

Anthropics Claude Opus 4.6 erschien im Februar 2026 als klarer, zweckgerichteter Vorstoß hin zu Enterprise-tauglichen Agenten, Wissensarbeit mit Langkontext und stärkerem autonomem Coden. Das Release verbindet ambitionierte Ingenieursarbeit (ein Beta-Kontextmodus mit einer Million Token, eine Fähigkeit zum „adaptiven Denken“ und Funktionen für Teamarbeit zwischen Agenten) mit einer pragmatischen geschäftlichen Entscheidung: Anthropic hat die API-Preise im Einklang mit den bisherigen Modellen der Opus-Familie belassen. Diese Kombination — materiell verbesserte Fähigkeiten ohne sofortigen Preissprung — ist die Schlagzeile.
Was genau ist Claude Opus 4.6?
Claude Opus 4.6 ist Anthropics Flaggschiff der Opus‑Linie: ein großskaliges, auf Unternehmen fokussiertes generatives KI‑Modell, optimiert für agentische Workflows, Coding und Wissensarbeit über lange Horizonte. Anthropic positioniert Opus 4.6 als sein intelligentestes Modell für den Aufbau von Agenten und Automatisierungen — etwas, das nicht nur Anfragen beantwortet, sondern plant, Tools aufruft, Unteragenten koordiniert und mehrstufige Aufgaben über große Codebasen und Dokumentenkorpora hinweg verfolgt.
Anders als verbraucherorientierte Chatbots zielt Opus 4.6 auf Unternehmensintegrationen: Es ist über die claude.ai‑UI, die Claude‑API und über CometAPI verfügbar. Opus 4.6 ist stark bei agentischen Coding‑Aufgaben und Toolaufrufen. Für Unternehmen bedeutet das: Opus 4.6 ist als Drop‑in‑Upgrade für agentische Assistenten, Code‑Migrations‑Tools, Dokumentenprüf‑Pipelines und analytische Workflows positioniert, die einen breiteren Kontext benötigen als typische Chat‑Sitzungen.
Detaillierte Analyse der wichtigsten Neuerungen in Opus 4.6
Eine-Million-Token-Kontext (und praxisnahe Modi)
Opus 4.6 unterstützt ein erweitertes Standard‑Kontextfenster (beworben mit 200K Token, mit einem 1M‑Token‑Kontextfenster in der Beta). Ein Kontextfenster mit einer Million Token ist auf dem Papier transformativ: Es ermöglicht dem Modell, komplette Code‑Repos, lange Schriftsätze, mehrjährige E‑Mail‑Archive oder große Datentabellen in einer einzigen Unterhaltung zu halten — das reduziert den Bedarf an externen Retrieval‑Gerüsten. Anthropic kombiniert das rohe Kontextfenster mit Tools zur „Kontextkomprimierung“, die relevante Informationen verdichten und die Token‑Kosten senken. Kurz: Opus kann tatsächlich mit sehr großen Artefakten arbeiten, ohne sie in Fragmente zu zerschneiden — das vereinfacht den Aufbau langlebiger Agenten.
Warum es wichtig ist: Für Code‑Refactoring, juristische/finanzielle Prüfungen oder Forschungsprojekte, die dokumentübergreifendes Schließen erfordern, reduziert das größere Fenster den Engineering‑Aufwand (weniger Retrievals, weniger Zustandsverwaltung) und verbessert die Kohärenz über sehr lange Begründungsketten.
Adaptives Denken und erweiterte Reasoning‑Steuerung
Opus 4.6 führt das ein, was Anthropic „adaptives Denken“ nennt (eine Weiterentwicklung der früheren Ideen zum „Extended Thinking“). Das ist sowohl eine interne Fähigkeit als auch eine API‑Steuergröße: Entwickler können die „Aufwandsstufen“ und die Planungstiefe des Modells justieren, sodass es für komplizierte Planungen mehr Rechenaufwand betreiben oder bei trivialen Aufgaben kurze, schnelle Antworten liefern kann.
Warum es wichtig ist: In agentischen Workflows addieren sich marginale Qualitätsgewinne: bessere Planung + Koordination bedeuten weniger menschliche Korrekturen und verlässlichere autonome Ausführung.
Was sind „Agententeams“ und agentische Orchestrierung?
