

In der sich rasant entwickelnden Landschaft der künstlichen Intelligenz hat das Jahr 2025 bedeutende Fortschritte bei großen Sprachmodellen (LLMs) gebracht. Zu den Spitzenreitern zählen Alibabas Qwen2.5, DeepSeeks V3- und R1-Modelle sowie OpenAIs ChatGPT. Jedes dieser Modelle bringt einzigartige Fähigkeiten und Innovationen mit sich. Dieser Artikel befasst sich mit den neuesten Entwicklungen rund um Qwen2.5 und vergleicht dessen Funktionen und Leistung mit DeepSeek und ChatGPT, um herauszufinden, welches Modell derzeit im KI-Rennen führend ist.
Was ist Qwen2.5?
Übersicht
Qwen 2.5 ist Alibaba Clouds neuestes dichtes, nur auf Decoder basierendes Großsprachenmodell und in verschiedenen Größen von 0.5 bis 72 Milliarden Parametern erhältlich. Es ist optimiert für Anweisungsfolgen, strukturierte Ausgaben (z. B. JSON, Tabellen), Codierung und mathematische Problemlösung. Mit Unterstützung für über 29 Sprachen und einer Kontextlänge von bis zu 128 Token ist Qwen2.5 für mehrsprachige und domänenspezifische Anwendungen konzipiert.
Hauptfunktionen
- Mehrsprachige Unterstützung: Unterstützt über 29 Sprachen und bedient eine globale Benutzerbasis.
- Erweiterte Kontextlänge: Verarbeitet bis zu 128 Token und ermöglicht so die Verarbeitung langer Dokumente und Konversationen.
- Spezialisierte Varianten: Enthält Modelle wie Qwen2.5-Coder für Programmieraufgaben und Qwen2.5-Math zur Lösung mathematischer Probleme.
- Barierrefreiheit: Verfügbar über Plattformen wie Hugging Face, GitHub und eine neu gestartete Weboberfläche unter chat.qwenlm.ai.
Wie verwende ich Qwen 2.5 lokal?
Nachfolgend finden Sie eine Schritt-für-Schritt-Anleitung für die 7 B Chat Kontrollpunkt; größere Größen unterscheiden sich nur in den GPU-Anforderungen.
1. Hardwarevoraussetzungen
| Modell | vRAM für 8‑Bit | vRAM für 4‑Bit (QLoRA) | Festplattengröße |
|---|---|---|---|
| Qwen 2.5‑7B | 14GB | 10GB | 13GB |
| Qwen 2.5‑14B | 26GB | 18GB | 25GB |
Eine einzelne RTX 4090 (24 GB) reicht für 7 B Inferenz bei voller 16-Bit-Präzision; zwei solcher Karten oder CPU-Offload plus Quantisierung können 14 B verarbeiten.
2. Installation
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Schnelles Inferenzskript
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
Die trust_remote_code=True Flagge ist erforderlich, weil Qwen eine benutzerdefinierte Einbettung der Drehposition Verpackung.
4. Feinabstimmung mit LoRA
Dank parametereffizienter LoRA-Adapter können Sie Qwen auf einer einzigen 50-GB-GPU in weniger als vier Stunden auf ca. 24 Domänenpaaren (z. B. im medizinischen Bereich) spezialisieren:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Die resultierende Adapterdatei (~120 MB) kann wieder zusammengeführt oder bei Bedarf geladen werden.
Optional: Qwen 2.5 als API ausführen
CometAPI fungiert als zentraler Hub für APIs mehrerer führender KI-Modelle, sodass die separate Zusammenarbeit mit mehreren API-Anbietern entfällt. CometAPI Bietet einen deutlich günstigeren Preis als den offiziellen Preis für die Integration der Qwen-API. Nach der Registrierung und Anmeldung erhalten Sie 1 $ auf Ihr Konto! Registrieren Sie sich und erleben Sie CometAPI. Für Entwickler, die Qwen 2.5 in Anwendungen integrieren möchten:
Schritt 1: Installieren Sie die erforderlichen Bibliotheken:
bash
pip install requests
Schritt 2: API-Schlüssel erhalten
- Navigieren CometAPI.
- Melden Sie sich mit Ihrem CometAPI-Konto an.
- Wähle aus Konto-Dashboard.
