GLM-4.6 ist das neueste Major-Release in Z.ai’s (früher Zhipu AI) GLM-Familie: ein großsprachiges MoE (Mixture-of-Experts-Modell) der 4. Generation, abgestimmt auf agentenbasierte Workflows, Langkontext-Schlussfolgern und praxisnahe Programmierung. Das Release betont praktische Agent-/Tool-Integration, ein sehr großes Kontextfenster sowie Open-Weights-Verfügbarkeit für lokale Bereitstellung.
Wichtige Funktionen
- Langer Kontext — natives 200K Token Kontextfenster (erweitert von 128K). (docs.z.ai)
- Coding & agentische Fähigkeiten — beworbene Verbesserungen bei praxisnahen Coding-Aufgaben und bessere Tool-Aufrufe für Agenten.
- Effizienz — laut Z.ai-Tests ~30% geringerer Token-Verbrauch gegenüber GLM-4.5.
- Bereitstellung & Quantisierung — erstmals angekündigte FP8- und Int4-Integration für Cambricon-Chips; native FP8-Unterstützung auf Moore Threads via vLLM.
- Modellgröße & Tensortyp — veröffentlichte Artefakte deuten auf ein ~357B-Parameter-Modell (BF16-/F32-Tensoren) auf Hugging Face hin.
Technische Details
Modalitäten & Formate. GLM-4.6 ist ein rein textbasiertes LLM (Eingabe- und Ausgabemodalitäten: Text). Kontextlänge = 200K Token; max. Ausgabe = 128K Token.
Quantisierung & Hardware-Unterstützung. Das Team meldet FP8/Int4-Quantisierung auf Cambricon-Chips und native FP8-Ausführung auf Moore Threads GPUs mit vLLM für Inferenz — wichtig zur Senkung der Inferenzkosten und für On-Premises- sowie inländische Cloud-Bereitstellungen.
Tooling & Integrationen. GLM-4.6 wird über die Z.ai-API, Netzwerke von Drittanbietern (z. B. CometAPI) bereitgestellt und ist in Coding-Agenten integriert (Claude Code, Cline, Roo Code, Kilo Code).
Technische Details
Modalitäten & Formate. GLM-4.6 ist ein rein textbasiertes LLM (Eingabe- und Ausgabemodalitäten: Text). Kontextlänge = 200K Token; max. Ausgabe = 128K Token.
Quantisierung & Hardware-Unterstützung. Das Team meldet FP8/Int4-Quantisierung auf Cambricon-Chips und native FP8-Ausführung auf Moore Threads GPUs mit vLLM für Inferenz — wichtig zur Senkung der Inferenzkosten und für On-Premises- sowie inländische Cloud-Bereitstellungen.
Tooling & Integrationen. GLM-4.6 wird über die Z.ai-API, Netzwerke von Drittanbietern (z. B. CometAPI) bereitgestellt und ist in Coding-Agenten integriert (Claude Code, Cline, Roo Code, Kilo Code).
Benchmark-Leistung
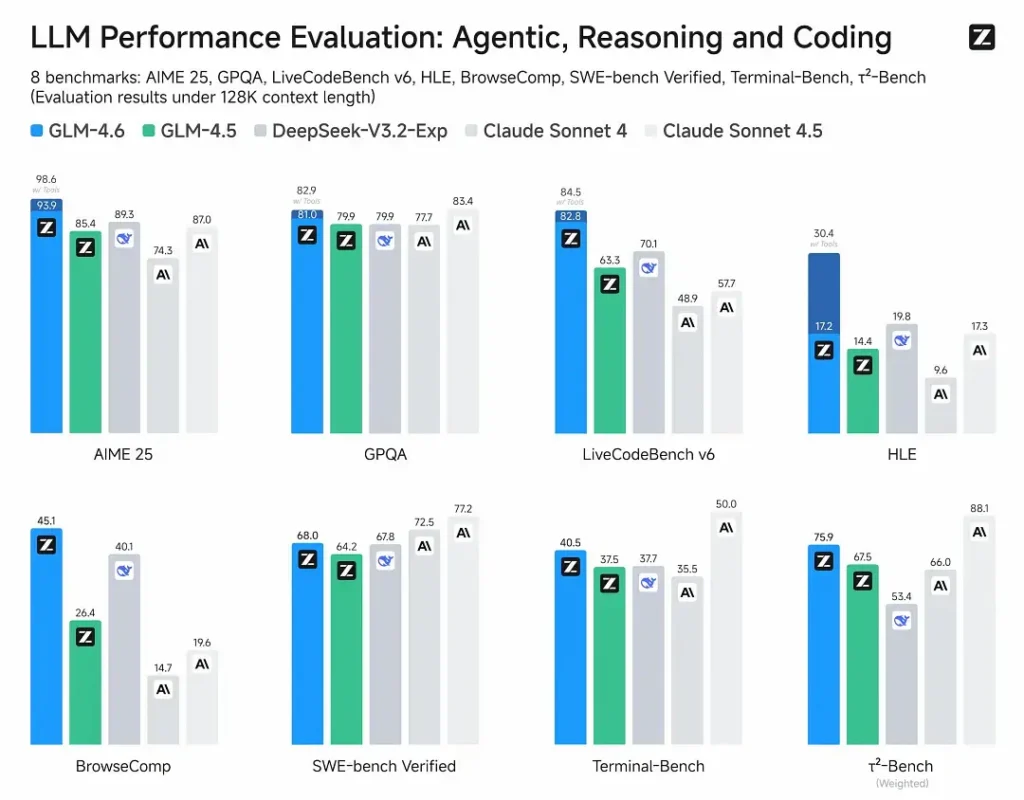
- Veröffentlichte Auswertungen: GLM-4.6 wurde auf acht öffentlichen Benchmarks zu Agenten, Reasoning und Coding getestet und zeigt klare Zugewinne gegenüber GLM-4.5. In menschlich bewerteten, praxisnahen Coding-Tests (erweiterter CC-Bench) verwendet GLM-4.6 ~15% weniger Token als GLM-4.5 und erzielt eine ~48.6% Win-Rate gegenüber Anthropic’s Claude Sonnet 4 (nahezu Gleichstand auf vielen Ranglisten).
