

Am 19.–20. November 2025 veröffentlichte OpenAI zwei verwandte, aber unterschiedliche Upgrades: GPT-5.1-Codex-Max, ein neues agentisches Coding-Modell für Codex, das auf langfristiges Programmieren, Token-Effizienz und „Kompaktierung“ ausgelegt ist, um Multi-Window-Sessions aufrechtzuerhalten; sowie GPT-5.1 Pro, ein aktualisiertes ChatGPT-Modell der Pro-Stufe, abgestimmt auf klarere, leistungsfähigere Antworten bei komplexer, professioneller Arbeit.
Was ist GPT-5.1-Codex-Max und welches Problem soll es lösen?
GPT-5.1-Codex-Max ist ein spezialisiertes Codex-Modell von OpenAI, abgestimmt auf Coding‑Workflows, die eine nachhaltige, langfristige Argumentation und Ausführung erfordern. Während gewöhnliche Modelle durch extrem lange Kontexte ins Straucheln geraten können — etwa bei Refactorings über mehrere Dateien, komplexen Agent‑Schleifen oder dauerhaften CI/CD‑Aufgaben — ist Codex‑Max darauf ausgelegt, den Sitzungszustand über mehrere Kontextfenster hinweg automatisch zu kompaktieren und zu verwalten, sodass es kohärent weiterarbeiten kann, wenn ein Projekt viele Tausende (oder mehr) Tokens umfasst. OpenAI positioniert Codex‑Max als den nächsten Schritt hin zu wirklich nützlichen, codefähigen Agenten für längerfristige Entwicklungsarbeit.
Was ist GPT-5.1-Codex-Max und welches Problem soll es lösen?
GPT-5.1-Codex-Max ist ein spezialisiertes Codex-Modell von OpenAI, abgestimmt auf Coding‑Workflows, die eine nachhaltige, langfristige Argumentation und Ausführung erfordern. Während gewöhnliche Modelle durch extrem lange Kontexte ins Straucheln geraten können — etwa bei Refactorings über mehrere Dateien, komplexen Agent‑Schleifen oder dauerhaften CI/CD‑Aufgaben — ist Codex‑Max darauf ausgelegt, den Sitzungszustand über mehrere Kontextfenster hinweg automatisch zu kompaktieren und zu verwalten, sodass es kohärent weiterarbeiten kann, wenn ein Projekt viele Tausende (oder mehr) Tokens umfasst.
OpenAI beschreibt es als „schneller, intelligenter und in jeder Phase des Entwicklungszyklus token‑effizienter“ und beabsichtigt ausdrücklich, GPT‑5.1‑Codex als Standardmodell in Codex‑Oberflächen zu ersetzen.
Funktionsüberblick
- Kompaktierung für Multi-Window-Kontinuität: schneidet und bewahrt kritischen Kontext, um über Millionen von Tokens und Stunden kohärent zu arbeiten. 0
- Verbesserte Token-Effizienz gegenüber GPT‑5.1‑Codex: bis zu ~30% weniger Denk‑Tokens für vergleichbaren Reasoning‑Aufwand in einigen Code‑Benchmarks.
- Langfristige agentische Belastbarkeit: intern beobachtet, dass mehrstündige/mehrtägige Agent‑Schleifen durchgehalten werden (OpenAI dokumentierte interne Läufe >24 Stunden).
- Plattform-Integrationen: ab heute in Codex CLI, IDE‑Erweiterungen, Cloud und Code‑Review‑Tools verfügbar; API‑Zugriff folgt.
- Unterstützung der Windows-Umgebung: OpenAI weist ausdrücklich darauf hin, dass Windows erstmals in Codex‑Workflows unterstützt wird und so die reale Entwicklerreichweite ausgebaut wird.
Wie schneidet es im Vergleich zu Konkurrenzprodukten ab (z. B. GitHub Copilot, andere Coding-AIs)?