- Klicken Sie auf „API-Schlüssel abrufen“ und folgen Sie den Anweisungen, um Ihren Schlüssel zu generieren.
Schritt 3: Implementieren von API-Aufrufen
Nutzen Sie die API-Anmeldeinformationen, um Anfragen an Qwen 2.5 zu stellen.Ersetzen mit Ihrem aktuellen CometAPI-Schlüssel aus Ihrem Konto.
Zum Beispiel in Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Diese Integration ermöglicht die nahtlose Einbindung der Funktionen von Qwen 2.5 in verschiedene Anwendungen und verbessert so die Funktionalität und das Benutzererlebnis. Wählen Sie die “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” Endpunkt zum Senden der API-Anfrage und Festlegen des Anfragetexts. Die Anfragemethode und der Anfragetext stammen aus der API-Dokumentation unserer Website. Unsere Website bietet außerdem einen Apifox-Test für Ihren Komfort.
Bitte beachten Sie Qwen 2.5 Max API für Integrationsdetails. CometAPI hat die neuesten QwQ-32B-APIWeitere Modellinformationen zur Comet-API finden Sie unter API-Dokument.
Best Practices und Tipps
| Szenario | Software Empfehlungen |
|---|---|
| Fragen und Antworten zum langen Dokument | Teilen Sie Passagen in ≤16 Token auf und verwenden Sie zur Reduzierung der Latenz erweiterte Abfrageaufforderungen anstelle von naiven 100-Kontexten. |
| Strukturierte Ausgaben | Stellen Sie der Systemnachricht Folgendes voran: You are an AI that strictly outputs JSON. Das Ausrichtungstraining von Qwen 2.5 zeichnet sich durch eingeschränkte Generierung aus. |
| Code-Vervollständigung | Stelle den temperature=0.0 kombiniert mit einem nachhaltigen Materialprofil. top_p=1.0 Um den Determinismus zu maximieren, probieren Sie dann mehrere Strahlen aus (num_return_sequences=4) für die Rangfolge. |
| Sicherheitsfilterung | Verwenden Sie als ersten Durchgang das Open-Source-Regex-Paket „Qwen-Guardrails“ von Alibaba oder Textmoderation-004 von OpenAI. |
Bekannte Einschränkungen von Qwen 2.5
- Schnelle Injektionsempfindlichkeit. Externe Prüfungen zeigen eine Jailbreak-Erfolgsrate von 18 % bei Qwen 2.5‑VL – ein Hinweis darauf, dass die bloße Modellgröße keinen Schutz vor feindlichen Anweisungen bietet.
- Nicht-lateinisches OCR-Rauschen. Bei der Feinabstimmung für Vision-Language-Aufgaben verwechselt die End-to-End-Pipeline des Modells manchmal traditionelle und vereinfachte chinesische Glyphen, sodass domänenspezifische Korrekturebenen erforderlich sind.
- GPU-Speicherüberschreitung bei 128 K. FlashAttention‑2 gleicht RAM aus, aber ein dichter Vorwärtsdurchlauf von 72 B über 128 K Token erfordert immer noch >120 GB vRAM; Anwender sollten Window‑Attention oder KV‑Cache verwenden.
Roadmap und Community-Ökosystem
Das Qwen-Team hat angedeutet, Qwen 3.0, das auf ein hybrides Routing-Backbone (Dense + MoE) und ein einheitliches Sprach-Vision-Text-Vortraining abzielt. Das Ökosystem umfasst bereits:
- Q‑Agent – ein Gedankenkettenagent im ReAct-Stil, der Qwen 2.5-14B als Richtlinie verwendet.
- Chinesisches Finanz-Alpaka – ein LoRA auf Qwen2.5‑7B, trainiert mit 1 Mio. behördlichen Anmeldungen.
- Open Interpreter-Plug-in – tauscht GPT‑4 gegen einen lokalen Qwen-Checkpoint in VS Code.
Auf der Seite „Qwen2.5-Sammlung“ von Hugging Face finden Sie eine ständig aktualisierte Liste mit Prüfpunkten, Adaptern und Evaluierungskabelbäumen.