Opus 4.6 führt verbesserte Unterstützung für agentische Workflows ein: die Fähigkeit, mehrere Unteragenten zu erzeugen, zu koordinieren und zu beaufsichtigen, die Aufgaben aufteilen und gemeinsam bearbeiten. Anthropics Materialien (und frühe Partnerberichte) betonen, dass Opus proaktiv Unteragenten erstellen, Teilaufgaben zuweisen, ihren Fortschritt überwachen und Strategien bei Bedarf beenden oder umstellen kann — faktisch als leichtgewichtiger Orchestrator für komplexe, mehrstufige Engineering‑ oder Analysearbeiten. Diese enge Verzahnung von Planung, Tool‑Nutzung und Fehlerkorrektur ist ein zentrales Verkaufsargument für stark automatisierte Teams.
API‑ und Tooling‑Verbesserungen für Enterprise‑Integration
Anthropic hat API‑Steuerungen für Komprimierung, Persistenz und Toolaufrufe erweitert. Das Modell unterstützt größere Ausgabelimits (Anthropic nennt bis zu 128K Ausgabetoken), feinere Retrieval‑Semantik und Enterprise‑Integrationen für Microsoft 365 und Entwicklerumgebungen. Das praktische Ergebnis ist weniger Glue‑Code beim Anschließen von Opus an Tabellen, Foliensätze und interne Toolchains. Anthropic hat Opus 4.6 in höherstufige Tools wie Claude Cowork (No‑Code‑Oberflächen) und Updates für Claude Code integriert, sodass auch nicht‑technische Nutzer auf Automatisierung zugreifen können.
Wie schlägt sich Opus 4.6 in Benchmarks?
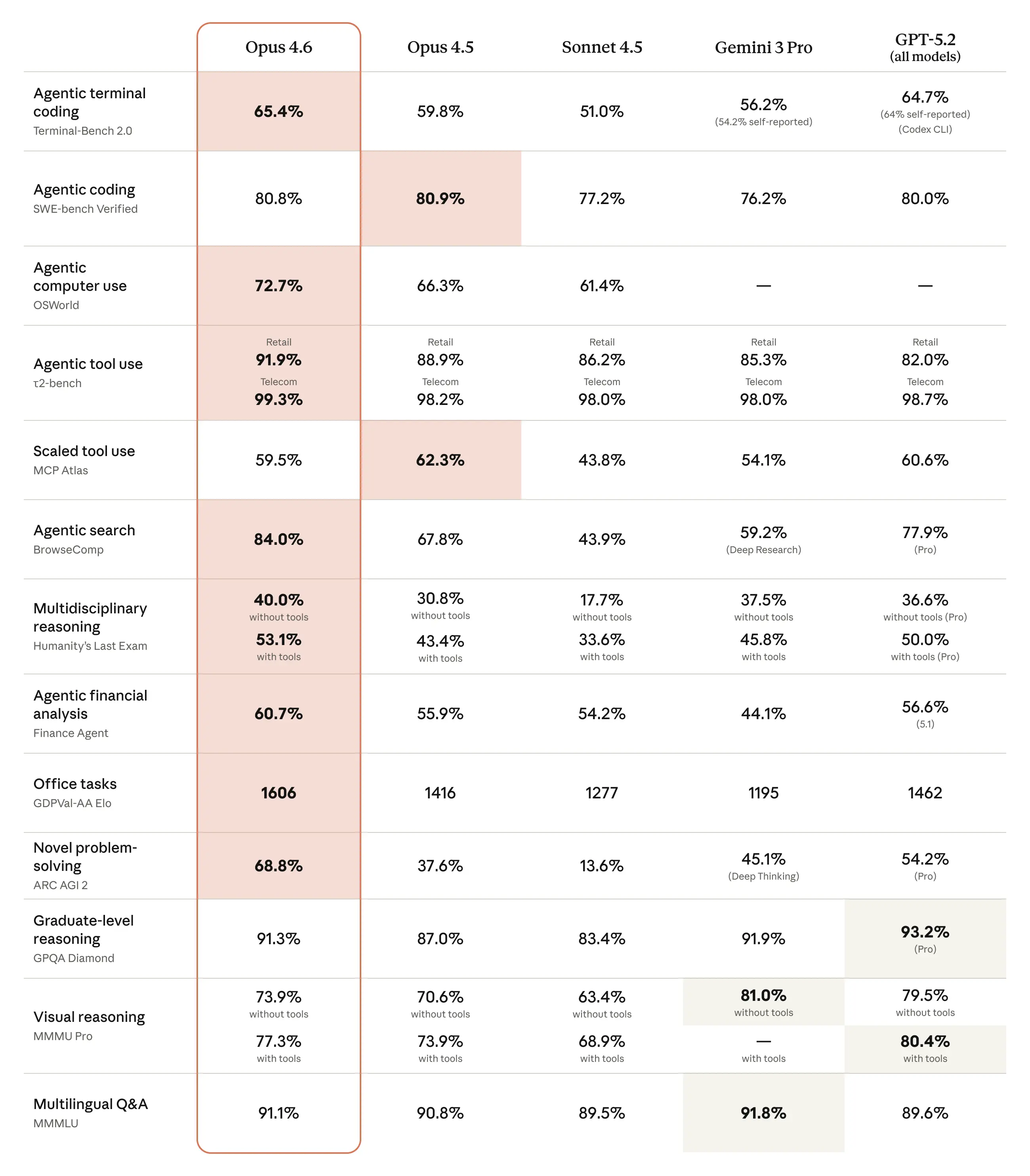
Opus 4.6 legt gegenüber Opus 4.5 zu und zeigt in einem Mix aus Coding, Reasoning und domänenspezifischen Suites konkurrenzfähige Platzierungen gegenüber jüngsten Modellen von OpenAI und Google. Kurz gemeldete Beispiele:
- BigLaw Bench: Opus 4.6 erreichte ~90,2% auf Anthropics BigLaw Bench (juristisches Reasoning).
- Terminal‑Bench 2.0 / GDPval‑Metriken: Unabhängige Berichte listen Terminal‑Bench‑2.0‑Scores und GDPval‑AA‑Elo‑Ratings, die Opus 4.6 vor Opus 4.5 und konkurrenzfähig mit einigen jüngsten Releases von Rivalen positionieren. Ein Bericht nannte einen Terminal‑Bench‑2.0‑Score von 65,4% und eine GDPval‑AA‑Elo von ~1.606.