GPT‑5.1‑Codex‑Max wird als autonomerer, langfristiger Kollaborateur positioniert, verglichen mit Tools für Vervollständigungen pro Anfrage. Während Copilot und ähnliche Assistenten bei kurzfristigen Vervollständigungen im Editor glänzen, liegen die Stärken von Codex‑Max im Orchestrieren mehrstufiger Aufgaben, im Aufrechterhalten eines kohärenten Zustands über Sessions hinweg und in der Bewältigung von Workflows, die Planung, Tests und Iteration erfordern. Dennoch ist in den meisten Teams der hybride Ansatz am besten: Codex‑Max für komplexe Automatisierungen und nachhaltige Agent‑Aufgaben nutzen und leichtere Assistenten für Vervollständigungen auf Zeilenebene.
Wie funktioniert GPT-5.1-Codex-Max?
Was ist „Kompaktierung“ und wie ermöglicht sie lang laufende Arbeit?
Eine zentrale technische Neuerung ist die Kompaktierung — ein interner Mechanismus, der den Sitzungsverlauf zurückschneidet und gleichzeitig die wesentlichen Teile des Kontexts bewahrt, damit das Modell über mehrere Kontextfenster hinweg kohärent weiterarbeiten kann. Praktisch bedeutet das: Codex‑Sessions, die sich ihrem Kontextlimit nähern, werden kompaktiert (ältere oder weniger wertvolle Tokens werden zusammengefasst/gesichert), sodass der Agent ein frisches Fenster erhält und wiederholt weiter iterieren kann, bis die Aufgabe abgeschlossen ist. OpenAI berichtet von internen Läufen, in denen das Modell Aufgaben über mehr als 24 Stunden hinweg kontinuierlich bearbeitete.
Adaptive Reasoning und Token-Effizienz
GPT‑5.1‑Codex‑Max nutzt verbesserte Reasoning‑Strategien, die es token‑effizienter machen: In von OpenAI berichteten internen Benchmarks erreicht das Max‑Modell ähnliche oder bessere Leistung als GPT‑5.1‑Codex und verwendet dabei deutlich weniger „Denk“-Tokens — OpenAI nennt etwa 30% weniger Denk‑Tokens auf SWE‑bench Verified bei gleichem Reasoning‑Aufwand. Das Modell führt außerdem einen Modus „Extra High (xhigh)“ für nicht latenzkritische Aufgaben ein, der mehr internen Reasoning‑Aufwand erlaubt, um qualitativ höherwertige Ausgaben zu erzielen.
Systemintegrationen und agentische Tools
Codex‑Max wird innerhalb von Codex‑Workflows (CLI, IDE‑Erweiterungen, Cloud und Code‑Review‑Oberflächen) ausgeliefert, sodass es mit realen Entwickler‑Toolchains interagieren kann. Frühe Integrationen umfassen die Codex CLI und IDE‑Agenten (VS Code, JetBrains usw.); API‑Zugriff ist geplant. Ziel ist nicht nur intelligentere Codesynthese, sondern eine KI, die mehrstufige Workflows ausführen kann: Dateien öffnen, Tests ausführen, Fehler beheben, refaktorisieren und erneut ausführen.
Wie schlägt sich GPT-5.1-Codex-Max in Benchmarks und in der Praxis?
Nachhaltiges Reasoning und langfristige Aufgaben
Bewertungen zeigen messbare Verbesserungen bei nachhaltigem Reasoning und langfristigen Aufgaben:
- Interne Bewertungen von OpenAI: Codex‑Max kann in internen Experimenten „mehr als 24 Stunden“ an Aufgaben arbeiten, und die Integration von Codex mit Entwickler‑Tools erhöhte interne Engineering‑Produktivitätskennzahlen (z. B. Nutzung und Pull‑Request‑Durchsatz). Dies sind interne Angaben von OpenAI und deuten auf aufgabenbezogene Verbesserungen in der realen Produktivität hin.
- Unabhängige Bewertungen (METR): Der unabhängige Bericht von METR maß den beobachteten 50%-Zeithorizont (eine Statistik, die die mediane Zeit repräsentiert, über die das Modell eine lange Aufgabe kohärent aufrechterhalten kann) für GPT‑5.1‑Codex‑Max bei etwa 2 Stunden 40 Minuten (mit breitem Konfidenzintervall), gegenüber 2 Stunden 17 Minuten bei GPT‑5 in vergleichbaren Messungen — eine bedeutende, trendkonforme Verbesserung der nachhaltigen Kohärenz. METRs Methodik und CI betonen Variabilität, aber das Ergebnis stützt die Aussage, dass Codex‑Max die praktische Langhorizont‑Performance verbessert.
