

Kling O1 – im Rahmen der „Omni“-Einführungswoche von Kling AI veröffentlicht – positioniert sich als einheitliches, multimodales Videomodell, das Text, Bilder und Videos in derselben Anfrage verarbeitet und Videos in iterativen Workflows auf Regieebene generieren und bearbeiten kann. Das Kling-Team bezeichnet O1 als das „weltweit erste einheitliche multimodale Videomodell für große Projekte“. Interne Tests von Kling zeigen deutliche Vorteile gegenüber Googles Veo 3.1 und Runway Aleph.
Was ist Kling O1?
Kling O1 (oft vermarktet als Video O1 or Omni EinsKling O1 ist ein neues Video-Fundamentmodell von Kling AI, das die Generierung und Bearbeitung von Text, Bildern und Videos in einem einzigen, promptgesteuerten Framework vereint. Anstatt Text-zu-Video, Bild-zu-Video und Videobearbeitung als separate Prozesse zu behandeln, verarbeitet Kling O1 gemischte Eingaben (Text + mehrere Bilder + optionales Referenzvideo) in einem einzigen Prompt, analysiert diese und erstellt kohärente Kurzclips oder bearbeitet vorhandenes Material mit präziser Steuerung. Das Unternehmen positionierte die Markteinführung als Teil eines „Omni Launch“ und beschreibt O1 als „multimodale Video-Engine“, die auf einem Paradigma der multimodalen visuellen Sprache (MVL) und einem Chain-of-Thought-Ansatz (CoT) basiert, um komplexe, mehrteilige kreative Anweisungen zu interpretieren.
Klings Ansatz hebt drei praktische Arbeitsabläufe hervor: (1) Text → Videogenerierung, (2) Bild/Element → Video (Komposition und Austausch von Objekten/Requisiten mithilfe expliziter Referenzen) und (3) Videobearbeitung/Fortsetzung von Einstellungen (Umgestaltung, Hinzufügen/Entfernen von Objekten, Steuerung von Start- und Endbild). Das Modell unterstützt Eingabeaufforderungen mit mehreren Elementen (einschließlich einer „@“-Syntax zur Ansteuerung bestimmter Referenzbilder) und bietet Regiefunktionen wie die Verankerung von Start- und Endbild sowie die Videofortsetzung zum Erstellen von Sequenzen mit mehreren Einstellungen.
5 Kernpunkte von Kling O1
1) Echter einheitlicher multimodaler Input (MVL)
Die herausragende Funktion des Kling O1 besteht darin, Text, Standbilder (mehrere Referenzen) und Video als erstklassige, simultane Eingaben zu verarbeiten. Benutzer können mehrere Referenzbilder (oder einen kurzen Referenzclip) bereitstellen. kombiniert mit einem nachhaltigen Materialprofil. Eine natürlichsprachliche Anweisung; das Modell analysiert alle Eingaben gemeinsam, um eine kohärente Ausgabe zu erzeugen oder zu bearbeiten. Dies reduziert Reibungsverluste in der Werkzeugkette und ermöglicht Arbeitsabläufe wie „Betreff verwenden aus @image1Platzieren Sie sie in der Umgebung von @image2, Bewegungsanpassung an ref_video.mp4und wenden Sie die filmische Farbkorrektur X an.“ Diese „Multimodale visuelle Sprache“ (MVL) ist Kernbestandteil von Klings Präsentation.
Warum es darauf ankommt: Kreative Arbeitsabläufe erfordern oft die Kombination von Referenzen: eine Figur aus einem Asset, eine Kamerabewegung aus einem anderen und eine narrative Anweisung in Textform. Die Zusammenführung dieser Eingaben ermöglicht die Generierung in einem Durchgang und reduziert die Anzahl manueller Kompositionsschritte.
2) Bearbeitung und Generierung in einem Modell (Mehrelementmodus)
Die meisten bisherigen Systeme trennten die Generierung (Text→Video) von der framegenauen Bearbeitung. O1 kombiniert beides bewusst: Dasselbe Modell, das einen Clip von Grund auf neu erstellt, kann auch vorhandenes Material bearbeiten – Objekte austauschen, Kleidung neu stylen, Requisiten entfernen oder eine Einstellung verlängern – alles über natürlichsprachliche Anweisungen. Diese Konvergenz vereinfacht den Workflow für Produktionsteams erheblich.
