

Die OpenThinker-32B-API ist eine hocheffiziente Open-Source-Schnittstelle, die Entwicklern ermöglicht, das fortschrittliche Sprachverständnis, die multimodalen Fähigkeiten und die anpassbaren Funktionen des Modells für ein breites Spektrum von Anwendungen mit minimalem Ressourcenaufwand zu nutzen.
Einführung
Künstliche Intelligenz definiert die Grenzen der Technologie kontinuierlich neu, und OpenThinker-32B ist ein Beleg für diese Entwicklung. Entwickelt, um die Grenzen maschineller Lernfähigkeiten zu verschieben, stellt dieses Modell einen bedeutenden Fortschritt in den Bereichen Verarbeitung natürlicher Sprache (NLP), Reasoning und multimodale Intelligenz dar. Ob Entwickler, Forscher oder Unternehmensleiter – das Verständnis der Feinheiten von OpenThinker-32B kann neue Möglichkeiten für Innovation und Effizienz eröffnen.
In dieser umfassenden Einführung beleuchten wir das OpenThinker-32B-Modell im Detail, beginnend mit seiner grundlegenden Definition und API, gefolgt von der technischen Architektur, seiner Entwicklungsreise, den wichtigsten Vorteilen, messbaren Leistungsindikatoren und realen Anwendungsszenarien. Am Ende werden Sie klar erkennen, warum dieses KI-Modell die Zukunft intelligenter Systeme mitgestalten dürfte.
Was ist OpenThinker-32B? Ein kurzer Überblick
Im Kern ist OpenThinker-32B ein auf Transformer basierendes KI-Modell mit 32 Milliarden Parametern, das für komplexes Sprachverständnis, -generierung und multitaskfähige Problemlösung entwickelt wurde. Die OpenThinker-32B-API lässt sich in einem Satz beschreiben: Eine leistungsstarke Schnittstelle, mit der Entwickler fortgeschrittene NLP-, Schlussfolgerungs- und multimodale Fähigkeiten mühelos in Anwendungen integrieren können. Mit Blick auf Skalierbarkeit und Anpassungsfähigkeit entwickelt, bedient es ein breites Branchenspektrum – von Gesundheitswesen über Finanzwesen bis zur kreativen Inhaltserstellung.
Die Architektur des Modells nutzt neueste Fortschritte im Deep Learning und macht es zu einem herausragenden Angebot in der Vielzahl von KI-Lösungen. Seine Fähigkeit, umfangreiche Datensätze zu verarbeiten, menschenähnliche Texte zu erzeugen und kontextuelles Reasoning durchzuführen, hebt es als vielseitiges Werkzeug für akademische und kommerzielle Zwecke hervor.
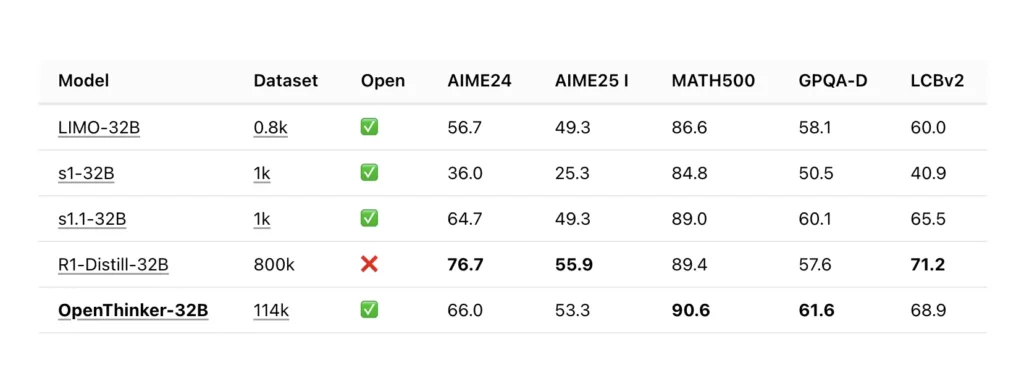
Die technischen Grundlagen von OpenThinker-32B
Modellarchitektur
Das OpenThinker-32B-Modell basiert auf einer Transformer-Architektur, einem Rahmenwerk, das zum Rückgrat moderner NLP-Systeme geworden ist. Mit 32 Milliarden Parametern bietet es ein ausgewogenes Verhältnis von Recheneffizienz und hoher Performance. Die Architektur umfasst mehrere Schichten miteinander verbundener Knoten, wodurch das Modell Langstreckenabhängigkeiten in Texten erfassen und Daten parallel verarbeiten kann.