Anthropic berichtet von großen Zugewinnen bei agentischen Coding‑Aufgaben, mit besserer Planung, weniger Iterationen und stärkerer Performance auf riesigen Codebasen — einschließlich der Behauptung, Migrationen auf Repos mit mehreren Millionen Zeilen schneller zu planen und auszuführen. Die verbesserte Fähigkeit des Modells, eigene Fehler „selbst zu erkennen“ und das Reasoning über viele Schritte hinweg aufrechtzuerhalten, wird hervorgehoben.
Wie viel kostet Opus 4.6?
Kurzfassung — Preise pro Token
- Standard (Prompts ≤ 200K Token): $5 / 1M Input‑Token und $25 / 1M Output‑Token.
- Große Prompts (Prompts > 200K Token): $10 / 1M Input und $37.50 / 1M Output.
- Schnellmodus (Research‑Vorschau): eine Premium‑Stufe — $30 / 1M Input und $150 / 1M Output (schnellere Inferenz).
Praktische Kostenüberlegungen:
- Agentische Workflows sind oft tokenintensiv. Mehrstufige Planung, Toolaufrufe und lange Ausgaben erhöhen die Ausgabetoken; sorgfältige Nutzung von Komprimierung und Cache‑Zugriffen ist wichtig, um die Abrechnung zu steuern.
- Batching spart Geld. Wenn Ihre Workloads asynchrones Batch‑Processing zulassen, kann die Batch‑API‑Preisgestaltung von Anthropic die Kosten pro Token spürbar senken.
- Premium‑Kontext ist teurer. Wenn Sie häufig auf die 1M‑Token‑Beta angewiesen sind, planen Sie mit höheren Kosten pro Token. Viele Organisationen werden Modi mischen: große Kontexte nur, wo unbedingt nötig, und schlanke Sitzungen anderswo.
Günstigere Möglichkeiten zur Nutzung der Claude‑API
CometAPI ist eine gute Wahl. Die Opus 4.6 API stammt ebenfalls von Anthropic, aber die API‑Preisgestaltung liegt bei 20% des offiziellen Preises und ändert sich nicht mit der Kontextlänge.
Wie schlägt sich Opus 4.6 im Vergleich zu GPT‑5.3 und Google Gemini 3?