Das O1-Modell erreicht in seinem Kern eine tiefe Integration mehrerer Videoaufgaben:
- Text-zu-Video-Generierung
- Bild-/Motivreferenzgenerierung
- Videobearbeitung & Inpainting
- Video-Restyle
- Nächste/Vorherige Aufnahmeerzeugung
- Keyframe-basierte Videogenerierung
Die größte Bedeutung dieses Designs liegt darin: Komplexe Prozesse, die zuvor mehrere Modelle oder unabhängige Werkzeuge erforderten, können nun in einer einzigen Engine abgewickelt werden. Dies reduziert nicht nur die Erstellungs- und Rechenkosten erheblich, sondern schafft auch die Grundlage für die Entwicklung eines „einheitlichen Modells zur Videoanalyse und -generierung“.
3) Die Kohärenz der Videogenerierung
Identitätskonsistenz: Das O1-Modell verbessert die Möglichkeiten der modalitätsübergreifenden Konsistenzmodellierung und erhält die Stabilität von Struktur, Material, Beleuchtung und Stil des Referenzobjekts während des Generierungsprozesses aufrecht:
- Es unterstützt Referenzbilder aus mehreren Perspektiven für die Modellierung von Subjekten;
- Es unterstützt die Konsistenz des Motivs über verschiedene Einstellungen hinweg (Charakter-, Objekt- und Szenenmerkmale bleiben über verschiedene Einstellungen hinweg konsistent);
- Es unterstützt hybride Referenzen mit mehreren Motiven und ermöglicht so die Erstellung von Gruppenporträts und die interaktive Szenengestaltung.
Dieser Mechanismus verbessert die Kohärenz und „Identitätskonsistenz“ der Videogenerierung erheblich und eignet sich daher für Szenarien mit extrem hohen Konsistenzanforderungen, wie z. B. Werbung und die Generierung von Filmaufnahmen.
Verbesserter Speicher: Das O1-Modell verfügt außerdem über einen „Speicher“, der verhindert, dass sein Ausgabestil aufgrund langer Kontexte oder sich ändernder Anweisungen instabil wird. Es kann sogar:
- sich mehrere Zeichen gleichzeitig merken;
- Ermöglichen Sie es verschiedenen Charakteren, im Video zu interagieren;
- Bewahren Sie einen einheitlichen Stil, eine einheitliche Kleidung und eine einheitliche Körperhaltung.
4) Präzises Compositing mit der „@“-Syntax und Start-/Endframe-Steuerung
Kling führte eine Kurzschrift für Bildkompositionen ein (die als „@“-Erwähnungssystem gemeldet wird), mit der man in der Aufgabenstellung auf bestimmte Bilder verweisen kann (z. B. @image1, @image2Um Assets zuverlässig Rollen zuzuweisen, ermöglicht dies in Kombination mit der expliziten Angabe von Start- und Endframes die Kontrolle des Regisseurs über Übergänge, Bewegungen und Morphing von Elementen im generierten Clip – ein produktionsorientierter Funktionsumfang, der O1 von vielen verbraucherorientierten Generatoren unterscheidet.
5) Hochwertige, längere Ausgaben und Multitasking-Fähigkeit
Kling O1 soll kinoreife 1080p-Ausgaben (30 fps) erzeugen und – nach dem Vorbild früherer Kling-Versionen – die Generierung längerer Clips (in aktuellen Produktbeschreibungen bis zu 2 Minuten) ermöglichen. Zudem unterstützt es die Kombination mehrerer kreativer Aufgaben in einer einzigen Anfrage (Generierung, Hinzufügen eines Motivs, Ändern der Beleuchtung und Bearbeiten der Bildkomposition). Diese Eigenschaften machen es konkurrenzfähig mit höherwertigen Text-zu-Video-Engines.
Warum es darauf ankommt: Längere, hochauflösende Clips und die Möglichkeit, Bearbeitungen zu kombinieren, verringern den Bedarf, viele kurze Clips zusammenzufügen, und vereinfachen die gesamte Produktion.
Wie ist Kling O1 architektonisch aufgebaut und welche Mechanismen liegen ihm zugrunde?
