

GPT-5.2 ist OpenAIs Punkt-Release für Dezember 2025 in der GPT-5-Familie: eine Flaggschiff‑Multimodalmodellfamilie (Text + Vision + Tools), abgestimmt auf den Einsatz in professioneller Wissensarbeit, Langkontext‑Reasoning, agentisches Tool‑Verhalten und Software‑Engineering. OpenAI positioniert GPT‑5.2 als das bislang leistungsfähigste Modell der GPT‑5‑Serie und gibt an, es mit Schwerpunkt auf zuverlässiges mehrstufiges Reasoning, die Verarbeitung sehr großer Dokumente sowie verbesserte Sicherheits-/Policy‑Compliance entwickelt zu haben; das Release umfasst drei nutzerseitige Varianten — Instant, Thinking und Pro — und wird zunächst für zahlende ChatGPT‑Abonnent:innen und API‑Kund:innen ausgerollt.
Was ist GPT-5.2 und warum ist es wichtig?
GPT‑5.2 ist das neueste Mitglied der GPT‑5‑Familie von OpenAI — eine neue „Frontier“-Modellserie, die speziell dafür entwickelt wurde, die Lücke zwischen Single‑Turn‑Konversationsassistenten und Systemen zu schließen, die über lange Dokumente hinweg schlussfolgern, Tools aufrufen, Bilder interpretieren und mehrstufige Workflows zuverlässig ausführen müssen. OpenAI positioniert 5.2 als das bisher leistungsfähigste Release für professionelle Wissensarbeit: Es setzt neue State‑of‑the‑Art‑Ergebnisse auf internen Benchmarks (insbesondere einem neuen GDPval‑Benchmark für Wissensarbeit), zeigt stärkere Coding‑Performance auf Software‑Engineering‑Benchmarks und bietet deutlich verbesserte Langkontext‑ und Vision‑Fähigkeiten.
Praktisch betrachtet ist GPT‑5.2 mehr als nur „ein größeres Chat‑Modell“. Es ist eine Familie aus drei abgestimmten Varianten (Instant, Thinking, Pro), die Latenz, Reasoning‑Tiefe und Kosten gegeneinander abwägen — und die zusammen mit OpenAIs API und ChatGPT‑Routing eingesetzt werden können, um lange Forschungsjobs auszuführen, Agenten zu bauen, die externe Tools aufrufen, komplexe Bilder und Diagramme zu interpretieren und produktionsreifen Code mit höherer Treue als frühere Releases zu generieren. Das Modell unterstützt sehr große Kontextfenster (OpenAI‑Dokumente nennen ein Kontextfenster mit 400.000 Tokens und ein Maximal‑Output‑Limit von 128.000 Tokens für die Flaggschiffmodelle), neue API‑Funktionen für explizite Reasoning‑Aufwandsstufen und „agentisches“ Tool‑Aufrufverhalten.
5 Kernfähigkeiten, die in GPT-5.2 aufgerüstet wurden
1) Ist GPT‑5.2 besser bei mehrschrittiger Logik und Mathematik?
GPT‑5.2 bringt schärferes mehrschrittiges Reasoning und spürbar bessere Leistungen in Mathematik und strukturierter Problemlösung. OpenAI sagt, sie hätten eine feinere Steuerung des Reasoning‑Aufwands (neue Stufen wie xhigh) hinzugefügt, „Reasoning‑Token“ unterstützt und das Modell darauf getrimmt, die Chain‑of‑Thought über längere interne Reasoning‑Spuren zu halten. Benchmarks wie FrontierMath und ARC‑AGI‑artige Tests zeigen deutliche Zugewinne gegenüber GPT‑5.1; mit größeren Abständen auf domänenspezifischen Benchmarks, die in wissenschaftlichen und finanziellen Workflows genutzt werden. Kurz gesagt: GPT‑5.2 „denkt länger“, wenn man es darum bittet, und kann kompliziertere symbolische/mathematische Aufgaben mit besserer Konsistenz lösen.

