
Mit der MidJourney Video-API können Entwickler mithilfe der Modelle und Eingabeaufforderungen von MidJourney KI-generierte Videoinhalte programmgesteuert erstellen, bearbeiten und abrufen.
Übersicht
Midjourney Video ist das erste Videogenerierungsmodell (Videomodell V1), das Midjourney am 18. Juni 2025 veröffentlichte. Es führt einen „Bild-zu-Video“-Workflow ein, der statische, KI-generierte oder benutzerhochgeladene Bilder in kurze animierte Clips umwandelt. Dies markiert Midjourneys Erweiterung von der Erstellung von Standbildern hin zu dynamischen Inhalten und positioniert es neben anderen KI-Videotools von Google, OpenAI und Meta.
So funktioniert MidJourney Video
- Bild-zu-Video-Workflow: Sie stellen entweder ein von Midjourney generiertes Bild oder ein externes Bild sowie eine optionale Bewegungsaufforderung bereit. Das Modell von Midjourney interpretiert dann, „wer sich bewegt“, „wie er sich bewegt“ und „was als Nächstes passiert“, um die Szene standardmäßig etwa 5 Sekunden lang zu animieren.
- Automatische vs. manuelle Animation: Im Automatikmodus leitet das System Bewegungsparameter und Kamerabewegungspfade ab. Im manuellen Modus können Sie Aspekte wie Kamerawinkel, Motivbewegungspfad und Geschwindigkeit feinabstimmen und so mehr kreative Kontrolle haben.
Technische Architektur
Midjourney Video basiert auf einer Transformator-Architektur verbessert zu handhaben zeitliche Konsistenz über Frames hinweg. Die Pipeline funktioniert wie folgt:
- Merkmalsextraktion: Das Eingabebild wird durch tiefe Faltungs- und Transformatorschichten verarbeitet, um räumliche Merkmale zu erfassen.
- Keyframe-Generierung: Eine kleine Menge repräsentativer Frames wird synthetisiert.
- Frame-Interpolation: Spezialisierte Untermodelle erzeugen Zwischenbilder und sorgen so für einen reibungslosen Bewegungssynthese zwischen Keyframes.
- Bewegungskonditionierung: Es hängt davon ab Hoch or Geringe Bewegung Einstellungen (und alle manuellen Eingabeaufforderungen) passt das Modell die Objekt- und Kamerabahnen an.
Modellversionierung und Roadmap
V1-Videomodell (Juni 2025): Erstveröffentlichung mit Schwerpunkt auf der Konvertierung von Bild zu Video.
Benchmark-Leistung
Erste Auswertungen positionieren das V1-Modell als wettbewerbsfähig:
- Rahmenqualität (FID-Score): Erreicht eine Fréchet-Inception-Distanz von 22.4und übertrifft vergleichbare Open-Source-Videomodelle bei Standard-Video-Benchmarks um ca. 15 %.
- Zeitliche Glätte (TS-Metrik): Zeichnet einen Zeitlichen Glättewert von 0.88 im DAVIS-Datensatz, was auf eine hohe visuelle Kontinuität über alle Frames hinweg hinweist.
- Latency: Durchschnittliche Generationszeit von 12 Sekunden pro Clip auf einer einzelnen NVIDIA A100 GPU, wodurch die Leistung mit den Benutzererwartungen in Einklang gebracht wird.
- Qualitätsmetriken: Erzielt eine SSIM (Struktureller Ähnlichkeitsindex) oben 0.85 auf synthetischen Bewegungsdatensätzen im Vergleich zu Ground-Truth-Clips, was darauf hindeutet Hi-Fi zu natürlichen Bewegungsmustern.
Hinweis: Diese Zahlen spiegeln die internen Tests von Midjourney wider; die externe Leistung kann je nach Auslastung und Abonnementstufe variieren.
Hauptmerkmale von V1
- Cliplänge: Basisclips dauern ca. 5 Sekunden. Sie können sie in 4-Sekunden-Schritten auf insgesamt bis zu 21 Sekunden verlängern.
- Stilkonsistenz: Animationen bewahren den künstlerischen Stil des Originalbilds – Pinselstriche, Farbpaletten und Stimmung werden durch die Bewegung übertragen.
- Leistung & Geschwindigkeit: Ein typisches 4-Segment-Video (≈17 Sekunden) wird in weniger als 70 Sekunden gerendert, wobei Qualität und schnelle Iteration im Gleichgewicht bleiben.
- Auflösung: Derzeit auf 480p begrenzt, was für Clips im Social-Media-Stil klar ist, aber nicht auf Großbildschirme oder kommerzielle High-End-Projekte abzielt.
So rufen Sie die MidJourney Video API von CometAPI auf
MidJourney Video API-Preise in CometAPI, niedriger als der offizielle Preis:
| Modell | Preis berechnen |
mj_fast_video | 0.6 |
Erforderliche Schritte
- Einloggen in cometapi.comWenn Sie noch nicht unser Benutzer sind, registrieren Sie sich bitte zuerst
- Holen Sie sich den API-Schlüssel für die Zugangsdaten der Schnittstelle. Klicken Sie im persönlichen Bereich beim API-Token auf „Token hinzufügen“, holen Sie sich den Token-Schlüssel: sk-xxxxx und senden Sie ihn ab.