Code-Benchmarks
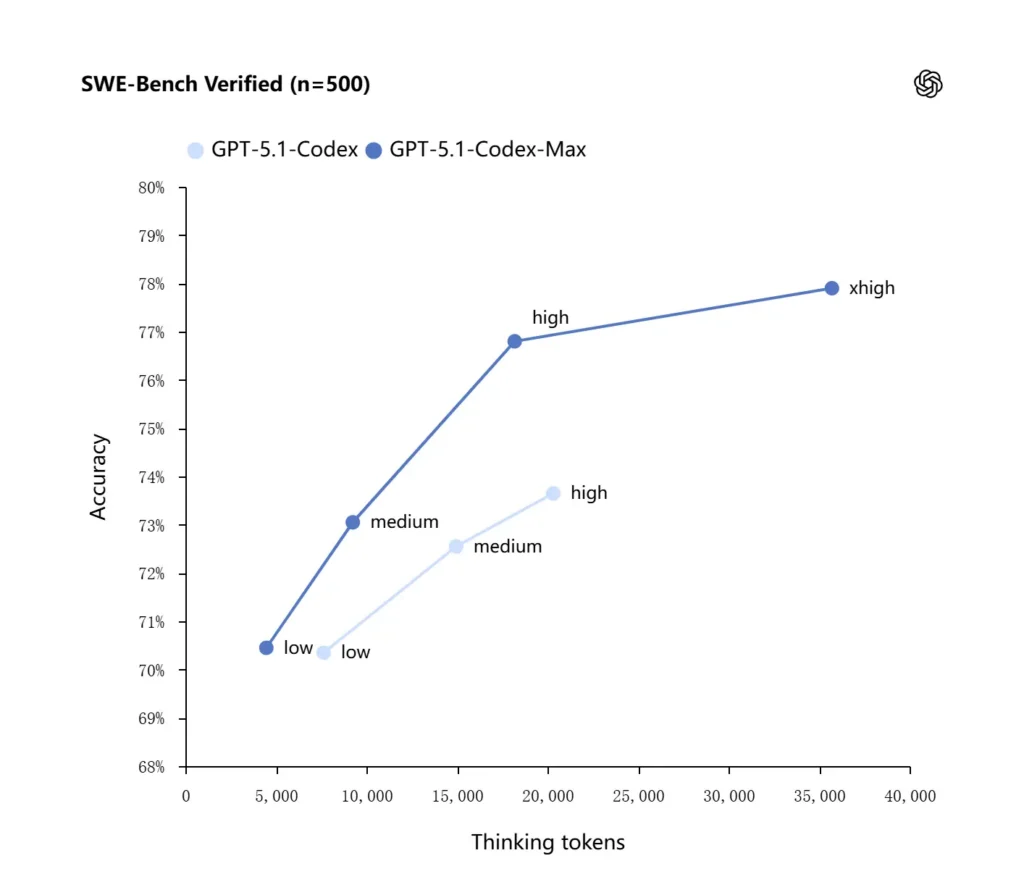
OpenAI berichtet über verbesserte Ergebnisse bei führenden Coding‑Evaluierungen, insbesondere SWE‑bench Verified, wo GPT‑5.1‑Codex‑Max GPT‑5.1‑Codex mit besserer Token‑Effizienz übertrifft. Das Unternehmen hebt hervor, dass das Max‑Modell bei gleichem Reasoning‑Aufwand „medium“ bessere Resultate liefert und dabei rund 30% weniger Denk‑Tokens verwendet; für Nutzer, die längeres internes Reasoning zulassen, kann der xhigh‑Modus die Antworten weiter verbessern — auf Kosten der Latenz.
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
Wie unterscheidet sich GPT-5.1-Codex-Max von GPT-5.1-Codex?
