
Qwen3-Max-Preview ist Alibabas neuestes Flaggschiff-Vorschaumodell in der Qwen3-Familie – ein Modell mit über einer Billion Parametern im Mixture-of-Experts-Stil (MoE) mit einem ultralangen Kontextfenster von 262 Token, das als Vorschau für den Einsatz in Unternehmen/der Cloud veröffentlicht wurde. Es zielt auf *Tiefgründiges Denken, Verständnis langer Dokumente, Codierung und agentische Arbeitsabläufe.
Grundlegende Informationen und Hauptmerkmale
- Name / Bezeichnung:
qwen3-max-preview(Anweisen). - Maßstab: Über 1 Billion Parameter (Billionen-Parameter-Flaggschiff). Dies ist der wichtigste Marketing-/Statistik-Meilenstein für die Veröffentlichung.
- Kontextfenster: 262,144-Token (unterstützt sehr lange Eingaben und Transkripte mit mehreren Dateien).
- Modus(e): Anweisungsoptimierte „Instruct“-Variante mit Unterstützung für Denken (absichtlicher Gedankengang) und Nichtdenken schnelle Modi in der Qwen3-Familie.
- Verfügbarkeit: Vorschauzugriff über Qwen-Chat, Alibaba Cloud Model Studio (OpenAI-kompatible oder DashScope-Endpunkte) und Routing-Anbieter wie CometAPI.
Technische Details (Architektur und Modi)
- Die Architektur: Qwen3-Max folgt der Qwen3-Designlinie, die eine Mischung aus dicht + Expertenmischung (MoE) Komponenten in größeren Varianten sowie technische Entscheidungen zur Optimierung der Inferenzeffizienz bei sehr großen Parameterzahlen.
- Denkmodus vs. Nicht-Denkmodus: Die Qwen3-Serie führte ein Denkmodus (für mehrstufige Ergebnisse im Stil einer Gedankenkette) und Nicht-Denkmodus für schnellere, präzisere Antworten; die Plattform stellt Parameter bereit, um diese Verhaltensweisen umzuschalten.
- Kontext-Caching/Leistungsmerkmale: Model Studio-Listen Kontextcache Unterstützung für große Anfragen, um die Kosten wiederholter Eingaben zu reduzieren und den Durchsatz bei wiederholten Kontexten zu verbessern.
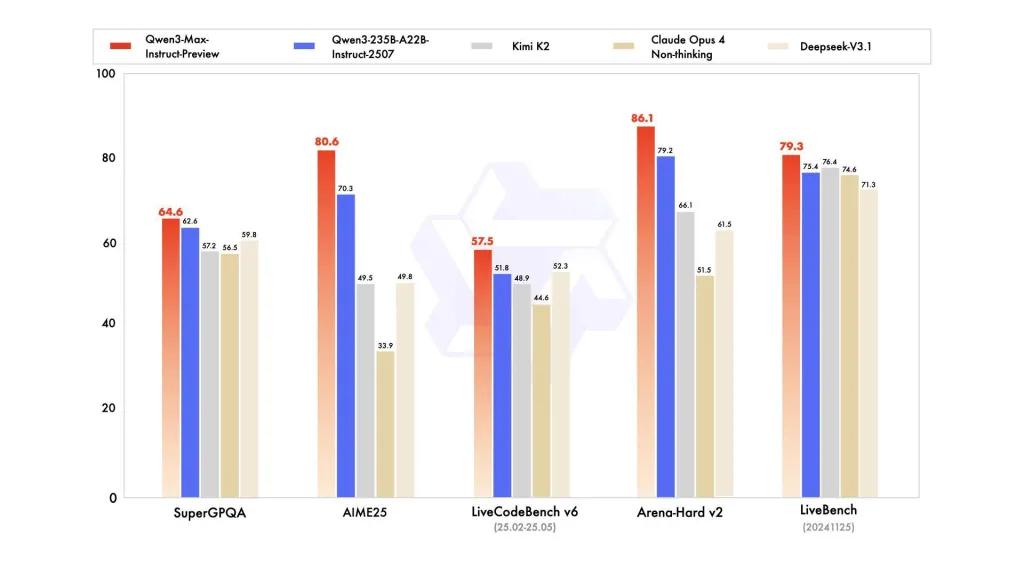
Benchmark-Leistung
Berichte beziehen sich auf SuperGPQA, LiveCodeBench-Varianten, AIME25 und andere Wettbewerbs-/Benchmark-Suiten, bei denen Qwen3-Max konkurrenzfähig oder führend erscheint.
