

Gemini Embedding 2 ist Googles erstes nativ multimodales Embedding-Modell, das Text, Bilder, Audio, Video und PDFs in einen einzigen 3,072-dimensionalen semantischen Vektorraum abbildet (mit konfigurierbaren Ausgabegrößen). Es führt Matryoshka Representation Learning ein, um verschachtelte/abgeschnittene Embeddings bereitzustellen, eine verbesserte mehrsprachige Leistung (100+ Sprachen) zu erzielen und optimierte Steuerungen für aufgabenspezifische Embeddings zu bieten (z. B. task:search, task:code).
Was ist Gemini Embedding 2?
Gemini Embedding 2 ist ein einheitliches Embedding-Modell von Google, das mehrere Eingabemodalitäten — Text, Bilder, Audio, Video und Dokumente — in einen einzigen semantischen Vektorraum abbildet. Jedes Embedding ist (standardmäßig) ein 3,072-dimensionaler Gleitkomma-Vektor, der die semantische Bedeutung der Eingabe repräsentiert, sodass semantisch ähnliche Elemente (unabhängig von der Modalität) im Vektorraum nahe beieinander liegen. Die wichtigsten Fähigkeiten sind:
- Breite Sprach- und Formatabdeckung: ein einzelnes Modell, das Text, Bilder, Audio, Video und Dokumente akzeptiert und in einem semantischen Vektorraum platziert. Laut Dokumentation erfasst Gemini Embedding 2 die semantische Intention in 100+ Sprachen und akzeptiert gängige Dateiformate (PNG/JPEG, MP4/MOV, MP3/WAV, PDF) mit konkreten Limits pro Anfrage (z. B. bis zu einer Handvoll Bilder oder einige Dutzend Sekunden Audio/Video pro Anfrage — siehe unten „How to use“).
- Echte Multimodalität: ein einzelnes Modell, das Text, Bilder, Audio, Video und Dokumente akzeptiert und in einem semantischen Vektorraum platziert, sodass Sie über Modalitäten hinweg vergleichen oder abrufen können (z. B. Text → Bild, Audio → Text).
- Große Standarddimensionalität mit flexibler Trunkierung: Das Modell gibt standardmäßig 3072-dimensionale Vektoren aus, verwendet jedoch Matryoshka Representation Learning (MRL), um die wichtigsten semantischen Inhalte in den ersten Dimensionen zu konzentrieren. So können Sie auf 1536, 768 (oder weniger) kürzen — mit nur moderaten Einbußen bei der Retrieval-Qualität. Das reduziert die Trade-offs bei Speicher- und Rechenkosten.
Warum das wichtig ist. Historisch waren Embeddings meist nur für Text oder erforderten separate Encoder pro Modalität mit komplexen Cross-Modal-Alignment-Layern. Gemini Embedding 2 beseitigt diese Hürde durch native Unterstützung mehrerer Formate — so kann eine Textanfrage ein Bild oder einen kurzen Clip per semantischer Ähnlichkeit abrufen, ohne Zwischen-Transkription oder manuelles Mapping. Das vereinfacht RAG (Retrieval-Augmented Generation), semantische Suche und multimodale Retrieval-Pipelines.
Wichtige Funktionen & Fähigkeiten (Neuheiten)
1. Echte native Multimodalität (ein Embedding-Raum)
Ein einzelnes Modell, das Text, Bilder, Audio, Video und Dokumente akzeptiert und in einem semantischen Vektorraum platziert. Gemini Embedding 2 ordnet Text, Bilder, Audio, Video und Dokumente demselben Embedding-Raum zu, sodass Cross-Modal-Retrieval (Text→Bild, Audio→Text) direkt ohne Cross-Model-Ausrichtung funktioniert. Das reduziert die Komplexität der Pipeline und vereinfacht RAG-Stacks (Retrieval-Augmented Generation).
2. Standardmäßig 3,072-dimensionale Vektoren mit anpassbarer Ausgabe
Gemini Embedding 2 gibt standardmäßig 3072-dimensionale Vektoren aus, verwendet jedoch Matryoshka Representation Learning (MRL), um die wichtigsten semantischen Inhalte in den ersten Dimensionen zu konzentrieren. So können Sie auf 1536, 768 (oder weniger) kürzen — mit nur moderaten Einbußen bei der Retrieval-Qualität. Das reduziert die Trade-offs bei Speicher- und Rechenkosten.
3. Matryoshka Representation Learning (MRL)
MRL erzeugt „verschachtelte“ Embeddings — wie russische Matrjoschka-Puppen —, sodass niedrigdimensionale Abschnitte höherstufige Semantik bewahren. Dadurch können Systeme einen Betriebspunkt (Speicher-/Genauigkeits-Trade-off) wählen, ohne mehrere separate Embedding-Modelle zu pflegen. Frühe Blog-Analysen und die Dokumentation beschreiben diese Technik als zentrale Innovation für Flexibilität.