Opus 4.6 vs. OpenAIs GPT‑5.3
OpenAIs jüngstes GPT‑5.3 (von OpenAI in der „Codex“‑Linie für Coding/Agent‑Aufgaben gebrandet) ist explizit auf tiefes Coding und agentenartige Workflows getunt und beansprucht branchenführende Werte auf mehreren Engineering‑Benchmarks (SWE‑Bench Pro, Terminal‑Bench). Frühe Berichte deuten darauf hin, dass GPT‑5.3‑Codex den Stand der Technik in Software‑Engineering‑Benchmarks und agentischer Planung vorantreibt und sich damit als engster direkter Rivale von Opus 4.6 bei reinen Coding‑ und Agent‑Aufgaben positioniert. Opus 4.6 hingegen betont extrem langen Kontext und Multi‑Agent‑Orchestrierung als Differenzierungsmerkmale. Kurz: GPT‑5.3 wirkt auf rohe Engineering‑Tiefe und Benchmark‑Dominanz in entwicklerzentrierten Tests optimiert; Opus 4.6 betont die Breite über Langkontext‑Enterprise‑Workflows und domänenspezifisches Reasoning.
Opus 4.6 vs. Google Gemini 3?
Googles Gemini 3 (sowie Gemini 3 Pro/Deep Think‑Varianten) wird für starke Leistungen in abstraktem Reasoning, visueller Problemlösung und bestimmten wissenschaftlichen QA‑Benchmarks hervorgehoben; zudem hat es fortgeschrittenes multimodales Reasoning gegenüber seinen Vorgängern weitergetrieben. Berichte positionieren Gemini 3 als besonders stark in wissenschaftlichen und visuellen Reasoning‑Suiten, während Opus 4.6 beim Langkontext‑Code und in juristischen/Enterprise‑Anwendungen punktet. Für Organisationen, die multimodales wissenschaftliches Reasoning oder anspruchsvolle visuelle Logikaufgaben benötigen, könnte Gemini 3 im Vorteil sein; für nachhaltige Wissensarbeit mit Langkontext und Multi‑Agent‑Automatisierung beansprucht Opus 4.6 das Feld.
Wer „gewinnt“ im Direktvergleich?
Kein Anbieter „gewinnt“ universell: Die Wahl hängt vom relevanten Workflow ab. Frühe unabhängige Vergleiche zeigen, dass Opus 4.6 Opus 4.5 bei langen Horizonten und Domänenaufgaben deutlich übertrifft, während GPT‑5.3 und Gemini 3 in bestimmten Coding‑ und multimodalen Testbeds Vorteile behalten. Wie in jeder sich schnell entwickelnden Generation gewinnt der Kunde, der die Modellstärken mit realen Workloads und Tool‑Integrationen abgleicht — nicht das Modell mit dem höchsten Einzelbenchmark.
Lohnt sich Claude Opus 4.6?
Kurzantwort: Ja — wenn Ihre primären Probleme Langkontext‑Reasoning, autonome Agent‑Workflows oder Enterprise‑Compliance sind. Die Stärken von Opus 4.6 sind real und relevant: die 200K‑ (und Beta‑1M‑) Fenster, adaptives Denken, Agententeams und Enterprise‑Integrationen sind greifbare Upgrades, die die Produktentwicklung vereinfachen und die Klasse der Probleme vergrößern, die Sie automatisieren können.
Wenn Ihre Workloads dagegen überwiegend kurze, hochgradig repetitive Mikrotasks sind, bei denen Stückkosten und Latenz ausschlaggebend sind, könnte Opus 4.6 im Vergleich zu einem kurzfristig spezialisierten Modell (z. B. GPT‑5.3 Codex) überdimensioniert sein — es sei denn, Sie planen, beide zu kombinieren und Aufgaben entsprechend zu routen.
CometAPI ist eine One‑Stop‑Aggregationsplattform für große Modell‑APIs und bietet nahtlose Integration und Verwaltung von API‑Diensten. Sie unterstützt das Aufrufen verschiedener Mainstream‑KI‑Modelle. Dazu gehören Bild‑ und Video‑Generierung, Chat, TTS und STT — alles auf einer Plattform.
Sie können zudem je nach gewünschten Kosten und Modellfähigkeiten das passende Modell wählen und jederzeit zwischen ihnen wechseln, etwa Gemini 3 Flash, GPT 5.3 oder Opus 4.6. Bevor Sie zugreifen, stellen Sie bitte sicher, dass Sie sich bei CometAPI angemeldet und einen API‑Schlüssel erhalten haben. CometAPI bietet einen deutlich niedrigeren Preis als der offizielle, um Ihre Integration zu erleichtern.
Bereit? → Jetzt anmelden!
Wenn Sie mehr Tipps, Anleitungen und News zu KI möchten, folgen Sie uns auf VK, X und Discord!