| RC-AGI-1 (Verified) Abstraktes Schließen | 86.2% | 72.8% |
|---|---|---|
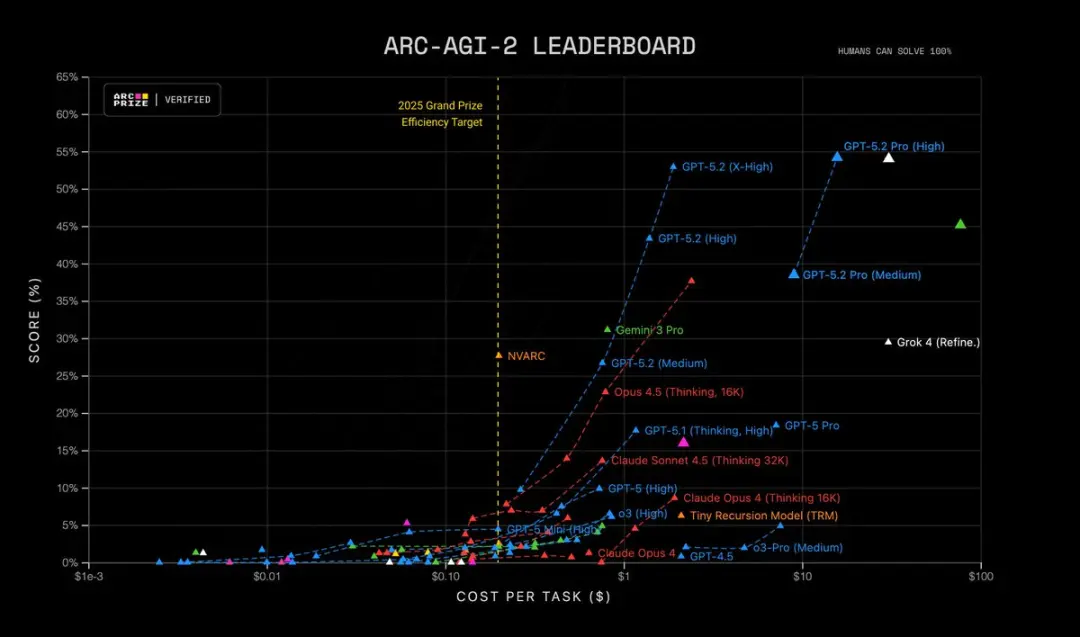
| ARC-AGI-2 (Verified) Abstraktes Schließen | 52.9% | 17.6% |
GPT‑5.2 Thinking setzt Rekorde in mehreren fortgeschrittenen Tests zu Wissenschafts- und Mathematik‑Reasoning:
- GPQA Diamond Science Quiz: 92.4% (Pro‑Version 93.2%)
- ARC‑AGI‑1 Abstraktes Reasoning: 86.2% (erstes Modell, das die 90%-Schwelle durchbricht)
- ARC‑AGI‑2 Höherstufiges Reasoning: 52.9%, neuer Rekord für das Thinking‑Chain‑Modell
- FrontierMath Test für fortgeschrittene Mathematik: 40.3%, deutlich über dem Vorgänger;
- HMMT Mathematik‑Wettbewerbsaufgaben: 99.4%
- AIME Mathetest: 100% vollständige Lösung
Darüber hinaus ist GPT‑5.2 Pro (High) auf ARC‑AGI‑2 State of the Art und erreicht eine Punktzahl von 54.2% bei Kosten von $15.72 pro Aufgabe! Es übertrifft alle anderen Modelle.
Warum das wichtig ist: Viele Aufgaben in der realen Welt — Finanzmodellierung, Versuchsdesign, Programmsynthese mit formalem Reasoning — werden durch die Fähigkeit eines Modells begrenzt, viele korrekte Schritte zu verketten. GPT‑5.2 reduziert „halluzinierte Schritte“ und erzeugt stabilere Zwischen‑Reasoning‑Spuren, wenn man es bittet, den Rechenweg offenzulegen.
2) Wie haben sich Langtextverständnis und dokumentübergreifendes Reasoning verbessert?