O1 um ein Multimodale visuelle Sprache (MVL) Kern: ein Modell, das gemeinsame Einbettungen für Sprache, Bilder und Bewegungssignale (Videoframes und optische Flussmerkmale) lernt und anschließend Diffusions- oder Transformer-basierte Decoder anwendet, um zeitlich kohärente Frames zu synthetisieren. Das Modell wird wie folgt beschrieben: Konditionierung auf mehreren Referenzen (Text; Eins-zu-Viele-Bilder; kurze Videoclips), um eine latente Videodarstellung zu erzeugen, die dann in Einzelbildbilder dekodiert wird, wobei die zeitliche Konsistenz durch frameübergreifende Aufmerksamkeit oder spezialisierte temporale Module erhalten bleibt.
1. Multimodaler Transformer + Architektur für lange Kontexte
Das O1-Modell verwendet Kelings selbstentwickelte multimodale Transformer-Architektur, die Text-, Bild- und Videosignale integriert und ein Langzeitgedächtnis für den zeitlichen Kontext unterstützt (Multimodal Long Context).
Dies ermöglicht es dem Modell, zeitliche Kontinuität und räumliche Konsistenz während der Videogenerierung zu verstehen.
2. MVL: Multimodale visuelle Sprache
MVL ist die Kerninnovation dieser Architektur.
Es verknüpft sprachliche und visuelle Signale innerhalb des Transformers durch eine einheitliche semantische Zwischenschicht auf tiefgreifende Weise und bewirkt dadurch Folgendes:
- Ermöglichung der Kombination multimodaler Anweisungen über ein einziges Eingabefeld;
- Verbesserung des präzisen Verständnisses von natürlichsprachlichen Beschreibungen durch das Modell;
- Unterstützung hochflexibler interaktiver Videogenerierung.
Die Einführung von MVL markiert einen Wandel in der Videogenerierung von „textgesteuert“ zu „semantisch-visuell gemeinsam gesteuert“.
3. Gedankenketten-Schlussfolgerungsmechanismus
Das O1-Modell führt während der Videogenerierungsphase einen „Gedankenketten“-Inferenzpfad ein.
Dieser Mechanismus ermöglicht es dem Modell, Ereignislogik und Zeitablauf vor der Generierung abzuleiten und so eine natürliche Verbindung zwischen Aktionen und Ereignissen innerhalb des Videos aufrechtzuerhalten.
Inferenz- und Bearbeitungspipelines
- Generation: Eingabe: (Text + optionale Bildreferenzen + optionale Videoreferenzen + Generierungseinstellungen) → Modell erzeugt latente Videoframes → Dekodierung zu Frames → optionale Farb-/Zeit-Nachbearbeitung.
- Anweisungsbasierte Bearbeitung: Feed: (Originalvideo + Textanweisung + optionale Bildreferenzen) → Das Modell ordnet die angeforderte Bearbeitung intern einer Reihe von Pixelraumtransformationen zu und synthetisiert anschließend bearbeitete Frames, wobei der unveränderte Inhalt erhalten bleibt. Da alles in einem Modell enthalten ist, werden für Erstellung und Bearbeitung dieselben Konditionierungs- und Zeitmodule verwendet.
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
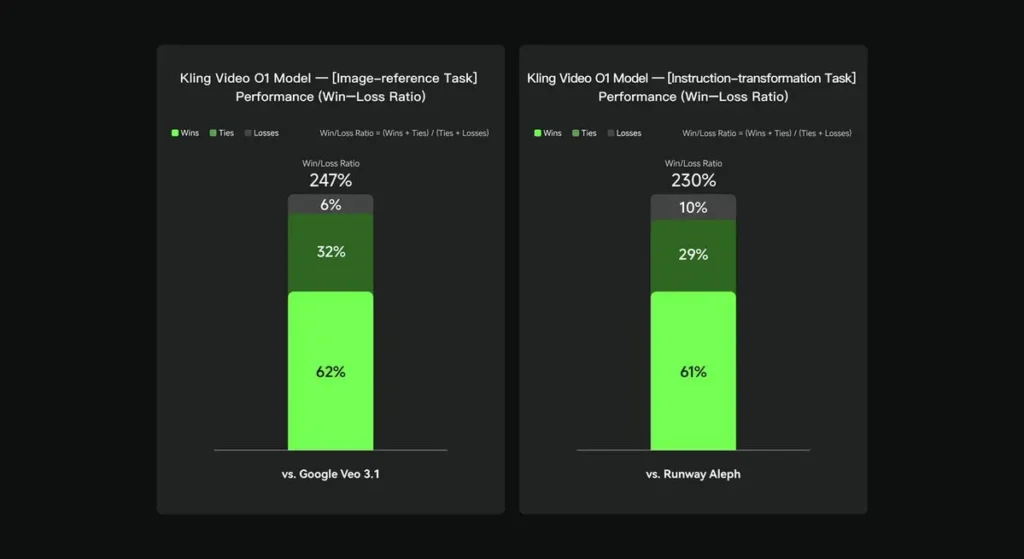
In internen Evaluierungen übertraf Keling Video O1 bestehende internationale Konkurrenzprodukte in mehreren Schlüsselbereichen deutlich. Leistungsergebnisse (basierend auf dem von Keling AI selbst entwickelten Evaluierungsdatensatz):
- Aufgabe „Bildreferenz“: O1 übertrifft Google Veo 3.1 insgesamt mit einer Gewinnrate von 247 %;
- Aufgabe „Anweisungstransformation“: O1 übertrifft Runway Aleph mit einer Gewinnrate von 230 %.
