung erfordert nur minimale Codeänderungen. Ändern Sie einfach Ihren API-Endpunkt von einer direkten DeepSeek-URL zum CometAPI-Gateway.
Hinweis: Die API unterstützt Streaming (
stream: true),max_tokens, Temperatur, Stoppsequenzen und Funktionsaufruffunktionen ähnlich wie bei anderen OpenAI-kompatiblen APIs.
Wie kann ich DeepSeek mit Anthropic SDKs aufrufen?
DeepSeek bietet einen Anthropic-kompatiblen Endpunkt, sodass Sie Anthropc SDKs oder Claude Code-Tools wiederverwenden können, indem Sie das SDK auf https://api.deepseek.com/anthropic und setzen Sie den Modellnamen auf deepseek-chat (oder deepseek-reasoner sofern unterstützt).
DeepSeek-Modell über die Anthropische API aufrufen
Installieren Sie das Anthropic SDK: pip install anthropic. Konfigurieren Sie Ihre Umgebung:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=YOUR_DEEPSEEK_KEY
Erstellen Sie eine Nachricht:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
system="You are a helpful assistant.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hi, how are you?"
}
]
}
]
)
print(message.content)
Verwenden Sie DeepSeek in Claude Code
Installieren: npm install -g @anthropic-ai/claude-code. Konfigurieren Sie Ihre Umgebung:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=${YOUR_API_KEY}
export ANTHROPIC_MODEL=deepseek-chat
export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chat
Geben Sie das Projektverzeichnis ein und führen Sie den Claude-Code aus:
cd my-project
claude
Verwenden Sie DeepSeek in Claude Code über CometAPI
CometAPI unterstützt Claude Code. Ersetzen Sie nach der Installation beim Konfigurieren der Umgebung einfach die Basis-URL durch https://www.cometapi.com/console/ und den Schlüssel durch den CometAPI-Schlüssel, um das DeepSeek-Modell von CometAPI in Claude Code zu verwenden.
# Navigate to your project folder cd your-project-folder
# Set environment variables (replace sk-... with your actual token)
export ANTHROPIC_AUTH_TOKEN=sk-...
export ANTHROPIC_BASE_URL=https://www.cometapi.com/console/
# Start Claude Code
claude
Anmerkungen:
- DeepSeek ordnet nicht unterstützte anthropische Modellnamen zu
deepseek-chat. - Die anthropische Kompatibilitätsschicht unterstützt
system,messages,temperature, Streaming, Stoppsequenzen und Denkarrays.
Was sind konkrete Best Practices für die Produktion (Sicherheit, Kosten, Zuverlässigkeit)?
Nachfolgend finden Sie empfohlene Produktionsmuster, die für DeepSeek oder jede LLM-Nutzung mit hohem Volumen gelten.
Geheimnisse und Identität
- Speichern Sie API-Schlüssel in einem geheimen Manager (verwenden Sie nicht
.envin der Produktion). Rotieren Sie die Schlüssel regelmäßig und erstellen Sie pro Dienst Schlüssel mit den geringsten Berechtigungen. - Verwenden Sie separate Projekte/Konten für Entwicklung/Staging/Produktion.
Ratenbegrenzungen und Wiederholungsversuche
- Implementierung exponentielles Backoff auf HTTP 429/5xx mit Jitter. Begrenzen Sie die Anzahl der Wiederholungsversuche (z. B. 3 Versuche).
- Verwenden Sie Idempotenzschlüssel für Anfragen, die wiederholt werden können.
Python-Beispiel – Wiederholungsversuch mit Backoff
import time, random, requests
def post_with_retries(url, headers, payload, attempts=3):
for i in range(attempts):
r = requests.post(url, json=payload, headers=headers, timeout=60)
if r.status_code == 200:
return r.json()
if r.status_code in (429, 502, 503, 504):
backoff = (2 ** i) + random.random()
time.sleep(backoff)
continue
r.raise_for_status()
raise RuntimeError("Retries exhausted")
Kostenmanagement
- Einschränkung
max_tokensund vermeiden Sie, versehentlich große Ausgaben anzufordern. - Cache-Modellantworten gegebenenfalls (insbesondere bei wiederholten Eingabeaufforderungen). DeepSeek unterscheidet bei der Preisgestaltung ausdrücklich zwischen Cache-Treffern und Cache-Fehlschlägen – Caching spart Geld.
- Nutzen Sie
deepseek-chatfür routinemäßige kleine Antworten; reservierendeepseek-reasonerfür Fälle, in denen CoT wirklich erforderlich ist (es ist teurer).
Beobachtbarkeit und Protokollierung
- Protokollieren Sie ausschließlich Metadaten zu Anfragen im Klartext (Prompt-Hashes, Token-Anzahl, Latenzen). Vermeiden Sie die Protokollierung vollständiger Benutzerdaten oder vertraulicher Inhalte. Speichern Sie Anfrage-/Antwort-IDs für Support und Abrechnungsabgleich.
- Verfolgen Sie die Token-Nutzung pro Anfrage und legen Sie Budgetierung/Warnungen zu den Kosten offen.
Sicherheits- und Halluzinationskontrollen
- Nutzen Sie Tool-Ausgaben und deterministische Validatoren für alles, was sicherheitskritisch ist (finanziell, rechtlich, medizinisch).
- Für strukturierte Ausgaben verwenden Sie
response_format+JSON-Schema und validieren Sie die Ausgaben, bevor Sie irreversible Aktionen ausführen.
Bereitstellungsmuster
- Führen Sie Modellaufrufe von einem dedizierten Arbeitsprozess aus, um Parallelität und Warteschlangen zu steuern.
- Übertragen Sie schwere Jobs auf asynchrone Worker (Celery, Fargate-Aufgaben, Cloud Run-Jobs) und reagieren Sie mit Fortschrittsanzeigen auf Benutzer.
- Berücksichtigen Sie bei extremen Latenz-/Durchsatzanforderungen die SLAs des Anbieters und ob Sie das Hosting selbst durchführen oder Beschleuniger des Anbieters verwenden möchten.
Schlussbemerkung
DeepSeek-V3.1 ist ein pragmatisches Hybridmodell, das sowohl für schnellen Chat als auch für komplexe Agentenaufgaben entwickelt wurde. Die OpenAI-kompatible API-Form ermöglicht eine einfache Migration für viele Projekte, während die Kompatibilitätsebenen Anthropic und CometAPI die Flexibilität für bestehende Ökosysteme erhöhen. Benchmarks und Community-Berichte zeigen vielversprechende Kosten-Leistungs-Verhältnisse. Wie bei jedem neuen Modell sollten Sie es jedoch vor der vollständigen Produktionseinführung anhand Ihrer realen Workloads (Eingabeaufforderungen, Funktionsaufrufe, Sicherheitsprüfungen, Latenz) validieren.
Auf CometAPI können Sie es sicher ausführen und über eine OpenAI-kompatible API oder benutzerfreundliche Spielplatz, ohne Ratenbegrenzungen.
👉 Stellen Sie DeepSeek-V3.1 jetzt auf CometAPI bereit!
Warum CometAPI verwenden?
- Anbieter-Multiplexing: Wechseln Sie den Anbieter ohne Code-Neuschreibung.
- Einheitliche Abrechnung/Metriken: Wenn Sie mehrere Modelle über CometAPI leiten, erhalten Sie eine einzige Integrationsoberfläche.
- Modellmetadaten: Kontextlänge und aktive Parameter pro Modellvariante anzeigen.