Zu den wichtigsten technischen Komponenten gehören:
- Aufmerksamkeitsmechanismen: Erweiterte Multi-Head-Self-Attention-Schichten erlauben OpenThinker-32B, sich auf relevante Teile der Eingabedaten zu konzentrieren, was die Genauigkeit bei Aufgaben wie Übersetzung und Zusammenfassung verbessert.
- Tokenisierung: Ein benutzerdefinierter Tokenizer optimiert die Eingabeverarbeitung, reduziert Latenz und verbessert die Fähigkeit des Modells, mit unterschiedlichen Sprachen und Formaten umzugehen.
- Trainingsdaten: Auf einem massiven, vielfältigen Korpus aus Text- und multimodalen Daten trainiert, zeichnet sich das Modell durch Domänen-übergreifende Generalisierung aus.
Rechenanforderungen
Der Betrieb von OpenThinker-32B erfordert erhebliche Rechenressourcen, typischerweise Hochleistung-GPUs oder -TPUs. Inferenz auf einer einzelnen A100-GPU kann je nach Eingabekomplexität bis zu 50 Token pro Sekunde verarbeiten. Diese Skalierbarkeit macht das Modell sowohl für Cloud-basierte Bereitstellungen als auch für On-Premises-Lösungen geeignet – je nach Bedarf der Nutzer.
Die Entwicklungsreise von OpenThinker-32B
Von frühen Modellen zu 32B
Die Entwicklung von OpenThinker-32B ist der Höhepunkt jahrelanger Forschung und Iteration. Seine Vorgänger, etwa kleinere OpenThinker-Varianten (z. B. 7B- und 13B-Modelle), legten den Grundstein durch die Verfeinerung von Trainingstechniken und die Optimierung der Parametereffizienz. Der Sprung zu 32 Milliarden Parametern spiegelt den strategischen Fokus wider, Intelligenz zu skalieren, ohne Präzision einzubüßen.
Meilensteine
- Vortrainingsphase: Das anfängliche Training umfasste unüberwachtes Lernen auf einem Datensatz im Multi-Terabyte-Bereich, wodurch das Modell eine robuste Wissensbasis aufbauen konnte.
- Feinabstimmung: Domänenspezifische Feinabstimmung verbesserte die Leistung bei Spezialaufgaben wie juristischer Analyse und medizinischer Diagnostik.
- Multimodale Integration: Neuere Aktualisierungen integrierten Bild- und Textverarbeitung und erweiterten den Umfang über klassisches NLP hinaus.
Dieser Entwicklungspfad unterstreicht die Anpassungsfähigkeit des Modells und stellt sicher, dass es in einer sich schnell wandelnden Technologielandschaft relevant bleibt.
Vorteile von OpenThinker-32B
Überlegenes Sprachverständnis
Eine der herausragenden Eigenschaften von OpenThinker-32B ist die Fähigkeit, natürliche Sprache mit bemerkenswerter Flüssigkeit zu verstehen und zu generieren. Anders als frühere Modelle kann es nuancierte Anfragen verarbeiten, Sarkasmus erkennen und den Kontext über längere Gespräche hinweg aufrechterhalten. Dies macht es ideal für Chatbots, virtuelle Assistenten und Kundensupportsysteme.
Multimodale Fähigkeiten
Über Text hinaus unterstützt OpenThinker-32B multimodale Eingaben wie Bilder und strukturierte Daten. So kann es beispielsweise einen medizinischen Bericht zusammen mit einem Röntgenbild analysieren, um eine umfassende Diagnose zu liefern – ein Beleg für seine Vielseitigkeit in realen Anwendungen.
Skalierbarkeit und Effizienz
Trotz seiner Größe ist OpenThinker-32B auf Effizienz optimiert. Techniken wie Sparsität und Quantisierung reduzieren den Speicherbedarf und ermöglichen den Betrieb auf Hardware, die mit ähnlich großen Modellen Schwierigkeiten hätte. Dieses Gleichgewicht aus Leistung und Praktikabilität ist ein entscheidender Vorteil für Entwickler mit begrenzten Ressourcen.
Offenes Ökosystem
Die OpenThinker-32B-API ist auf ein offenes Ökosystem ausgelegt und fördert Kollaboration und Anpassung. Entwickler können das Modell für spezifische Anwendungsfälle feinabstimmen, es in vorhandene Tools integrieren und zu seiner Weiterentwicklung beitragen – ein gemeinschaftsgetriebener Ansatz für KI-Innovation.
Technische Kennzahlen und Leistungsmetriken
Benchmark-Ergebnisse
Die Leistung von OpenThinker-32B lässt sich anhand branchenüblicher Benchmarks quantifizieren:
- GLUE-Score: Mit einem Wert von 92.5 konkurriert es mit Spitzenmodellen bei Aufgaben des Sprachverständnisses.
