

Am 17. Juni wurde das Shanghaier KI-Einhorn MiniMax offiziell als Open Source veröffentlicht. MiniMax‑M1, das weltweit erste groß angelegte, offen gewichtete Hybrid-Attention-Inferenzmodell. Durch die Kombination einer Mixture-of-Experts-Architektur (MoE) mit dem neuen Lightning Attention-Mechanismus bietet MiniMax-M1 erhebliche Verbesserungen bei der Inferenzgeschwindigkeit, der Verarbeitung ultralanger Kontexte und der Leistung komplexer Aufgaben.
Hintergrund und Entwicklung
Aufbauend auf dem Fundament von MiniMax-Text-01, das blitzschnell auf ein Mixture-of-Experts (MoE)-Framework achtete, um Kontexte mit 1 Million Token während des Trainings und bis zu 4 Millionen Token bei der Inferenz zu erreichen, stellt MiniMax-M1 die nächste Generation der MiniMax-01-Reihe dar. Das Vorgängermodell, MiniMax-Text-01, enthielt insgesamt 456 Milliarden Parameter, von denen 45.9 Milliarden pro Token aktiviert wurden, und zeigte damit eine Leistung auf Augenhöhe mit LLMs der Spitzenklasse, während die Kontextfähigkeiten enorm erweitert wurden.
Hauptmerkmale des MiniMax‑M1
- Hybrid MoE + Lightning Attention: MiniMax‑M1 verbindet ein spärliches Mixture‑of‑Experts-Design – 456 Milliarden Parameter insgesamt, aber nur 45.9 Milliarden aktiviert pro Token – mit Lightning Attention, einer linearen Komplexitätsaufmerksamkeit, die für sehr lange Sequenzen optimiert ist.
- Ultralanger Kontext: Unterstützt bis zu 1 Millionen Eingabetoken – etwa das Achtfache der 128-K-Grenze von DeepSeek-R1 – ermöglichen ein tiefes Verständnis umfangreicher Dokumente.
- Überlegene Effizienz: Beim Generieren von 100 Token benötigt Lightning Attention von MiniMax‑M1 nur etwa 25–30 % der Rechenleistung von DeepSeek‑R1.
Modellvarianten
- MiniMax‑M1‑40K: 1 M Token-Kontext, 40 K Token-Inferenzbudget
- MiniMax‑M1‑80K: 1 M Token-Kontext, 80 K Token-Inferenzbudget
In TAU-Bench-Tool-Anwendungsszenarien übertraf die 40K-Variante alle Open-Weight-Modelle – einschließlich Gemini 2.5 Pro – und demonstrierte damit ihre Agentenfähigkeiten.
Schulungskosten und -einrichtung
MiniMax-M1 wurde mithilfe von groß angelegtem Reinforcement Learning (RL) für eine Vielzahl von Aufgaben – von fortgeschrittenem mathematischen Denken bis hin zu Sandbox-basierten Softwareentwicklungsumgebungen – durchgängig trainiert. Ein neuartiger Algorithmus, CISPO (Clipped Importance Sampling for Policy Optimization) steigert die Trainingseffizienz zusätzlich, indem Gewichte des Importance Sampling abgeschnitten werden, anstatt Updates auf Token-Ebene durchzuführen. Dieser Ansatz, kombiniert mit der hohen Aufmerksamkeit des Modells, ermöglichte ein vollständiges RL-Training auf 512 H800-GPUs in nur drei Wochen bei Gesamtmietkosten von 534,700 US-Dollar.
Verfügbarkeit und Preise
MiniMax-M1 wird veröffentlicht unter der Apache 2.0 Open-Source-Lizenz und ist sofort zugänglich über:
- GitHub-Repository, einschließlich Modellgewichten, Trainingsskripten und Bewertungsbenchmarks.
- SiliconCloud Hosting, das zwei Varianten anbietet – 40 K-Token („M1-40K“) und 80 K-Token („M1-80K“) – mit Plänen, den vollständigen 1 M-Token-Funnel zu ermöglichen.
- Die Preise liegen derzeit bei 4 Yen pro Million Token für die Eingabe und 16 Yen pro Million Token für die Ausgabe, mit Mengenrabatten für Unternehmenskunden.
Entwickler und Organisationen können MiniMax-M1 über Standard-APIs integrieren, domänenspezifische Daten optimieren oder für sensible Workloads vor Ort bereitstellen.