Unterschiede in Leistung und Zweck
- Umfang: GPT‑5.1‑Codex war eine leistungsstarke Coding‑Variante der GPT‑5.1‑Familie; Codex‑Max ist explizit ein agentischer, langhorizontiger Nachfolger, der als empfohlener Standard für Codex‑ und Codex‑ähnliche Umgebungen gedacht ist.
- Token‑Effizienz: Codex‑Max zeigt spürbare Zugewinne bei der Token‑Effizienz (OpenAIs Angabe von ~30% weniger Denk‑Tokens) auf SWE‑bench und in der internen Nutzung.
- Kontextverwaltung: Codex‑Max führt Kompaktierung und native Multi‑Window‑Handhabung ein, um Aufgaben zu unterstützen, die ein einzelnes Kontextfenster überschreiten; Codex bot diese Fähigkeit nicht in gleichem Umfang nativ.
- Tooling‑Einsatzreife: Codex‑Max wird als Standard‑Codex‑Modell über CLI, IDE und Code‑Review‑Oberflächen ausgeliefert und signalisiert damit eine Migration für produktive Entwickler‑Workflows.
Wann welches Modell verwenden?
- Verwenden Sie GPT‑5.1‑Codex für interaktive Coding‑Assistenz, schnelle Edits, kleine Refactorings und latenzarme Anwendungsfälle, bei denen der gesamte relevante Kontext leicht in ein einzelnes Fenster passt.
- Verwenden Sie GPT‑5.1‑Codex‑Max für Refactorings über mehrere Dateien, automatisierte agentische Aufgaben, die viele Iterationszyklen erfordern, CI/CD‑ähnliche Workflows oder wenn das Modell eine projektweite Perspektive über viele Interaktionen hinweg halten soll.
Praktische Prompt-Muster und Beispiele für beste Ergebnisse?
Gut funktionierende Prompt-Muster
- Seien Sie explizit zu Zielen und Einschränkungen: „Refaktoriere X, erhalte die öffentliche API, behalte Funktionsnamen bei und stelle sicher, dass die Tests A, B, C bestehen.“
- Geben Sie minimal reproduzierbaren Kontext: verlinken Sie den fehlgeschlagenen Test, fügen Sie Stacktraces und relevante Dateiausschnitte bei, statt ganze Repositories zu dumpen. Codex‑Max wird die Historie bei Bedarf kompaktieren.
- Nutzen Sie schrittweise Anweisungen für komplexe Aufgaben: zerlegen Sie große Jobs in eine Abfolge von Teilaufgaben und lassen Sie Codex‑Max sie iterieren (z. B. „1) Tests ausführen 2) die 3 häufigsten Fehler beheben 3) Linter ausführen 4) Änderungen zusammenfassen“).
- Bitten Sie um Erklärungen und Diffs: verlangen Sie sowohl den Patch als auch eine kurze Begründung, damit menschliche Reviewer Sicherheit und Intention schnell einschätzen können.
Beispiel-Prompt-Vorlagen
Refactoring-Aufgabe
„Refactor the
payment/module to extract payment processing intopayment/processor.py. Keep public function signatures stable for existing callers. Create unit tests forprocess_payment()that cover success, network failure, and invalid card. Run the test suite and return failing tests and a patch in unified diff format.“
Bugfix + Test
„A test
tests/test_user_auth.py::test_token_refreshfails with traceback . Investigate root cause, propose a fix with minimal changes, and add a unit test to prevent regression. Apply patch and run tests.“
Iterative PR-Erstellung
„Implement feature X: add endpoint
POST /api/exportwhich streams export results and is authenticated. Create the endpoint, add docs, create tests, and open a PR with summary and checklist of manual items.“
Für die meisten dieser Fälle beginnen Sie mit medium Aufwand; wechseln Sie zu xhigh, wenn das Modell tiefes Reasoning über viele Dateien und mehrere Test‑Iterationen leisten soll.
