
.webp&w=3840&q=75)
GLM-5.1 markiert einen entscheidenden Wandel im KI-Landschaftsbild. Während chinesische KI-Unternehmen die Kommerzialisierung beschleunigen und zugleich Spitzenfähigkeiten offenlegen, verkleinert dieses Modell den Abstand zu proprietären Spitzenreitern wie OpenAIs GPT-5.4, Anthropics Claude Opus 4.6 und Googles Gemini 3.1 Pro—insbesondere in der realen Softwareentwicklung. Auf derselben 744B-Parameter-MoE-Architektur wie GLM-5 trainiert, aber stark für agentische Workflows optimiert, glänzt es dort, wo die meisten LLMs straucheln: lange, mehrdeutige, iterative Aufgaben, die Planung, Experimentieren, Debugging und Selbstkorrektur über Tausende von Tool-Aufrufen erfordern.
Jetzt integrieren CometAPI GLM-5.1 und GLM-5, und Entwickler können auch andere führende westliche Modelle einsehen und zu sehr niedrigen API-Preisen darauf zugreifen (was ebenfalls ein Vorteil von CometAPI gegenüber anderen Wettbewerbern ist).
Was ist GLM-5.1?
GLM-5.1 ist das neueste Flaggschiff-Sprachmodell von Z.ai und der jüngste Vorstoß des Unternehmens in agentenartige Softwarearbeit mit langem Zeithorizont. In den Worten von Z.ai ist es für Aufgaben konzipiert, die kontinuierliche Ausführung statt One‑Shot‑Antworten benötigen, und als ein Modell positioniert, das innerhalb eines einzigen erweiterten Laufs planen, ausführen, verfeinern und liefern kann. Laut den Release Notes von Z.ai basiert GLM-5.1 auf Multi‑Turn Supervised Fine‑Tuning, Reinforcement Learning und einem Rahmenwerk zur Bewertung der Prozessqualität und verbessert Stabilität, Konsistenz und Toolnutzung bei lang andauernden Aufgaben.
Diese Positionierung ist wichtig, weil GLM-5.1 nicht einfach als „noch ein Chat‑Modell“ verkauft wird. Es richtet sich an Engineering‑Workflows, in denen Modelle ein Ziel im Blick behalten, Zwischenschritte bewältigen und sich von Fehlern erholen müssen, ohne den Faden zu verlieren; es wird als Modell für autonomes Planen, dauerhafte Ausführung, Fehlerbehebung und Strategieiteration verstanden—eine ganz andere Produktgeschichte als ein beiläufiger Assistent oder ein Coding‑Copilot mit kurzer Kontextspanne.
Ein nützliches praktisches Detail: GLM-5.1 ist rein textbasiert, wird im GLM Coding Plan unterstützt und kann in populären Coding‑Agenten wie Claude Code und OpenClaw verwendet werden, was es besonders relevant für Teams macht, die ein Modell in bestehende Entwickler‑Workflows integrieren möchten, statt diese zu ersetzen.
Kerntechnische Spezifikationen (von GLM‑5 übernommen und verfeinert):
- Architektur: Mixture‑of‑Experts (MoE) mit insgesamt 744 Milliarden Parametern und etwa 40 Milliarden aktiven Parametern pro Inferenz.
- Kontextfenster: 203K–204.8K Tokens (mit Unterstützung für bis zu 131K Output‑Tokens).
- Wesentliche Verbesserungen: DeepSeek Sparse Attention (DSA) für effiziente Langkontext‑Verarbeitung und geringere Betriebskosten; fortgeschrittene asynchrone Reinforcement‑Learning‑Infrastruktur (über Z.ais „slime“-Framework) für effektiveres Post‑Training.
- Verfügbarkeit: Open Weights (MIT‑Lizenz auf Hugging Face via zai-org/GLM-5.1), API‑Zugang über die Plattform von Z.ai und Aggregatoren wie CometAPI sowie Integration in GLM Coding Plan‑Tools (Claude Code / OpenClaw kompatibel).
Anders als frühere GLM‑Modelle, die sich auf allgemeine Intelligenz oder kurzes „Vibe Coding“ konzentrierten, zielt GLM-5.1 auf produktionsreife autonome Agenten. Es kann komplexe Engineering‑Projekte über Stunden ohne menschliches Eingreifen eigenständig planen, ausführen, benchmarken, debuggen und iterieren—Fähigkeiten, die es als direkten Konkurrenten zu spezialisierten Coding‑Agenten von Anthropic und OpenAI positionieren.
Die Veröffentlichung fiel mit einer API‑Preiserhöhung von ~10% zusammen (Input‑Tokens ~$0.54/M, Output ~$4.40/M), bleibt jedoch dramatisch günstiger als Äquivalente wie Anthropics Opus 4.6 (250–470% teurer).
