

Am 19. und 20. November 2025 veröffentlichte OpenAI zwei verwandte, aber unterschiedliche Upgrades: GPT-5.1-Codex-Max, ein neues agentenbasiertes Codierungsmodell für Codex, das die Codierung mit langem Zeithorizont, die Token-Effizienz und die „Kompaktierung“ zur Unterstützung von Multi-Window-Sitzungen betont; und GPT-5.1 Pro, ein aktualisiertes Pro-Tier ChatGPT-Modell, das auf klarere und leistungsfähigere Antworten bei komplexen, professionellen Aufgaben abgestimmt ist.
Was ist GPT-5.1-Codex-Max und welches Problem versucht es zu lösen?
GPT-5.1-Codex-Max ist ein spezialisiertes Codex-Modell von OpenAI, das für Codierungs-Workflows optimiert ist, die Folgendes erfordern: nachhaltiges, langfristiges Denken und HandelnWo herkömmliche Modelle durch extrem lange Kontexte – beispielsweise Refactorings über mehrere Dateien, komplexe Agentenschleifen oder persistente CI/CD-Aufgaben – an ihre Grenzen stoßen können, ist Codex-Max darauf ausgelegt, … Sitzungsstatus über mehrere Kontextfenster hinweg automatisch komprimieren und verwaltenDadurch kann es auch dann noch reibungslos funktionieren, wenn ein einzelnes Projekt Tausende (oder mehr) von Token umfasst. OpenAI positioniert Codex-Max als nächsten Schritt, um codefähige Agenten für umfangreiche Entwicklungsarbeiten wirklich nützlich zu machen.
Was ist GPT-5.1-Codex-Max und welches Problem versucht es zu lösen?
GPT-5.1-Codex-Max ist ein spezialisiertes Codex-Modell von OpenAI, das für Codierungs-Workflows optimiert ist, die Folgendes erfordern: nachhaltiges, langfristiges Denken und HandelnWo herkömmliche Modelle durch extrem lange Kontexte – beispielsweise Refactorings über mehrere Dateien, komplexe Agentenschleifen oder persistente CI/CD-Aufgaben – an ihre Grenzen stoßen können, ist Codex-Max darauf ausgelegt, … Sitzungsstatus über mehrere Kontextfenster hinweg automatisch komprimieren und verwaltenwodurch es weiterhin kohärent funktionieren kann, da ein einzelnes Projekt viele Tausend (oder mehr) Token umfasst.
OpenAI beschreibt es als „schneller, intelligenter und tokeneffizienter in jeder Phase des Entwicklungszyklus“ und es ist ausdrücklich vorgesehen, GPT-5.1-Codex als Standardmodell in Codex-Oberflächen zu ersetzen.
Funktionsübersicht
- Komprimierung für die Mehrfensterkontinuität: Es entfernt und bewahrt wichtige Kontextinformationen, um über Millionen von Tokens und Stunden hinweg kohärent zu funktionieren. 0
- Verbesserte Token-Effizienz im Vergleich zu GPT-5.1-Codex: Bei einigen Code-Benchmarks können bis zu 30 % weniger Denk-Tokens für einen vergleichbaren Denkaufwand benötigt werden.
- Langfristige Wirkbeständigkeit: Intern wurde beobachtet, dass Agentenschleifen über mehrere Stunden/mehrtägige Laufzeiten aufrechterhalten werden können (OpenAI dokumentierte interne Läufe von >24 Stunden).
- Plattformintegrationen: Ab heute verfügbar in Codex CLI, IDE-Erweiterungen, Cloud und Code-Review-Tools; API-Zugriff folgt in Kürze.
- Unterstützung für Windows-Umgebungen: OpenAI hebt insbesondere hervor, dass Windows zum ersten Mal in Codex-Workflows unterstützt wird, wodurch die Reichweite für Entwickler in der realen Welt erweitert wird.
Wie schneidet es im Vergleich zu Konkurrenzprodukten ab (z. B. GitHub Copilot, andere KI-Systeme für die Codierung)?