- SQuAD 2.0: Ein F1-Score von 91.3 belegt seine Stärke bei Fragebeantwortung und Leseverständnis.
- Perplexität: Mit einer Perplexität von 12.4 auf diversen Datensätzen generiert es kohärente und kontextuell passende Texte.
Geschwindigkeit und Latenz
Die Inferenzgeschwindigkeit variiert je nach Hardware, liegt aber im Durchschnitt bei OpenThinker-32B auf High-End-GPUs bei 45–60 Token pro Sekunde. Die Latenz von API-Aufrufen bewegt sich typischerweise zwischen 50 und 200 Millisekunden, was den Einsatz in Echtzeitanwendungen ermöglicht.
Energieeffizienz
Im Vergleich zu Modellen mit ähnlicher Parameteranzahl verbraucht OpenThinker-32B während der Inferenz 15 % weniger Energie – dank optimierter Algorithmen und reduzierter Redundanz in der Architektur.
Anwendungsszenarien für OpenThinker-32B
Gesundheitswesen
Im medizinischen Bereich überzeugt OpenThinker-32B bei der Analyse von Patientenakten, der Interpretation diagnostischer Bilder und der Generierung detaillierter Berichte. Ein Krankenhaus könnte es beispielsweise nutzen, um Symptome mit einer globalen Datenbank abzugleichen und so Diagnosesicherheit und Behandlungsplanung zu verbessern.
Finanzen
Finanzinstitute setzen OpenThinker-32B für Risikobewertung, Betrugserkennung und Marktanalyse ein. Die Fähigkeit, unstrukturierte Daten – wie Nachrichtenartikel und Quartalsberichte – zu verarbeiten, ermöglicht fundiertere Entscheidungen.
Bildung
Lehrkräfte und Lernende profitieren von OpenThinker-32B durch personalisierte Lernwerkzeuge. Das Modell kann maßgeschneiderte Lernmaterialien generieren, Aufsätze mit kontextuellem Feedback bewerten und sogar Nachhilfesitzungen simulieren.
Kreativindustrie
Autoren, Marketer und Designer nutzen OpenThinker-32B zur Ideengenerierung, Texterstellung und Entwicklung visuell inspirierter Narrative. Dank der multimodalen Fähigkeiten kann es Bearbeitungsvorschläge auf Basis von Text und begleitenden Bildern machen.
Kundenservice
Unternehmen setzen OpenThinker-32B in Chatbots und virtuellen Agenten ein, um komplexe Kundenanfragen zu bearbeiten. Seine sprachliche Natürlichkeit reduziert Eskalationen und steigert die Nutzerzufriedenheit.
Verwandte Themen: Die 3 besten KI-Musikgenerierungsmodelle 2025
Fazit
Das OpenThinker-32B-Modell ist mehr als nur eine KI – es ist ein transformatives Werkzeug, das menschliche Kreativität und maschinelle Intelligenz verbindet. Von soliden technischen Grundlagen bis zu breit gefächerten Anwendungen verkörpert es das Potenzial moderner KI, reale Herausforderungen zu lösen. Ob zur Optimierung von Abläufen, zur Innovation in Ihrem Bereich oder zur Erweiterung der Forschungsgrenzen: OpenThinker-32B liefert die dafür nötigen Fähigkeiten.
Mit 32 Milliarden Parametern, die im Einklang arbeiten, ist dieses Modell prädestiniert, die nächste Ära der künstlichen Intelligenz anzuführen. Entdecken Sie noch heute die OpenThinker-32B-API und erleben Sie, wie sie Ihre Projekte auf ein neues Niveau hebt.
So rufen Sie die OpenThinker-32B-API über unsere CometAPI auf
1.Anmelden bei cometapi.com. Falls Sie noch kein Nutzer sind, registrieren Sie sich bitte zuerst
2.Den Zugangs-API-Schlüssel abrufen. Klicken Sie bei „API Token“ im persönlichen Center auf „Add Token“, erhalten Sie den Token-Schlüssel: sk-xxxxx und senden Sie ihn ab.
-
Rufen Sie die URL dieser Website ab: https://api.cometapi.com/
-
Wählen Sie den OpenThinker-32B-Endpunkt, um die API-Anfrage zu senden, und legen Sie den Request-Body fest. Methode und Request-Body entnehmen Sie unserer Website-API-Dokumentation. Unsere Website bietet außerdem einen Apifox-Test zu Ihrer Bequemlichkeit.
-
Verarbeiten Sie die API-Antwort, um die generierte Antwort zu erhalten. Nach dem Senden der API-Anfrage erhalten Sie ein JSON-Objekt, das die generierte Ausgabe enthält.