Wie greifen Sie auf GPT-5.1-Codex-Max zu
Wo es heute verfügbar ist
OpenAI hat GPT‑5.1‑Codex‑Max heute in Codex‑Tools integriert: Die Codex CLI, IDE‑Erweiterungen, Cloud und Code‑Review‑Flows verwenden standardmäßig Codex‑Max (Sie können Codex‑Mini auswählen). API‑Verfügbarkeit wird vorbereitet; GitHub Copilot hat öffentliche Previews, die GPT‑5.1‑ und Codex‑Serienmodelle einschließen.
Entwickler können auf GPT‑5.1‑Codex‑Max und die GPT-5.1-Codex API über CometAPI zugreifen. Beginnen Sie, indem Sie die Modellfähigkeiten von CometAPI im Playground erkunden und das API‑Handbuch für detaillierte Anweisungen konsultieren. Bevor Sie zugreifen, stellen Sie sicher, dass Sie sich bei CometAPI angemeldet und den API‑Schlüssel erhalten haben. CometAPI bietet einen Preis, der deutlich unter dem offiziellen Preis liegt, um Ihnen die Integration zu erleichtern.
Bereit loszulegen? → Melden Sie sich noch heute bei CometAPI an!
Wenn Sie mehr Tipps, Anleitungen und Neuigkeiten zu KI erfahren möchten, folgen Sie uns auf VK, X und Discord!
Quick Start (praktische Schritt-für-Schritt-Anleitung)
- Stellen Sie sicher, dass Sie Zugriff haben: Bestätigen Sie, dass Ihr ChatGPT/Codex‑Produktplan (Plus, Pro, Business, Edu, Enterprise) oder Ihr Entwickler‑API‑Plan die GPT‑5.1/Codex‑Familienmodelle unterstützt.
- Codex CLI oder IDE‑Erweiterung installieren: Wenn Sie Code‑Aufgaben lokal ausführen möchten, installieren Sie die Codex CLI oder die Codex‑IDE‑Erweiterung für VS Code / JetBrains / Xcode, sofern zutreffend. Die Tools verwenden in unterstützten Setups standardmäßig GPT‑5.1‑Codex‑Max.
- Reasoning‑Aufwand wählen: Beginnen Sie für die meisten Aufgaben mit medium Aufwand. Für tiefes Debugging, komplexe Refactorings oder wenn das Modell länger „nachdenken“ soll und Ihnen die Antwortlatenz egal ist, wechseln Sie zu high oder xhigh. Für kleine schnelle Fixes ist low angemessen.
- Repository‑Kontext bereitstellen: Geben Sie dem Modell einen klaren Ausgangspunkt — eine Repo‑URL oder einen Satz von Dateien und eine kurze Anweisung (z. B. „refactor the payment module to use async I/O and add unit tests, keep function-level contracts“). Codex‑Max wird die Historie beim Erreichen von Kontextgrenzen kompaktieren und den Job fortsetzen.
- Mit Tests iterieren: Führen Sie nach der Erstellung von Patches durch das Modell Test‑Suites aus und geben Sie Fehlschläge als Teil der laufenden Session zurück. Kompaktierung und Multi‑Window‑Kontinuität ermöglichen es Codex‑Max, wichtigen Kontext zu fehlgeschlagenen Tests zu behalten und zu iterieren.
Fazit:
GPT‑5.1‑Codex‑Max stellt einen wesentlichen Schritt hin zu agentischen Coding‑Assistenten dar, die komplexe, lang laufende Engineering‑Aufgaben mit verbesserter Effizienz und Reasoning durchhalten können. Die technischen Fortschritte (Kompaktierung, Reasoning‑Aufwandsmodi, Windows‑Umgebungs‑Training) machen es besonders geeignet für moderne Engineering‑Organisationen — vorausgesetzt, Teams kombinieren das Modell mit konservativen Betriebs‑Controls, klaren Human‑in‑the‑Loop‑Richtlinien und robuster Überwachung. Für Teams, die es umsichtig einführen, hat Codex‑Max das Potenzial, die Art und Weise zu verändern, wie Software entworfen, getestet und gewartet wird — und repetitive Fleißarbeit in eine höherwertige Zusammenarbeit zwischen Menschen und Modellen zu verwandeln.