Vergleichsanalyse: Qwen2.5 vs. DeepSeek und ChatGPT
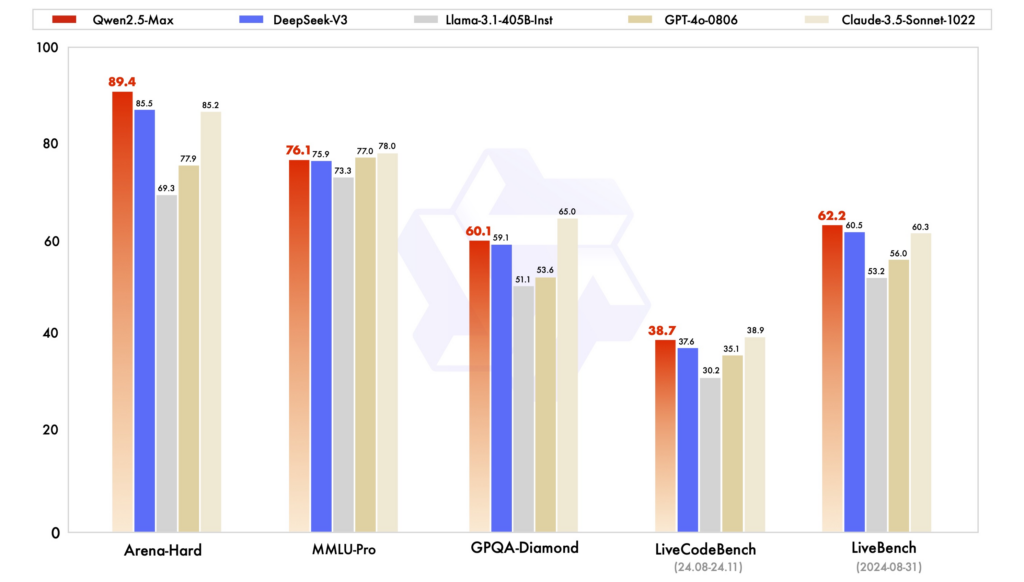
Leistungsbenchmarks: In verschiedenen Evaluierungen zeigte Qwen2.5 eine starke Leistung bei Aufgaben, die logisches Denken, Programmieren und mehrsprachiges Verständnis erfordern. DeepSeek-V3 mit seiner MoE-Architektur zeichnet sich durch Effizienz und Skalierbarkeit aus und bietet hohe Leistung bei reduziertem Rechenaufwand. ChatGPT bleibt ein robustes Modell, insbesondere bei allgemeinen Sprachaufgaben.
Effizienz und Kosten: Die Modelle von DeepSeek zeichnen sich durch kostengünstiges Training und Inferenz aus. Sie nutzen MoE-Architekturen, um nur die notwendigen Parameter pro Token zu aktivieren. Qwen2.5 bietet trotz seiner hohen Komplexität spezielle Varianten zur Leistungsoptimierung für bestimmte Aufgaben. Das Training von ChatGPT erforderte erhebliche Rechenressourcen, was sich in den Betriebskosten widerspiegelt.
Zugänglichkeit und Open-Source-Verfügbarkeit: Qwen2.5 und DeepSeek setzen in unterschiedlichem Maße auf Open-Source-Prinzipien und bieten Modelle auf Plattformen wie GitHub und Hugging Face an. Die kürzlich erfolgte Einführung einer Weboberfläche für Qwen2.5 verbessert die Zugänglichkeit. ChatGPT ist zwar nicht Open Source, aber über die Plattform und Integrationen von OpenAI allgemein zugänglich.
Fazit
Qwen 2.5 liegt an einem Sweet Spot zwischen Premiumdienste mit geschlossenem Gewicht kombiniert mit einem nachhaltigen Materialprofil. vollständig geöffnete Bastlermodelle. Seine Kombination aus freizügiger Lizenzierung, Mehrsprachigkeit, Kompetenz im Langzeitkontext und einer breiten Palette von Parameterskalen macht es zu einer überzeugenden Grundlage sowohl für die Forschung als auch für die Produktion.
Während die Open-Source-LLM-Landschaft rasant voranschreitet, zeigt das Qwen-Projekt, dass Transparenz und Leistung können koexistierenFür Entwickler, Datenwissenschaftler und politische Entscheidungsträger ist die Beherrschung von Qwen 2.5 heute eine Investition in eine pluralistischere, innovationsfreundlichere KI-Zukunft.