GPT-5.1-Codex-Max positioniert sich als autonomerer, langfristiger Kollaborationspartner im Vergleich zu Tools, die Befehle pro Anfrage vervollständigen. Während Copilot und ähnliche Assistenten sich durch ihre Fähigkeit auszeichnen, kurzfristige Aufgaben im Editor zu erledigen, liegen die Stärken von Codex-Max in der Orchestrierung mehrstufiger Aufgaben, der Aufrechterhaltung eines konsistenten Zustands über verschiedene Sitzungen hinweg und der Bewältigung von Workflows, die Planung, Tests und Iterationen erfordern. Daher dürfte in den meisten Teams ein hybrider Ansatz die beste Lösung sein: Codex-Max für komplexe Automatisierungen und kontinuierliche Agentenaufgaben und schlankere Assistenten für die Vervollständigung einzelner Zeilen.
Wie funktioniert GPT-5.1-Codex-Max?
Was versteht man unter „Kompaktierung“ und wie ermöglicht sie Langzeitarbeiten?
Ein zentraler technischer Fortschritt ist Verdichtung—ein interner Mechanismus, der den Sitzungsverlauf reduziert, dabei aber die wichtigsten Kontextinformationen beibehält, damit das Modell weiterhin kohärent arbeiten kann. mehrere Kontextfenster. Konkret bedeutet dies, dass Codex-Sitzungen, die sich ihrem Kontextlimit nähern, komprimiert werden (ältere oder weniger wertvolle Token werden zusammengefasst/beibehalten), sodass der Agent ein neues Fenster erhält und die Iteration so lange fortsetzen kann, bis die Aufgabe abgeschlossen ist. OpenAI berichtet von internen Testläufen, bei denen das Modell über 24 Stunden ununterbrochen an Aufgaben gearbeitet hat.
Adaptives Denken und Token-Effizienz
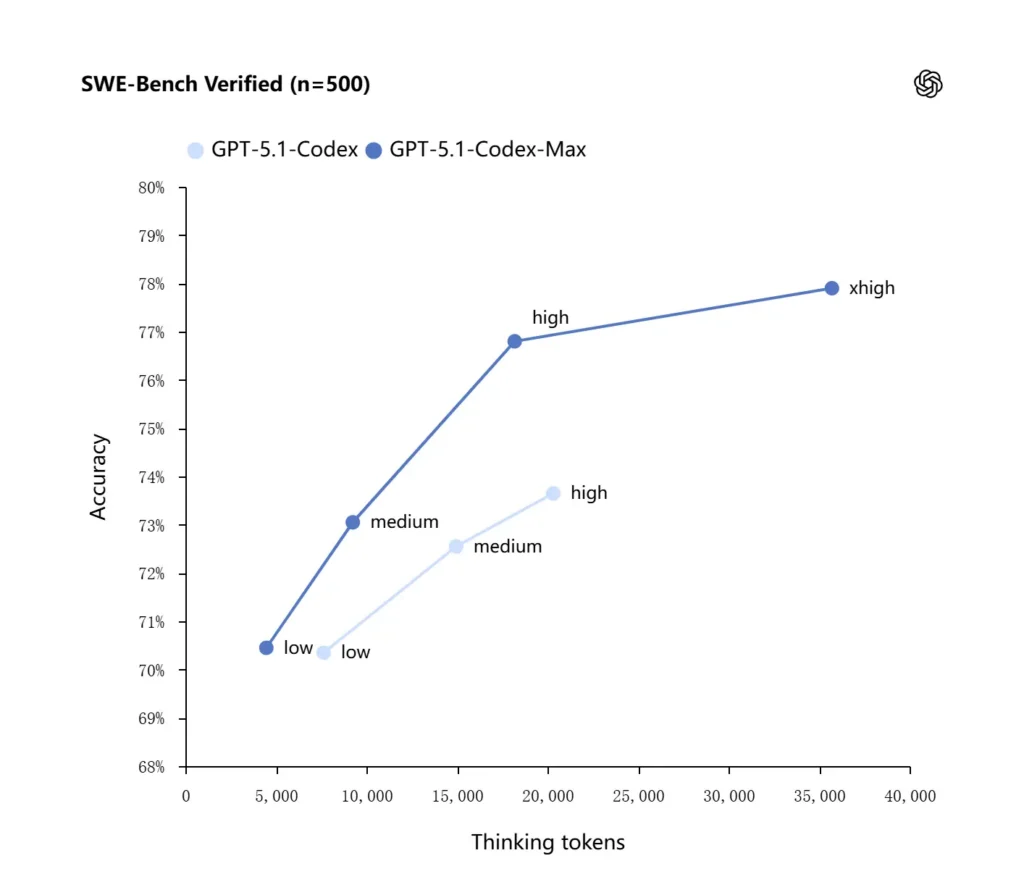
GPT-5.1-Codex-Max verwendet verbesserte Denkstrategien, die es tokeneffizienter machen: In den von OpenAI veröffentlichten internen Benchmarks erzielt das Max-Modell eine ähnliche oder bessere Leistung als GPT-5.1-Codex, benötigt dabei aber deutlich weniger „Denk“-Token – OpenAI gibt etwa 100 % an. 30% weniger Die Denk-Tokens wurden auf SWE-bench verifiziert, wenn sie mit gleichem Denkaufwand ausgeführt wurden. Das Modell führt außerdem einen Modus mit „Extra hohem (xhigh)“ Denkaufwand für nicht latenzkritische Aufgaben ein, der es ermöglicht, mehr interne Denkprozesse durchzuführen, um qualitativ hochwertigere Ergebnisse zu erzielen.