Einschränkungen und Risiken (Praxis- und Sicherheitshinweise)
- Deckkraft für vollständiges Trainingsrezept / Gewichte: Als Vorschau können die vollständige Trainings-/Daten-/Gewichtungsfreigabe und die Reproduzierbarkeitsmaterialien im Vergleich zu früheren Qwen3-Versionen mit offenem Gewicht eingeschränkt sein. Einige Modelle der Qwen3-Familie wurden mit offenem Gewicht freigegeben, Qwen3-Max wird jedoch als kontrollierte Vorschau für den Cloud-Zugriff bereitgestellt. Dies verringert die Reproduzierbarkeit für unabhängige Forscher.
- Halluzinationen & Faktizität: Anbieterberichte behaupten, dass Halluzinationen reduziert werden, doch in der Praxis werden sich weiterhin sachliche Fehler und überzogene Behauptungen zeigen – es gelten die üblichen LLM-Vorbehalte. Vor einem riskanten Einsatz ist eine unabhängige Bewertung erforderlich.
- Kosten im Maßstab: Mit einem riesigen Kontextfenster und hoher Leistungsfähigkeit Token-Kosten kann bei sehr langen Eingabeaufforderungen oder Produktionsdurchsatz erheblich sein. Verwenden Sie Caching, Chunking und Budgetkontrollen.
- Überlegungen zu Regulierung und Datensouveränität: Unternehmensbenutzer sollten vor der Verarbeitung vertraulicher Informationen die Alibaba Cloud-Regionen, den Datenstandort und die Compliance-Auswirkungen prüfen. (Die Model Studio-Dokumentation enthält regionsspezifische Endpunkte und Hinweise.)
Anwendungsszenarien
- Dokumentenverständnis/-zusammenfassung im großen Maßstab: juristische Schriftsätze, technische Spezifikationen und Wissensdatenbanken mit mehreren Dateien (Vorteil: 262K-Token Fenster).
- Code-Argumentation im Langzeitkontext und Code-Unterstützung im Repository-Maßstab: Verständnis von Code in mehreren Dateien, umfangreiche PR-Überprüfungen, Refactoring-Vorschläge auf Repository-Ebene.
- Aufgaben zum komplexen Denken und zur Denkkettenbildung: Mathewettbewerbe, mehrstufige Planung, agentenbasierte Arbeitsabläufe, bei denen „denkende“ Spuren die Rückverfolgbarkeit unterstützen.
- Mehrsprachige, unternehmensweite Fragen und Antworten sowie strukturierte Datenextraktion: Unterstützung großer mehrsprachiger Korpora und strukturierte Ausgabefunktionen (JSON/Tabellen).
So rufen Sie die Qqwen3-max-preview-API von CometAPI auf
qwen3-max-preview API-Preise in CometAPI, 20 % Rabatt auf den offiziellen Preis:
| Eingabetoken | $0.24 |
| Ausgabetoken | $2.42 |
Erforderliche Schritte
- Einloggen in cometapi.comWenn Sie noch nicht unser Benutzer sind, registrieren Sie sich bitte zuerst
- Holen Sie sich den API-Schlüssel für die Zugangsdaten der Schnittstelle. Klicken Sie im persönlichen Bereich beim API-Token auf „Token hinzufügen“, holen Sie sich den Token-Schlüssel: sk-xxxxx und senden Sie ihn ab.
- Holen Sie sich die URL dieser Site: https://api.cometapi.com/
Methode verwenden
- Wählen Sie den Endpunkt „qwen3-max-preview“, um die API-Anfrage zu senden und den Anfragetext festzulegen. Die Anfragemethode und der Anfragetext finden Sie in der API-Dokumentation unserer Website. Unsere Website bietet außerdem einen Apifox-Test für Ihren Komfort.
- Ersetzen mit Ihrem aktuellen CometAPI-Schlüssel aus Ihrem Konto.
- Geben Sie Ihre Frage oder Anfrage in das Inhaltsfeld ein – das Modell antwortet darauf.
- . Verarbeiten Sie die API-Antwort, um die generierte Antwort zu erhalten.
API-Aufruf
CometAPI bietet eine vollständig kompatible REST-API für eine nahtlose Migration. Wichtige Details zu API-Dokument:
- Kernparameter:
prompt,max_tokens_to_sample,temperature,stop_sequences - Endpunkt:
https://api.cometapi.com/v1/chat/completions - Modellparameter: qwen3-max-Vorschau
- Authentifizierung:
Bearer YOUR_CometAPI_API_KEY - Content-Type:
application/json.
Ersetzen
CometAPI_API_KEYmit Ihrem Schlüssel; beachten Sie die Basis-URL.
Python (Anfragen) – OpenAI-kompatibel
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
TIPP: - max_input_tokens, max_output_tokensund Model Studio's Kontextcache Funktionen beim Senden sehr großer Kontexte zur Kontrolle von Kosten und Durchsatz.
Siehe auch Qwen3-Coder