Wettbewerbsüberblick (Vergleich auf Funktionsebene)
| Fähigkeit / Modell | Kling O1 | Google Veo 3.1 | Startbahn (Aleph / Gen-4.5) |
|---|---|---|---|
| Einheitliche multimodale Eingabeaufforderung (Text+Bilder+Video) | Ja (zentrales Verkaufsargument). multimodale Abläufe mit einer einzigen Anfrage. | Teilweise — Text→Video + Referenzen vorhanden; weniger Schwerpunkt auf einem einheitlichen MVL. | Runway konzentriert sich auf Generierung und Bearbeitung, jedoch oft als separate Modi; die neueste Version Gen-4.5 verringert diese Kluft. |
| Konversationelle / textbasierte Pixelbearbeitungen | Ja — „Bearbeiten wie ein Gespräch“ (ohne Masken). | Teilweise – Bearbeitungsmöglichkeiten sind vorhanden, aber Masken-/Keyframe-Workflows sind immer noch üblich. | Runway verfügt über leistungsstarke Bearbeitungswerkzeuge; Runway wirbt mit leistungsstarken Anweisungstransformationen (variiert je nach Version). |
| Start-/Endbildsteuerung und Kamerareferenz | Ja — explizite Beschreibung des Start-/Endbildes und der Referenzkamerabewegungen. | Begrenzt / sich entwickelnd | Runway: Verbesserte Steuerung; nicht exakt dieselbe Benutzererfahrung. |
| Generierung langer Clips (hohe Wiedergabetreue) | bis zu ~2 Minuten (1080p, 30fps) in Produktmaterialien und Community-Beiträgen; | Veo 3.1: Starke Kohärenz, aber frühere Versionen hatten kürzere Standardeinstellungen; variiert je nach Modell/Einstellung. | Runway Gen-4.5: Setzt auf hohe Qualität; Länge/Genauigkeit variiert. |
Fazit:
Kling O1s öffentlicher Anspruch auf Bekanntheit ist Workflow-VereinheitlichungEin einziges Modell erhält die Befugnis, Text, Bilder und Videos zu verstehen und sowohl die Generierung als auch die Bearbeitung komplexer Anweisungen innerhalb desselben semantischen Systems durchzuführen. Für Kreative und Teams, die häufig zwischen den Schritten „Erstellen“, „Bearbeiten“ und „Erweitern“ wechseln, kann diese Konsolidierung die Iterationsgeschwindigkeit und die Komplexität der Werkzeuge erheblich reduzieren. Verbesserte zeitliche Konsistenz, Kontrolle über Start- und Endframes sowie pragmatische Plattformintegrationen machen es für Kreative zugänglich.
Die Kling Video o1 API wird in Kürze auf CometAPI verfügbar sein.
Entwickler können zugreifen Kling 2.5 Turbo kombiniert mit einem nachhaltigen Materialprofil. Veo 3.1 API - durch Konsolidierung, CometAPIDie neuesten Modelle sind zum Veröffentlichungsdatum des Artikels aufgeführt. Erkunden Sie zunächst die Funktionen des Modells im Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bieten einen Preis weit unter dem offiziellen Preis an, um Ihnen bei der Integration zu helfen.
Bereit loszulegen? → Melden Sie sich noch heute für CometAPI an !
Wenn Sie weitere Tipps, Anleitungen und Neuigkeiten zu KI erfahren möchten, folgen Sie uns auf VK, X kombiniert mit einem nachhaltigen Materialprofil. Discord!