Systemintegrationen und agentenbasierte Werkzeuge
Codex-Max wird in Codex-Workflows (CLI, IDE-Erweiterungen, Cloud und Code-Review-Oberflächen) integriert, um die Interaktion mit gängigen Entwickler-Toolchains zu ermöglichen. Zu den ersten Integrationen gehören die Codex-CLI und IDE-Agenten (VS Code, JetBrains usw.), der API-Zugriff ist in Planung. Ziel ist nicht nur eine intelligentere Code-Synthese, sondern auch eine KI, die mehrstufige Workflows ausführen kann: Dateien öffnen, Tests ausführen, Fehler beheben, refaktorisieren und erneut ausführen.
Wie schneidet GPT-5.1-Codex-Max bei Benchmarks und in realen Anwendungen ab?
Aufgaben zum anhaltenden Denken und zur Bewältigung langfristiger Herausforderungen
Die Auswertungen deuten auf messbare Verbesserungen beim anhaltenden Denken und bei Aufgaben mit langem Zeithorizont hin:
- Interne Evaluierungen von OpenAICodex-Max konnte in internen Tests „mehr als 24 Stunden“ an Aufgaben arbeiten, und die Integration von Codex in die Entwicklerwerkzeuge steigerte die internen Produktivitätskennzahlen der Entwicklungsabteilung (z. B. Nutzung und Durchsatz von Pull Requests). Dies sind interne Angaben von OpenAI und deuten auf Produktivitätssteigerungen auf Aufgabenebene in der Praxis hin.
- **Unabhängige Evaluierungen (METR)**Der unabhängige Bericht von METR maß die beobachteter 50%-Zeithorizont (eine Statistik, die die mittlere Zeit angibt, die das Modell eine längere Aufgabe kohärent bewältigen kann) für GPT-5.1-Codex-Max bei etwa 2 Stunden 40 Minuten (mit einem breiten Konfidenzintervall) gegenüber 2 Stunden und 17 Minuten bei vergleichbaren Messungen mit GPT-5 – eine signifikante und dem Trend entsprechende Verbesserung der anhaltenden Kohärenz. Die Methodik und das Konfidenzintervall von METR betonen die Variabilität, aber das Ergebnis stützt die Annahme, dass Codex-Max die praktische Langzeitleistung verbessert.
Code-Benchmarks
OpenAI berichtet von verbesserten Ergebnissen bei Evaluierungen fortschrittlicher Programmiersprachen, insbesondere bei SWE-bench Verified, wo GPT-5.1-Codex-Max GPT-5.1-Codex mit höherer Token-Effizienz übertrifft. Das Unternehmen hebt hervor, dass das Max-Modell bei gleichem „mittlerem“ Denkaufwand bessere Ergebnisse liefert und dabei etwa 30 % weniger Denk-Tokens benötigt. Für Nutzer, die längere interne Denkprozesse zulassen, kann der xhigh-Modus die Antworten weiter verbessern, allerdings auf Kosten der Latenz.
| GPT‑5.1-Codex (hoch) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench-verifiziert (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminalbank 2.0 | 52.8% | 58.1% |
Wie schneidet GPT-5.1-Codex-Max im Vergleich zu GPT-5.1-Codex ab?
Leistungs- und Zweckunterschiede
- Umfang: GPT-5.1-Codex war eine leistungsstarke Codierungsvariante der GPT-5.1-Familie; Codex-Max ist explizit ein agentenorientierter Nachfolger mit langfristigem Zeithorizont, der als empfohlene Standardlösung für Codex- und Codex-ähnliche Umgebungen gedacht ist.