GLM-5.1 Benchmark-Leistung
Z.ai positioniert GLM-5.1 als das weltweit stärkste Open‑Source‑Modell und als globalen Top‑3‑Performer im agentischen Programmieren. Leistungsdaten stammen aus offiziellen Bewertungen auf SWE‑Bench Pro, NL2Repo, Terminal‑Bench 2.0 und maßgeschneiderten Langhorizont‑Szenarien.
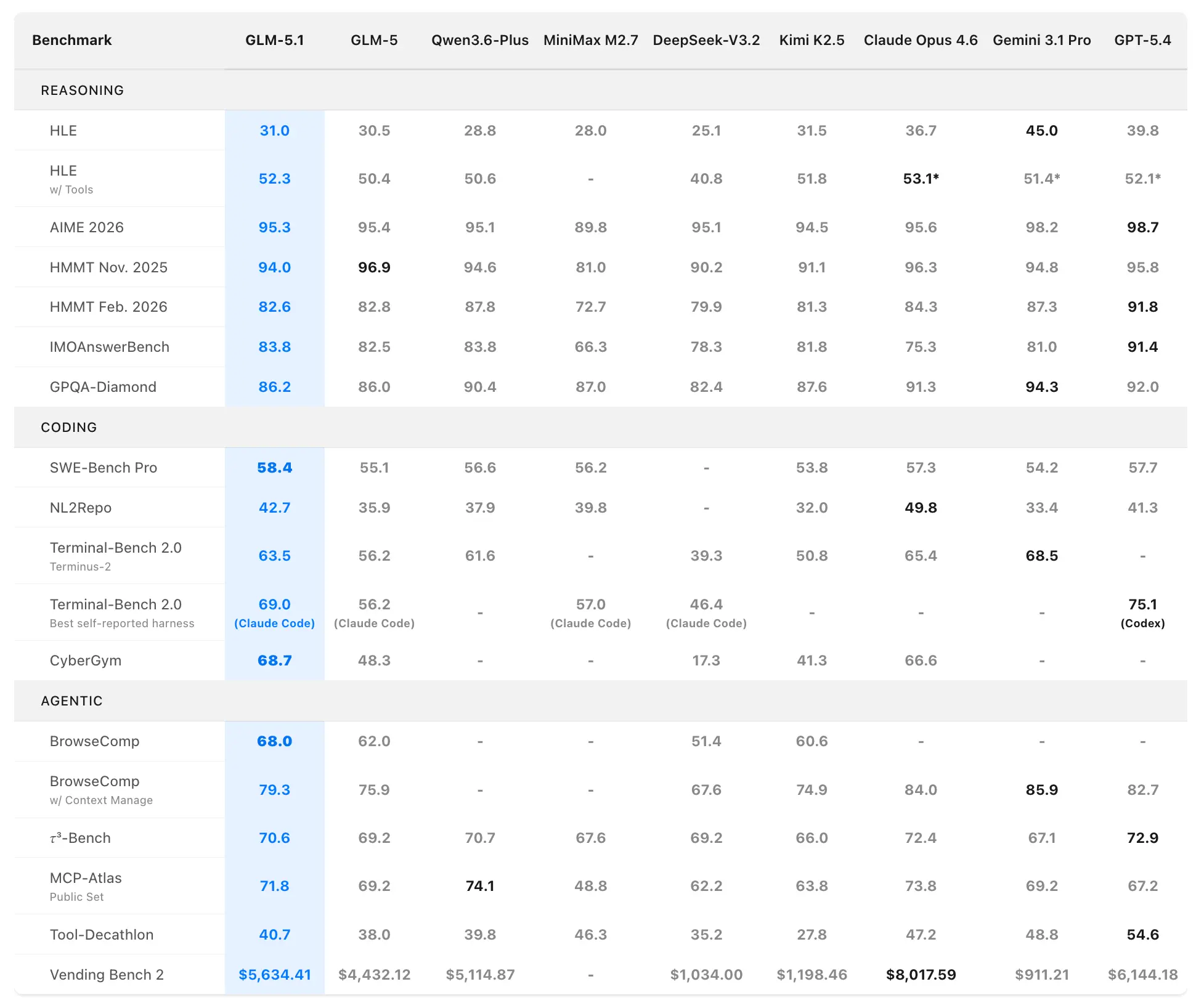
Programmier- und Agentik-Benchmarks
SWE‑Bench Pro (realistische Software‑Engineering‑Aufgaben, die Repository‑Navigation, Code‑Bearbeitung und Funktionsverifikation erfordern):
- GLM-5.1: 58.4 (neuer Stand der Technik)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 ist das erste inländische (chinesische) und Open‑Source‑Modell, das den Spitzenplatz auf diesem rigorosen Benchmark beansprucht, der professionellen Entwickler‑Workflows sehr nahe kommt.