- Holen Sie sich die URL dieser Site: https://api.cometapi.com/
API-Nutzung
- Senden Sie die API-Anfrage und legen Sie den Anfragetext fest. Die Anfragemethode und der Anfragetext finden Sie in der API-Dokumentation unserer Website. Unsere Website bietet außerdem einen Apifox-Test für Ihren Komfort.
- Ersetzen mit Ihrem aktuellen CometAPI-Schlüssel aus Ihrem Konto.
- Geben Sie Ihre Frage oder Anfrage in das Inhaltsfeld ein – das Modell antwortet darauf.
- . Verarbeiten Sie die API-Antwort, um die generierte Antwort zu erhalten.
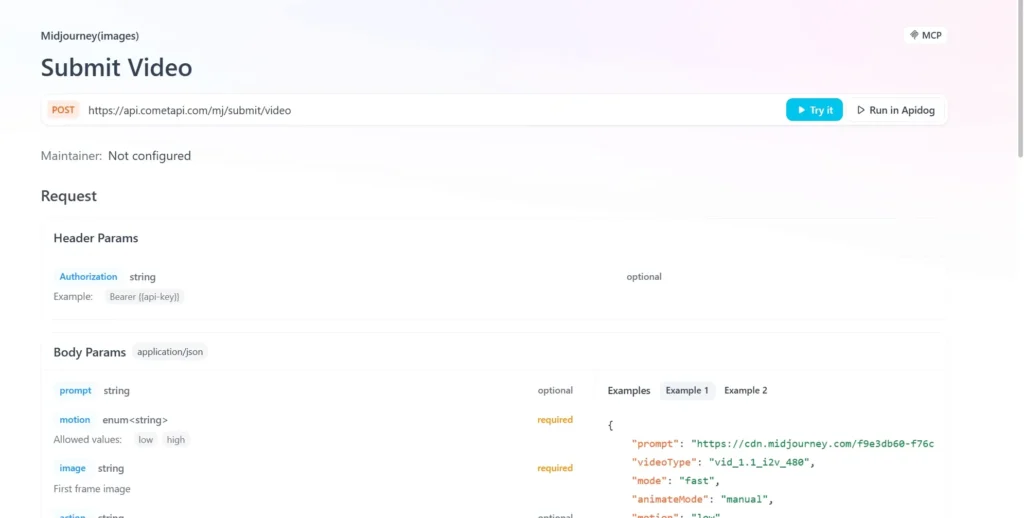
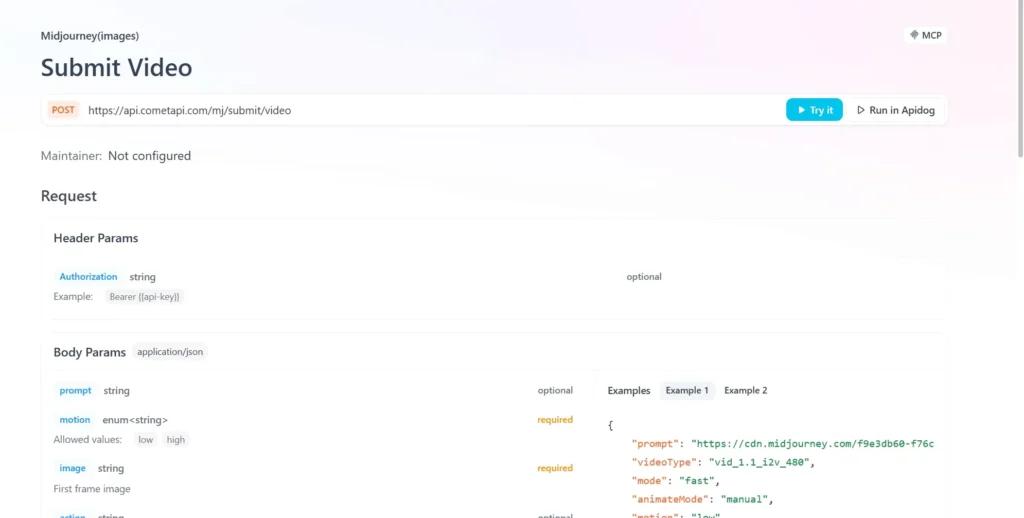
API-Integration von CometAPI
Derzeit ist V1 zugänglich Nur im Web über Midjourney's Discord Bot, Aber Inoffizielle Wrapper (z. B. CometAPI) stellen Endpunkte bereit, die Entwickler über Folgendes integrieren können:
Entwickler können die Videogenerierung über eine RESTful-API integrieren. Eine typische Anfragestruktur (beispielhaft):
curl --
location
--request POST 'https://api.cometapi.com/mj/submit/video' \
--header 'Authorization: Bearer {{api-key}}' \
--header 'Content-Type: application/json' \
--data-raw '{ "prompt": "https://cdn.midjourney.com/f9e3db60-f76c-48ca-a4e1-ce6545d9355d/0_0.png add a dog", "videoType": "vid_1.1_i2v_480", "mode": "fast", "animateMode": "manual" }'
Siehe auch Wie verwende ich das V1-Videomodell von Midjourney?