- Token-Effizienz: Codex-Max weist sowohl im SWE-Benchmark als auch in der internen Anwendung deutliche Effizienzgewinne bei den Token auf (OpenAI behauptet, dass ~30 % weniger Denk-Token benötigt werden).
- Kontextverwaltung: Codex-Max bietet Komprimierung und native Mehrfensterverwaltung, um Aufgaben zu bewältigen, die ein einzelnes Kontextfenster überschreiten; Codex bot diese Fähigkeit in diesem Umfang nicht nativ.
- Werkzeugbereitschaft: Codex-Max wird als Standard-Codex-Modell in der CLI, der IDE und den Code-Review-Oberflächen ausgeliefert und signalisiert damit eine Migration für die Arbeitsabläufe von Entwicklern in der Produktion.
Wann welches Modell verwenden?
- Verwenden Sie GPT-5.1-Codex für interaktive Codierungsunterstützung, schnelle Bearbeitungen, kleinere Refaktorierungen und Anwendungsfälle mit geringer Latenz, bei denen der gesamte relevante Kontext problemlos in ein einziges Fenster passt.
- Verwenden Sie GPT-5.1-Codex-Max für Refaktorierungen mit mehreren Dateien, automatisierte agentenbasierte Aufgaben, die viele Iterationszyklen erfordern, CI/CD-ähnliche Arbeitsabläufe oder wenn das Modell eine Projektperspektive über viele Interaktionen hinweg beibehalten muss.
Praktische Vorlagen und Beispiele für optimale Ergebnisse?
Promptmuster, die gut funktionieren
- Ziele und Einschränkungen sollten klar benannt werden: „X refaktorisieren, die öffentliche API beibehalten, die Funktionsnamen beibehalten und sicherstellen, dass die Tests A, B und C erfolgreich sind.“
- Minimalen reproduzierbaren Kontext bereitstellen: Bitte verlinken Sie auf den fehlgeschlagenen Test, fügen Sie Stacktraces und relevante Dateiausschnitte hinzu, anstatt ganze Repositories zu exportieren. Codex-Max komprimiert den Verlauf bei Bedarf.
- Verwenden Sie schrittweise Anweisungen für komplexe Aufgaben: Große Aufgaben werden in eine Folge von Teilaufgaben zerlegt, die Codex-Max dann iterativ durchläuft (z. B. „1) Tests ausführen 2) die drei fehlgeschlagenen Tests beheben 3) Linter ausführen 4) Änderungen zusammenfassen“).
- Bitten Sie um Erklärungen und Unterschiede: Bitte fordern Sie sowohl den Patch als auch eine kurze Begründung an, damit menschliche Prüfer Sicherheit und Absicht schnell beurteilen können.
Beispielvorlagen für Eingabeaufforderungen
Refactoring-Aufgabe
„Refaktorieren Sie die
payment/Modul zur Extraktion der Zahlungsabwicklung inpayment/processor.pyHalten Sie die Signaturen öffentlicher Funktionen für bestehende Aufrufer stabil. Erstellen Sie Unit-Tests fürprocess_payment()Diese Tests decken Erfolg, Netzwerkfehler und ungültige Karten ab. Führen Sie die Testsuite aus und geben Sie fehlgeschlagene Tests sowie einen Patch im Unified-Diff-Format zurück.“
Bugfix + Test
„Ein Test
tests/test_user_auth.py::test_token_refreshFehler mit Traceback . Untersuchen Sie die Ursache, schlagen Sie eine Lösung mit minimalen Änderungen vor und fügen Sie einen Unit-Test hinzu, um Regressionen zu vermeiden. Wenden Sie den Patch an und führen Sie die Tests aus.
Iterative PR-Generierung
„Funktion X implementieren: Endpunkt hinzufügen“
POST /api/exportDer Stream liefert Exportergebnisse und ist authentifiziert. Erstellen Sie den Endpunkt, fügen Sie Dokumentationen hinzu, erstellen Sie Tests und öffnen Sie einen Pull Request mit einer Zusammenfassung und einer Checkliste der manuellen Schritte.“
Bei den meisten dieser Aufgaben beginnen Sie mit mittlere Aufwand; wechseln zu xhoch Wenn das Modell tiefgreifende Schlussfolgerungen über viele Dateien und mehrere Testiterationen hinweg ziehen muss.