4. Task-Hinweise / angepasste Embedding-Ziele
Die API akzeptiert task-Hinweise (z. B. task:search, task:code retrieval, task:semantic-similarity), damit das Modell die Embedding-Geometrie für bestimmte Downstream-Beziehungen optimieren kann — ähnlich der Task-Konditionierung früherer Embedding-Systeme, jedoch auf multimodale Eingaben erweitert.
5. Sprach- und Modalitätsbreite
Gemini Embedding 2 erfasst laut Dokumentation die semantische Intention in 100+ Sprachen und akzeptiert gängige Dateiformate (PNG/JPEGs, MP4/MOV, MP3/WAV, PDF) mit konkreten Limits pro Anfrage (z. B. bis zu einer Handvoll Bilder oder einige Dutzend Sekunden Audio/Video pro Anfrage — siehe unten „How to use“).
Leistungs-Benchmarks
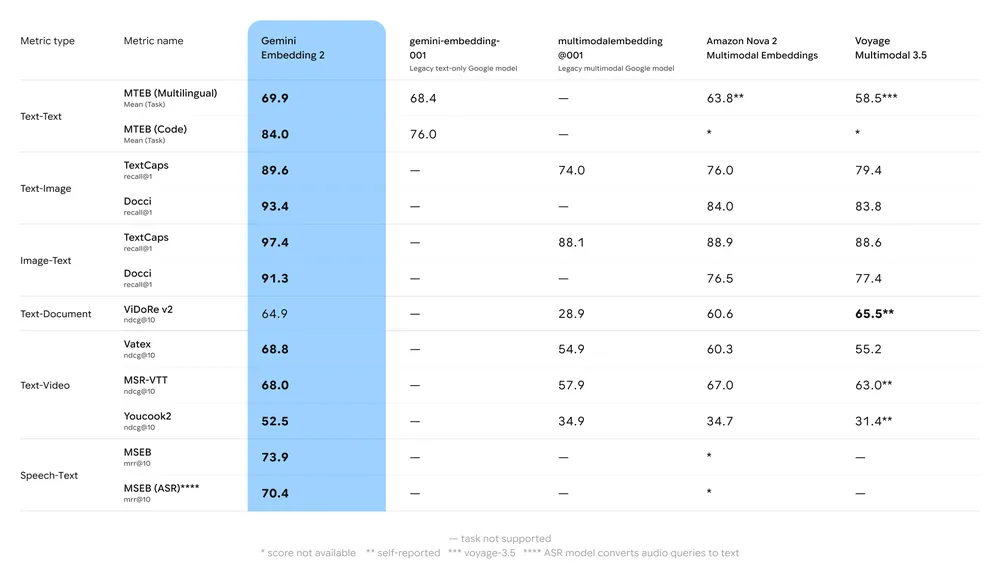
Wichtigste Benchmark-Zusammenfassung:
- MTEB (Massive Text Embedding Benchmark): Gemeldete starke Platzierung auf mehrsprachigen MTEB-Leaderboards für englische und mehrsprachige Aufgaben; Analysen zeigen einen spürbaren Zuwachs gegenüber früheren Gemini-Embedding-Modellen und vielen proprietären Alternativen.
- Multimodales Retrieval: Übertrifft oder erreicht führende Single-Modal-Embeddings bei Cross-Modal-Ähnlichkeit (z. B. Text→Bild-Retrieval) dank nativer multimodaler Trainingsdaten.
- Latenz & Durchsatz: Cloud-gehostete Embedding-Generierung, jedoch könnten latenzkritische Anwendungsfälle verkürzte Vektoren oder alternative leichtgewichtige Embedding-Modelle für Edge-Bedarf bevorzugen.
Gemini Embedding 2 vs gemini-embedding-001 und text-embedding-3-large
| Attribut | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Veröffentlichung/Verfügbarkeit | 10. März 2026 — Public Preview (Gemini API / Vertex AI). | Früheres Gemini-Embedding (hauptsächlich Text) — GA früher. | Angekündigt Jan 2024 (Text-only GA). |
| Unterstützte Modalitäten | Text, Bilder, Audio, Video, Dokumente (PDF) — einheitlicher Vektorraum. | Text (primär). | Nur Text (hochwertig mehrsprachig). |
| Standard-Embedding-Dim. | 3072 (MRL / Trunkierung empfohlen: 1536, 768). | 3072 (für large) — nur Text. | 3072 (text-embedding-3-large). |
| Gemeldetes MTEB (Beispiel) | Hohe 60er im MTEB; zeigt 68.17 bei 1536 in der Anbieter-Tabelle (siehe Doku). | gemini-embedding-001 gemeldet ~68.32 Mittelwert in einigen Leaderboards. | ~64.6 (MTEB-Durchschnitt, von OpenAI für text-embedding-3-large gemeldet). |
| Native Audio-/Video-Unterstützung | Ja (direktes Audio-/Video-Embedding). | Nein (nur Text). | Nein (nur Text). |
| Typische Anwendungsfälle | Multimodales Retrieval, RAG, semantische Suche über Dateitypen hinweg, Sprach-Retrieval, Video-Suche. | Text-Retrieval, mehrsprachiges RAG. | Text-Retrieval, semantische Suche, RAG — starke mehrsprachige Textleistung. |
Technische Spezifikationen & Beschränkungen
Standard- & anpassbare Embedding-Größe
- Standard: 3,072 Dimensionen.
- Anpassbar: Der Parameter
output_dimensionalityermöglicht kleinere Ausgaben, um Speicher/CPU zu sparen. Anwendungsfälle mit sehr großen Vektorspeichern reduzieren die Dimensionen oft auf 512–1.024 aus Kostengründen und akzeptieren dafür gewisse Genauigkeitseinbußen.
Unterstützte Modalitäten und Limits pro Anfrage
- Bilder: PNG, JPEG — bis zu 6 Bilder pro Anfrage (laut Anbieterangaben).
- Video: MP4, MOV — laut Anbieter bis zu ca. 128 Sekunden pro Video für Embedding in einer einzelnen Anfrage.
- Audio: MP3, WAV — laut Anbieter bis zu ca. 80 Sekunden pro Audioeingabe.
- Dokumente: PDFs — bis zu 6 Seiten pro Anfrage (laut Anbieter).
- Token-Limit für Textinhalte: Modell unterstützt große Texteingaben; praktische Token-Grenzen pro Anfrage existieren (siehe API-Dokumentation und Vertex AI-Kontingente).
Verfügbarkeit & Zugriff
- Public Preview: Gemini Embedding 2 wurde als Public Preview veröffentlicht und ist über die Gemini API sowie Google Clouds Vertex AI für unmittelbare experimentelle Nutzung verfügbar
Häufig gestellte Fragen (FAQ)
F1: Welche Modalitäten unterstützt Gemini Embedding 2?
A: Text, Bilder (PNG/JPEG), Video (MP4/MOV), Audio (MP3/WAV) und PDF-Dokumente — alle werden in denselben semantischen Vektorraum abgebildet.
F2: Wie groß ist die Standardvektorgröße für Gemini Embedding 2?
A: Standard sind 3,072 Dimensionen. Über die API können Sie eine kleinere Ausgabedimensionalität anfordern.
F3: Ist Gemini Embedding 2 bereits verfügbar?
A: Ja — es wurde als Public Preview angekündigt und ist über die Gemini API und Vertex AI verfügbar (siehe die Modell-ID gemini-embedding-2-preview und das aktuelle Changelog).
F4: Wie schneidet es im Vergleich zu Embeddings anderer Anbieter ab?
A: Unabhängige Anbietertests berichten, dass Gemini Embedding 2 zu den besten proprietären Modellen für mehrsprachigen Text gehört und für mehrere multimodale Aufgaben State-of-the-Art-Leistung zeigt. Genaue Platzierungen variieren je nach Aufgabe und Datensatz; testen Sie auf Ihren eigenen Daten.
F5: Muss ich Audio transkribieren, um Gemini Embedding 2 zu nutzen?
A: Nein — Gemini Embedding 2 kann Audio direkt akzeptieren und Embeddings ohne vorherige Transkription erzeugen, was end-to-end semantisches Audio-Retrieval ermöglicht.
F6: Wie senke ich die Speicherkosten für 3,072-dimensionale Vektoren?
A: Optionen umfassen das Anfordern einer kleineren output_dimensionality, die Nutzung von float16/Quantisierung/PQ sowie das Speichern komprimierter Repräsentationen in Ihrer Vektor-Datenbank. Anbieter-Posts liefern Workflows und Best Practices.
Wie geht es weiter — sollte ich es jetzt einführen?
Gemini Embedding 2 ist ein großer Schritt zur Vereinheitlichung des multimodalen Retrievals und vereinfacht Architekturen, die zuvor separate Retriever für Text, Vision und Sprache erforderten. Wichtige Entscheidungspunkte für die Einführung:
- Früher einführen, wenn Ihr Produkt robustes Cross-Modal-Retrieval (Text↔Bild/Video/Audio) benötigt oder wenn die Pflege mehrerer Einzelmodalitäts-Retriever teuer und komplex ist.
- Jetzt pilotieren, wenn Sie MRL-Trunkierung evaluieren und Kosten vs. Qualität messen möchten (behalten Sie einen hybriden Betrieb bei: 1536 als primär, 3072 fürs Re-Ranking).
- Abwarten, wenn Ihre Workloads extrem kostenempfindlich sind und nur Text-Retrieval benötigt wird — Top-Text-only-Modelle (z. B. OpenAI text-embedding-3-large) bleiben konkurrenzfähig und mitunter günstiger, abhängig von Pipeline und Vertrag.
Entwickler können über die CometAPI jetzt auf Gemini Embedding 2 und die OpenAI text-embedding-3 API zugreifen. Um zu beginnen, erkunden Sie die Fähigkeiten des Modells im Playground und konsultieren Sie den API-Leitfaden für detaillierte Anweisungen. Bevor Sie zugreifen, stellen Sie bitte sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bietet einen deutlich niedrigeren Preis als den offiziellen, um Ihnen die Integration zu erleichtern.
Bereit zu starten?→ Sign up for cometapi today !
Wenn Sie mehr Tipps, Anleitungen und Neuigkeiten zu KI erfahren möchten, folgen Sie uns auf VK, X und Discord!