NL2Repo (von natürlicher Sprache zu vollständiger Repository‑Generierung):
- GLM-5.1: 42.7 (deutlicher Vorsprung gegenüber GLM‑5 mit 35.9)
- Wettbewerbsmodelle liegen zwischen 32.0–49.8 (konkrete Spitzenreiter variieren je nach Harness).
Terminal‑Bench 2.0 (reale Terminal‑ und Systemaufgaben):
- Terminus‑2‑Harness: GLM-5.1 63.5 (vs. GLM‑5 56.2)
- Bestes selbst berichtet (Claude Code): bis zu 69.0.
In einer separaten Coding‑Harness‑Evaluation (im Claude‑Code‑Stil) erzielte GLM-5.1 45.3—erreichte 94.6% von Claude Opus 4.6 mit 47.9 und eine 28%‑Verbesserung gegenüber GLM‑5 mit 35.4.
Gesamtrang: #1 Open‑Source, #1 chinesisches Modell, #3 global über SWE‑Bench Pro + NL2Repo + Terminal‑Bench.
Leistung bei Langzeitaufgaben: Der eigentliche Differenziator
Standard‑Benchmarks messen One‑Shot‑ oder Kurzsitzungs‑Performance. GLM-5.1 glänzt in erweiterten autonomen Läufen:
- VectorDBBench‑Optimierung (600+ Iterationen, 6,000+ Tool‑Aufrufe): Ausgehend von einem Rust‑Skelett hat GLM-5.1 Indexierung, Kompression, Routing und Pruning iterativ neu gestaltet und 21.5k QPS (6× besser als der bisherige 50‑Turn‑Bestwert von 3,547 QPS durch Claude Opus 4.6) bei gleichzeitiger Aufrechterhaltung von ≥95% Recall auf SIFT‑1M erreicht. Es zeigte „Treppen“-Fortschritt mit strukturellen Durchbrüchen alle 100–200 Iterationen.
- KernelBench Level 3 (vollständige ML‑Modell‑Optimierung, 1,000+ Turns): Geometrisches Mittel der Beschleunigung von 3.6× über 50 komplexe Probleme (besser als torch.compile max‑autotune mit 1.49×). GLM-5.1 verbesserte sich weiter, lange nachdem GLM‑5 ein Plateau erreicht hatte; nur Claude Opus 4.6 lag mit 4.2× knapp vorne.
- Linux‑Desktop‑Web‑App‑Build (8+ Stunden, offen): Nur mit einer natürlichsprachlichen Vorgabe und ohne Startcode baute GLM-5.1 autonom eine funktionale Linux‑ähnliche Desktop‑Umgebung—mit Taskleiste, Fenstern, Interaktionen und Feinschliff—wo frühere Modelle nur einfache Skelette erzeugten.
Diese Ergebnisse zeigen, dass GLM-5.1 über extrem lange Zeithorizonte Kohärenz bewahrt, sich selbst evaluiert, Strategien überarbeitet und lokalen Optima entkommt—Fähigkeiten, die Z.ai explizit für reale agentische Systeme entwickelt hat.
Worin unterscheidet sich GLM-5.1 von GLM-5?
GLM‑5 und GLM‑5.1 sind eng verwandt, aber nicht gleich positioniert. GLM‑5 ist Z.AIs früheres Foundation‑Modell für Agentic Engineering. Es ist für komplexes System‑Engineering und langreichweitige Agentenaufgaben ausgelegt, mit Open‑Weight‑SOTA im Codieren und Agentenfähigkeit sowie einer Programmierleistung, die Claude Opus 4.5 in realen Programmier‑Szenarien nahekommt. Es erzielt 77.8 auf SWE‑bench Verified und 56.2 auf Terminal Bench 2.0.
GLM‑5.1 hingegen wird als nächster Schritt in Richtung Langhorizont‑Aufgaben und verlässlichere, dauerhafte Ausführung gerahmt, verbessert Stabilität, Konsistenz und Toolnutzung bei lang andauernden Aufgaben und ist insgesamt näher an Claude Opus 4.6 ausgerichtet. Mit anderen Worten: GLM‑5 ist das frühere, engineering‑zentrierte Foundation‑Modell, während GLM‑5.1 das stärker auf Ausdauer ausgelegte Flaggschiff ist.
Es gibt auch architektonische und Training‑Unterschiede in der GLM‑5‑Generation, die den Sprung erklären. GLM‑5 wurde von 355B Parametern (32B aktiviert) auf 744B Parameter (40B aktiviert) erweitert, die Pre‑Training‑Daten stiegen von 23T auf 28.5T, ein asynchrones Reinforcement‑Learning‑Framework wurde hinzugefügt und DeepSeek Sparse Attention integriert, um die Qualität bei langen Texten zu bewahren und zugleich die Effizienz zu steigern. Diese Details sind an GLM‑5 geknüpft, bilden aber die Basis, auf der GLM‑5.1 offenbar aufbaut.