Wie greift man auf GPT-5.1-Codex-Max zu?
Wo es heute erhältlich ist
OpenAI hat GPT-5.1-Codex-Max integriert in Codex-Werkzeuge Aktuell nutzen die Codex-CLI, IDE-Erweiterungen, Cloud-Dienste und Code-Review-Workflows standardmäßig Codex-Max (alternativ Codex-Mini). Die API-Verfügbarkeit wird vorbereitet; GitHub Copilot bietet öffentliche Vorschauen mit Modellen der GPT-5.1- und Codex-Serie.
Entwickler können auf GPT-5.1-Codex-Max zugreifen und GPT-5.1-Codex-API über CometAPI. Erkunden Sie zunächst die Modellfunktionen vonCometAPI in England, Spielplatz Detaillierte Anweisungen finden Sie im API-Handbuch. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. MitetAPI bieten einen Preis weit unter dem offiziellen Preis an, um Ihnen bei der Integration zu helfen.
Bereit loszulegen? → Melden Sie sich noch heute für CometAPI an !
Wenn Sie weitere Tipps, Anleitungen und Neuigkeiten zu KI erfahren möchten, folgen Sie uns auf VK, X kombiniert mit einem nachhaltigen Materialprofil. Discord!
Schnellstart (praktische Schritt-für-Schritt-Anleitung)
- Stellen Sie sicher, dass Sie Zugriff haben: Bitte prüfen Sie, ob Ihr ChatGPT/Codex-Produktplan (Plus, Pro, Business, Edu, Enterprise) oder Ihr Entwickler-API-Plan die Modelle der GPT-5.1/Codex-Familie unterstützt.
- Installieren Sie die Codex CLI- oder IDE-Erweiterung: Um Codeaufgaben lokal auszuführen, installieren Sie die Codex-CLI oder die Codex-IDE-Erweiterung für VS Code, JetBrains oder Xcode. In unterstützten Umgebungen wird standardmäßig GPT-5.1-Codex-Max verwendet.
- Argumentationsaufwand wählen: beginnen mit mittlere Für die meisten Aufgaben ist der Aufwand ausreichend. Für tiefgehendes Debugging, komplexe Refaktorierungen oder wenn das Modell mehr Rechenleistung erbringen soll und die Antwortlatenz keine Rolle spielt, wechseln Sie zu Highs or xhoch Modi. Für schnelle, kleinere Reparaturen. niedrig ist vernünftig.
- Repository-Kontext bereitstellen: Geben Sie dem Modell einen klaren Startpunkt – eine Repository-URL oder einen Satz von Dateien und eine kurze Anweisung (z. B. „Refaktorieren Sie das Zahlungsmodul, um asynchrone Ein-/Ausgabe zu verwenden, fügen Sie Unit-Tests hinzu und behalten Sie die Funktionsverträge bei“). Codex-Max komprimiert den Verlauf, sobald er sich den Kontextgrenzen nähert, und setzt die Arbeit fort.
- Mit Tests iterieren: Nachdem das Modell Patches generiert hat, werden Testreihen ausgeführt und Fehler im Rahmen der laufenden Sitzung zurückgemeldet. Komprimierung und die Unterstützung mehrerer Fenster ermöglichen es Codex-Max, wichtige Kontextinformationen fehlgeschlagener Tests beizubehalten und diese zu wiederholen.
Fazit:
GPT-5.1-Codex-Max stellt einen bedeutenden Schritt hin zu agentenbasierten Programmierassistenten dar, die komplexe, langwierige Entwicklungsaufgaben effizienter und mit verbesserter Argumentationsfähigkeit bewältigen können. Die technischen Fortschritte (Kompaktierung, verschiedene Modelle zur Berechnung des Denkaufwands, Training in der Windows-Umgebung) machen es besonders geeignet für moderne Entwicklungsorganisationen – vorausgesetzt, die Teams kombinieren das Modell mit konservativen Betriebskontrollen, klaren Richtlinien für die menschliche Interaktion und einem robusten Monitoring. Bei sorgfältiger Implementierung birgt Codex-Max das Potenzial, die Art und Weise, wie Software entwickelt, getestet und gewartet wird, grundlegend zu verändern – und repetitive Routinearbeiten in eine wertvolle Zusammenarbeit zwischen Mensch und Modell zu verwandeln.