- Positionierung: Die Ergebnisse behaupten, GLM-4.6 sei wettbewerbsfähig mit führenden inländischen und internationalen Modellen (genannte Beispiele: DeepSeek-V3.1 und Claude Sonnet 4).
Einschränkungen & Risiken
- Halluzinationen & Fehler: Wie alle aktuellen LLMs kann GLM-4.6 faktische Fehler machen — die Z.ai-Dokumentation warnt explizit, dass Ausgaben Fehler enthalten können. Nutzer sollten für kritische Inhalte Verifikation & Retrieval/RAG anwenden.
- Modellkomplexität & Betriebskosten: 200K Kontext und sehr große Ausgaben erhöhen Speicher- und Latenzanforderungen deutlich und können die Inferenzkosten steigern; Quantisierung/Inferenz-Engineering ist erforderlich für den Betrieb im großen Maßstab.
- Domänenlücken: Obwohl GLM-4.6 starke Agent-/Coding-Leistung meldet, weisen einige öffentliche Berichte darauf hin, dass es in bestimmten Mikrobenchmarks noch hinter einigen Versionen konkurrierender Modelle liegt (z. B. einige Coding-Metriken vs Sonnet 4.5). Aufgabenbezogen evaluieren, bevor Produktivmodelle ersetzt werden.
- Sicherheit & Richtlinien: Offene Gewichte erhöhen die Zugänglichkeit, werfen aber auch Fragen der Verantwortlichkeit auf (Gegenmaßnahmen, Leitplanken und Red-Teaming liegen in der Verantwortung der Nutzer).
Anwendungsfälle
- Agentische Systeme & Tool-Orchestrierung: lange Agenten-Traces, Multi-Tool-Planung, dynamische Tool-Aufrufe; das agentische Tuning des Modells ist ein zentrales Verkaufsargument.
- Praxisnahe Coding-Assistenten: mehrstufige Codegenerierung, Code-Review und interaktive IDE-Assistenten (integriert in Claude Code, Cline, Roo Code — laut Z.ai). Verbesserungen der Token-Effizienz machen es attraktiv für Entwicklerpläne mit hoher Nutzung.
- Workflows für lange Dokumente: Zusammenfassung, Synthese über mehrere Dokumente, lange rechtliche/technische Reviews dank des 200K-Fensters.
- Content-Erstellung & virtuelle Charaktere: ausgedehnte Dialoge, konsistente Pflege einer Persona in mehrstufigen Szenarien.
Vergleich von GLM-4.6 mit anderen Modellen
- GLM-4.5 → GLM-4.6: Sprung bei Kontextgröße (128K → 200K) und Token-Effizienz (~15% weniger Token auf CC-Bench); verbesserte Agent-/Tool-Nutzung.
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5: Z.ai berichtet nahezu Gleichstand auf mehreren Leaderboards und eine ~48.6% Win-Rate bei den CC-Bench-Coding-Aufgaben (also enge Konkurrenz, mit einigen Mikrobenchmarks, in denen Sonnet noch führt). Für viele Engineering-Teams ist GLM-4.6 als kosteneffiziente Alternative positioniert.
- GLM-4.6 vs andere Langkontext-Modelle (DeepSeek, Gemini-Varianten, GPT-4-Familie): GLM-4.6 betont großen Kontext & agentische Coding-Workflows; relative Stärken hängen von der Metrik ab (Token-Effizienz/Agent-Integration vs reine Code-Synthese-Genauigkeit oder Sicherheits-Pipelines). Die Auswahl sollte empirisch und aufgabengetrieben erfolgen.
Zhipu AI’s neuestes Flaggschiffmodell GLM-4.6 veröffentlicht: 355B Gesamtparameter, 32B aktiv. Übertrifft GLM-4.5 in allen Kernfähigkeiten.
- Coding: Auf Augenhöhe mit Claude Sonnet 4, bestes in China.
- Kontext: Erweitert auf 200K (von 128K).
- Reasoning: Verbessert, unterstützt Tool-Aufrufe während der Inferenz.
- Suche: Verbesserte Tool-Aufrufe und Agentenleistung.
- Schreiben: Bessere Ausrichtung an menschlichen Präferenzen bei Stil, Lesbarkeit und Rollenspiel.
- Mehrsprachig: Gestärkte Übersetzungen über Sprachgrenzen hinweg.