GLM-5.1 vs andere Frontier-Modelle
GLM‑5.1 ragt als stärkster Open‑Source‑Herausforderer heraus und bietet ein überzeugendes Preis/Leistungs‑Verhältnis.
Vergleichstabelle: Wichtige Programmier- und Agentik‑Benchmarks (April 2026)
| Modell | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding-Harness-Score | Langzeitausführung? | Open-Source? | Ungef. API-Preis (Input/Output pro M Tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% von Opus) | Ja (600+ Iter., 8 Std.) | Ja | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Begrenzt | Ja | Niedriger (vor Erhöhung) |
| GPT-5.4 | 57.7 | — | — | — | Stark | Nein | Höher |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Am stärksten | Nein | ~250–470% teurer |
| Gemini 3.1 Pro | 54.2 | — | — | — | Gut | Nein | Höher |
Fazit: GLM‑5.1 gewinnt bei Open‑Source‑Zugänglichkeit, Kosten und spezifischen Langhorizont‑Coding‑Metriken. Es liefert sich Duelle mit Closed‑Source‑Spitzenreitern in agentischen Szenarien und demokratisiert zugleich Spitzenfähigkeiten.
Anwendungsszenarien für GLM-5.1
1) Autonomes Software-Engineering
GLM‑5.1 ist am überzeugendsten, wenn die Aufgabe einem realen Engineering‑Sprint ähnelt: Codebasis lesen, die Änderung planen, implementieren, testen, Regressionen beheben und iterieren, bis das Ergebnis stabil ist. Z.ais Release Notes betonen ausdrücklich autonomes Planen, dauerhafte Ausführung, Fehlerbehebung und Strategieiteration—damit wirkt dieses Modell wie maßgeschneidert für Coding‑Agenten und Software‑Lieferpipelines.
2) Lang laufende Agenten-Workflows
Wenn Ihr Anwendungsfall viele Tool‑Aufrufe, lange mehrstufige Workflows oder wiederholte Selbstkorrektur umfasst, passt das Design von GLM‑5.1 sehr gut. Die Dokumentation hebt Tool‑Invocation, strukturierte Ausgaben, MCP‑Integration und Tool‑Streaming‑Support hervor—allesamt nützlich, wenn ein Modell nicht nur antwortet, sondern in einem größeren System operiert.
3) Enterprise-Wissensarbeit und Reporting
GLM‑5.1 ist auch für Büroproduktivitätsaufgaben wie PowerPoint‑, Word‑, PDF‑ und Excel‑Workflows positioniert. Z.ai sagt, es verbessere komplexe Inhaltsorganisation, Layout‑Design, strukturierte Ausgaben und visuellen Feinschliff—damit ist es ein plausibler Fit für Berichtserstellung, Lehrmaterialien, Forschungszusammenfassungen und andere dokumentlastige Arbeiten.
4) Frontend-Prototyping und Artefakte
Laut Z.ai eignet sich GLM‑5.1 gut für Website‑Generierung, interaktive Seiten und Frontend‑Prototyping—mit weniger schablonenhafter Struktur und besserer Aufgabenerfüllungsqualität. Das legt eine gute Eignung für Produktteams nahe, die eine schnelle Brücke vom Briefing zum Prototyp brauchen, insbesondere wenn der Prototyp nutzbar statt nur hübsch sein muss.
5) Komplexe Konversation und Befolgung von Anweisungen
Obwohl die Schlagzeile das Programmieren ist, wird GLM‑5.1 auch als stärker in offenen Q&A, komplexen Anweisungen und Multi‑Turn‑Interaktionen beschrieben. Das macht es nützlich für Assistenten‑Workflows, in denen das Modell Einschränkungen im Blick behalten, Ausgaben überarbeiten und Kontext über längere Gespräche hinweg bewahren muss.
Fazit: Warum GLM-5.1 im Jahr 2026 wichtig ist
GLM‑5.1 ist nicht nur ein weiterer inkrementeller Release—es signalisiert die Ankunft wirklich fähiger, agentischer Open‑Source‑KI. Indem es in den härtesten realen Engineering‑Benchmarks exzelliert und zugleich erschwinglich und offen bleibt, hat Z.ai die Messlatte für die gesamte Branche höher gelegt. Ob Solo‑Entwickler, Enterprise‑Team oder Forscher: GLM‑5.1 bietet unvergleichliche Autonomie für Langhorizont‑Coding‑Aufgaben zu einem Bruchteil der proprietären Kosten.
Bereit, es auszuprobieren? Prüfen Sie das CometAPI GLM‑5.1‑Modell, das Hugging‑Face‑Repository oder den GLM Coding Plan für den sofortigen Zugriff.