Leistung auf Aufgabenebene
| Aufgabenkategorie | Hervorheben | Relative Leistung |
|---|---|---|
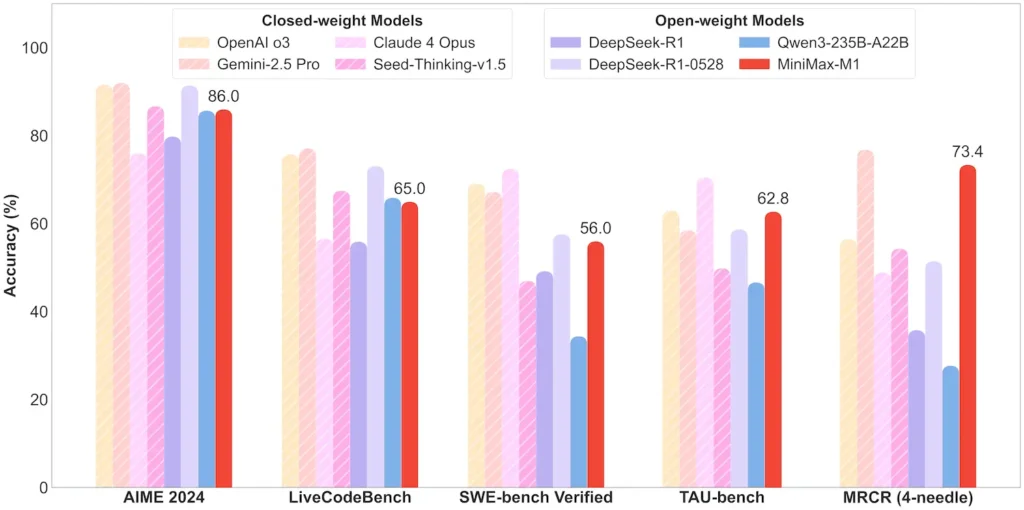
| Mathematik & Logik | AIME 2024: 86.0 % | > Qwen 3, DeepSeek‑R1; nahezu Closed Source |
| Langfristiges Kontextverständnis | Herrscher (4 K–1 M Spielsteine): Stabile Spitzenklasse | Übertrifft GPT‑4 bei Tokenlängen über 128 K |
| Software Engineering | SWE‑bench (echte GitHub-Bugs): 56 % | Bestes unter den offenen Modellen; zweitbestes nach den führenden geschlossenen |
| Agenten- und Tool-Nutzung | TAU‑Bench (API-Simulation) | 62–63.5 % vs. Zwillinge 2.5, Claude 4 |
| Dialog & Assistent | MultiChallenge: 44.7 % | Entspricht Claude 4, DeepSeek‑R1 |
| Fakten-QA | SimpleQA: 18.5 % | Bereich für zukünftige Verbesserungen |
Hinweis: Prozentsätze und Benchmarks stammen aus der offiziellen MiniMax-Veröffentlichung und unabhängigen Nachrichtenberichten
Technische Innovationen
- Hybrider Aufmerksamkeitsstapel: Blitzaufmerksamkeit Schichten (lineare Kosten) verschachtelt mit periodischer Softmax-Aufmerksamkeit (quadratisch, aber ausdrucksstärker), um Effizienz und Modellierungsleistung auszugleichen.
- Sparse MoE-Routing: 32 Expertenmodule; jedes Token aktiviert nur ca. 10 % aller Parameter, wodurch die Inferenzkosten reduziert und gleichzeitig die Kapazität erhalten bleibt.
- CISPO-Verstärkungslernen: Ein neuartiger „Clipped IS‑weight Policy Optimization“-Algorithmus, der seltene, aber entscheidende Token im Lernsignal beibehält und so die RL-Stabilität und -Geschwindigkeit beschleunigt.
Die Open-Weight-Version von MiniMax-M1 ermöglicht jedem die Ermöglichung hocheffizienter Inferenz mit ultralangem Kontext und schließt so die Lücke zwischen Forschung und einsetzbarer KI im großen Maßstab.
Erste Schritte
CometAPI bietet eine einheitliche REST-Schnittstelle, die Hunderte von KI-Modellen – einschließlich der ChatGPT-Familie – unter einem konsistenten Endpunkt aggregiert, mit integrierter API-Schlüsselverwaltung, Nutzungskontingenten und Abrechnungs-Dashboards. Anstatt mit mehreren Anbieter-URLs und Anmeldeinformationen zu jonglieren.
Erkunden Sie zunächst die Fähigkeiten der Modelle in der Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben.
Die neueste Integration der MiniMax‑M1 API wird bald auf CometAPI erscheinen, also bleiben Sie dran! Während wir den Upload des MiniMax‑M1-Modells abschließen, erkunden Sie unsere anderen Modelle auf der Modelle-Seite oder probieren Sie sie im KI-Spielplatz. MiniMax' neuestes Modell in CometAPI sind Minimax ABAB7-Vorschau-API kombiniert mit einem nachhaltigen Materialprofil. MiniMax Video-01 API ,siehe:
