Technische Spezifikationen von GPT-5.4 Mini
| Eintrag | GPT-5.4 Mini (geschätzt anhand offizieller Angaben + Kreuzvalidierung) |
|---|---|
| Modellfamilie | GPT-5.4-Serie (kosteneffiziente „Mini“-Variante) |
| Anbieter | OpenAI |
| Eingabetypen | Text, Bild |
| Ausgabetypen | Text |
| Kontextfenster | 400,000 Token |
| Maximale Ausgabetoken | 128,000 Token |
| Wissensstand | ~31. Mai 2024 (erbt die Mini-Linie) |
| Reasoning-Unterstützung | Ja (leichtgewichtig im Vergleich zur Vollversion von GPT-5.4) |
| Tool-Unterstützung | Funktionsaufrufe, Websuche, Dateisuche, Agenten (abgeleitet aus der GPT-5-Familie) |
| Positionierung | Hochgeschwindigkeits-, kosteneffizientes Modell nahe am Spitzenfeld |
Was ist GPT-5.4 Mini?
GPT-5.4 Mini ist eine kosteneffiziente, schnelle Variante von GPT-5.4, die für latenzkritische, hochvolumige Workloads entwickelt wurde. Sie bringt einen erheblichen Teil der Reasoning-, Coding- und multimodalen Fähigkeiten von GPT-5.4 in ein kleineres, schnelleres Modell, das für Systeme im Produktionsmaßstab optimiert ist.
Im Vergleich zu früheren „Mini“-Modellen ist GPT-5.4 Mini als kleines Modell nahe am Spitzenfeld positioniert, d. h. es nähert sich der Leistung von Flaggschiff-Modellen an, während Kosten und Antwortzeit deutlich reduziert werden.
Hauptfunktionen von GPT-5.4 Mini
- Hochgeschwindigkeits-Inferenz: optimiert für Anwendungen mit niedriger Latenz wie Chatbots, Copilots und Echtzeitsysteme
- Großes Kontextfenster (400K): unterstützt lange Dokumente, mehrstufige Workflows und Agentenspeicher
- Starke Programmier- und Agentenunterstützung: ausgelegt für Tool-Nutzung, mehrstufiges Reasoning und delegierte Subagenten-Aufgaben
- Multimodale Eingabe: akzeptiert sowohl Text- als auch Bild-Eingaben für reichhaltigere Workflows
- Kosteneffiziente Skalierung: deutlich günstiger als GPT-5.4 bei weiterhin starker Reasoning-Fähigkeit
- Optimierung von Agenten-Pipelines: ideal für Multi-Modell-Architekturen, bei denen große Modelle planen und Mini-Modelle ausführen
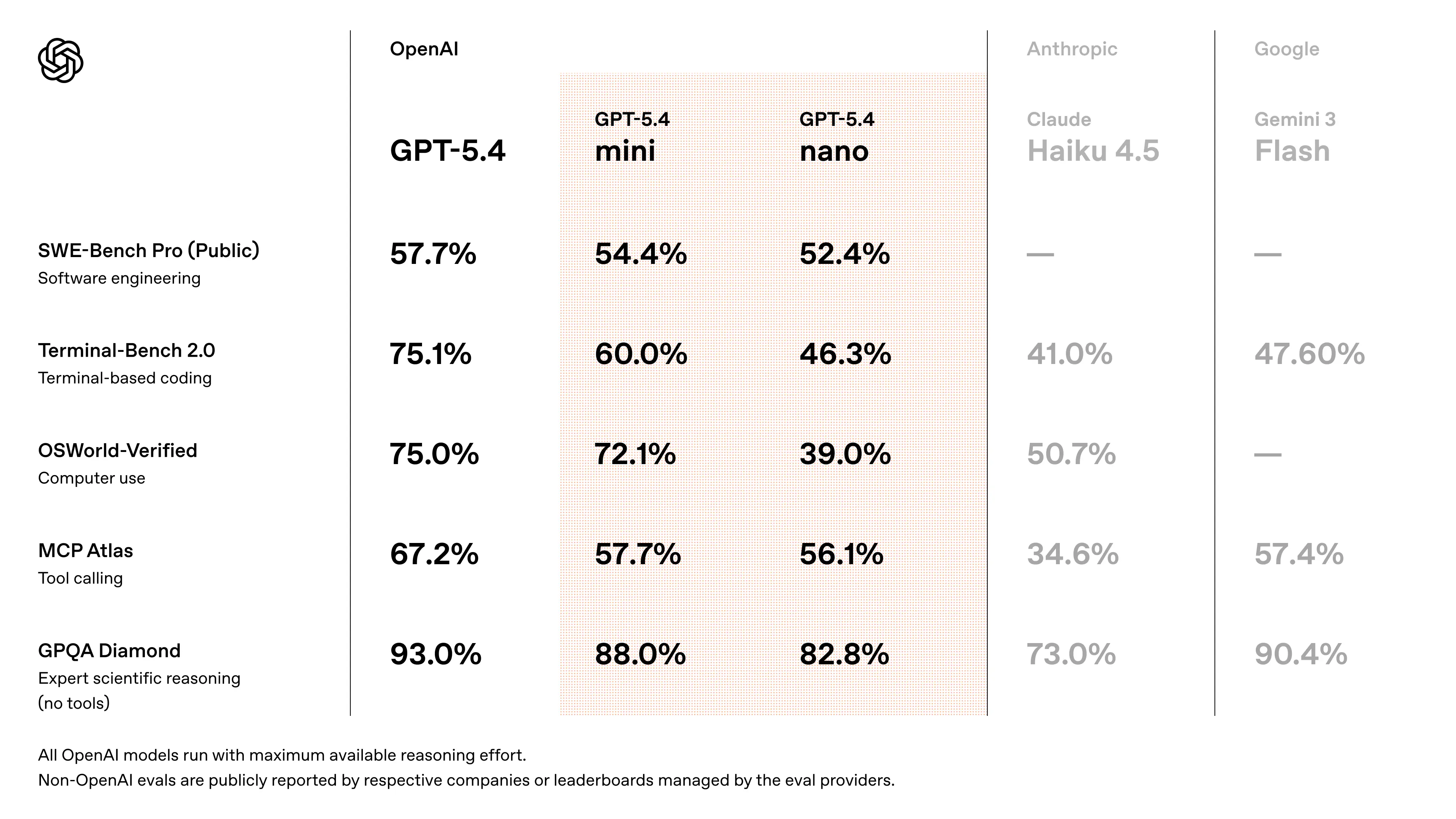
Benchmark-Leistung von GPT-5.4 Mini
- Nähert sich der GPT-5.4-Leistung bei SWE‑Bench‑ähnlichen Programmieraufgaben (~94–95% der Flaggschiff-Leistung) (kreuzvalidierte Schätzung aus Veröffentlichungsdiskussionen)
- Deutliche Verbesserungen gegenüber GPT-5 Mini bei:
- Reasoning-Genauigkeit
- Zuverlässigkeit der Tool-Nutzung
- Multimodalem Verständnis
- Entwickelt, um frühere „Mini“-Generationen in Agenten-Workflows und Coding-Benchmarks zu übertreffen
- Geschwindigkeitsmessungen: frühe API-Tester berichten von ~180–190 Token/s bei GPT-5.4 Mini (vs ~55–120 t/s bei älteren GPT-5-Mini-Varianten, abhängig von Prioritätsmodi).
👉 Zentrale Erkenntnis: GPT-5.4 Mini liefert Leistung nahe am Spitzenfeld bei einem Bruchteil der Kosten und Latenz und ist damit ideal für skalierbare Systeme.
Repräsentative Anwendungsfälle
- Coding-Assistenten & Editoren (IDE-Plugins, Copilot): Schnelles Kontext-Parsing, Codebase-Erkundung und schnelle Completions machen GPT-5.4 Mini ideal für Vorschläge im Editor, bei denen die Time-to-First-Token zählt. GitHub Copilot ist eine frühe Integration.
- Subagenten / delegierte Worker: Ein Master-Agent delegiert kurze, schnelle Aufgaben (Formatierung, kleine Reasoning-Schritte, grep‑ähnliche Suchen) an einen günstigen, schnellen Worker. OpenAI positioniert Mini/Nano für diese Rollen.
- Hochvolumige API‑Automatisierung: Massen-Codegenerierung, automatisierte Ticket-Triage, Logs‑Zusammenfassung in großem Maßstab, bei denen Kosten pro Aufruf und Latenz die Hauptrestriktionen sind. Community-Durchsatzwerte weisen auf spürbare betriebliche Vorteile für Mini hin.
- Tool-Wrapping und Toolchains: Schnelle Tool-Aufrufe, bei denen das Modell externe Tools (Suche, grep, Tests ausführen) orchestriert und kompakte, umsetzbare Ausgaben liefert. Die GPT-5.4-Familie umfasst verbesserte „Computerbenutzung“-Fähigkeiten.
So greifen Sie auf die GPT-5.4 Mini API zu
Schritt 1: Für API-Schlüssel registrieren
Melden Sie sich bei cometapi.com an. Wenn Sie noch kein Nutzer sind, registrieren Sie sich bitte zuerst. Melden Sie sich in Ihrer CometAPI-Konsole an. Rufen Sie den Zugriffsberechtigungs-API-Schlüssel der Schnittstelle ab. Klicken Sie im persönlichen Zentrum beim API-Token auf „Add Token“, erhalten Sie den Token-Schlüssel: sk-xxxxx und senden Sie ihn ab.

Schritt 2: Anfragen an die GPT-5.4 Mini API senden
Wählen Sie den „gpt-5.4-mini“-Endpunkt, um die API-Anfrage zu senden, und legen Sie den Request-Body fest. Die Anfragemethode und der Request-Body sind in der API-Dokumentation unserer Website aufgeführt. Unsere Website bietet außerdem Apifox-Tests zu Ihrer Bequemlichkeit. Ersetzen Sie <YOUR_API_KEY> durch Ihren tatsächlichen CometAPI-Schlüssel aus Ihrem Konto. Die Basis-URL ist Chat Completions und Responses.
Fügen Sie Ihre Frage oder Anforderung in das content-Feld ein — darauf antwortet das Modell. Verarbeiten Sie die API-Antwort, um die generierte Antwort zu erhalten.
Schritt 3: Ergebnisse abrufen und verifizieren
Verarbeiten Sie die API-Antwort, um die generierte Antwort zu erhalten. Nach der Verarbeitung antwortet die API mit dem Aufgabenstatus und den Ausgabedaten.