Langkontext‑Verständnis ist eine der herausragenden Verbesserungen. Das zugrunde liegende Modell von GPT‑5.2 unterstützt ein Kontextfenster von 400k Tokens und — wichtig — hält eine höhere Genauigkeit aufrecht, wenn relevante Inhalte tief in diesen Kontext hineinrutschen. GDPval, eine Aufgabensuite für „gut spezifizierte Wissensarbeit“ über 44 Berufsbilder, bei der GPT‑5.2 Thinking bei einem großen Anteil der Aufgaben mit Expert:innen auf Augenhöhe liegt oder sie übertrifft. Unabhängige Berichte bestätigen, dass das Modell Informationen über viele Dokumente hinweg deutlich besser hält und synthetisiert als frühere Modelle. Das ist ein wirklich praktischer Fortschritt für Aufgaben wie Due Diligence, juristische Zusammenfassungen, Literaturreviews und das Verständnis von Codebasen.
GPT‑5.2 kann Kontexte mit bis zu 256.000 Tokens verarbeiten (entspricht ungefähr 200+ Seiten Dokumente). Außerdem erreichte GPT‑5.2 Thinking im „OpenAI MRCRv2“‑Test zum Langtextverständnis eine Genauigkeit nahe 100%.
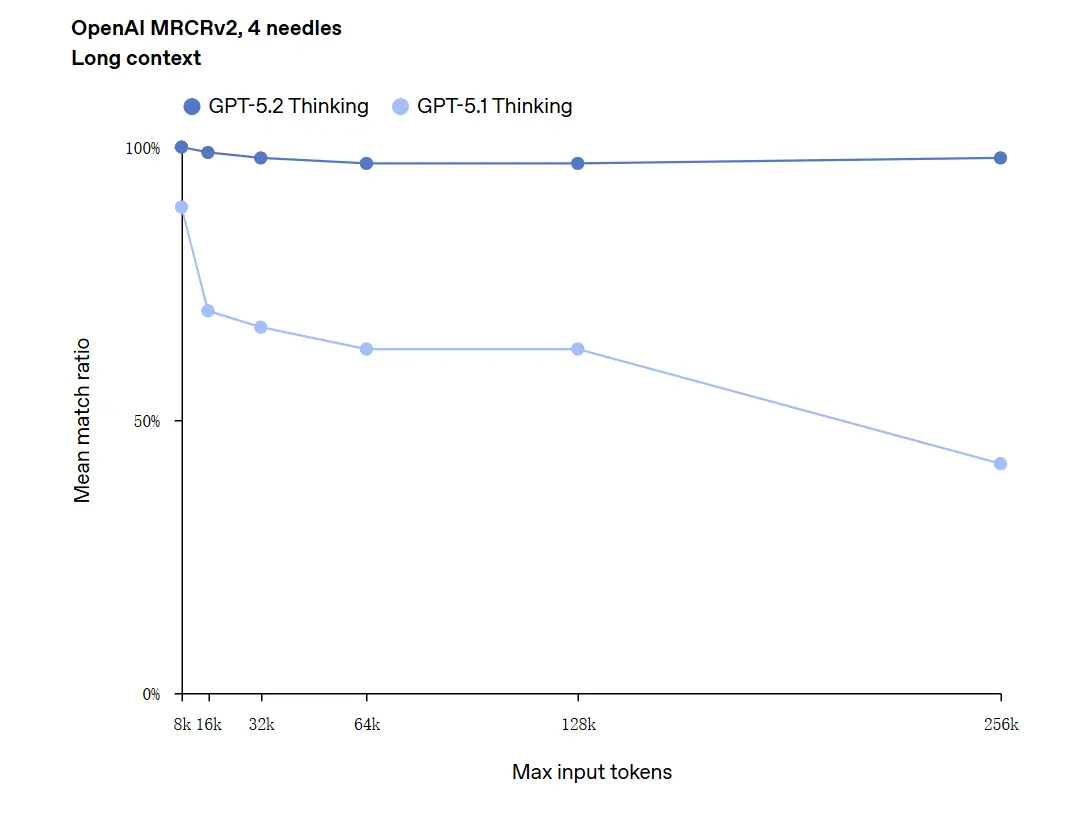
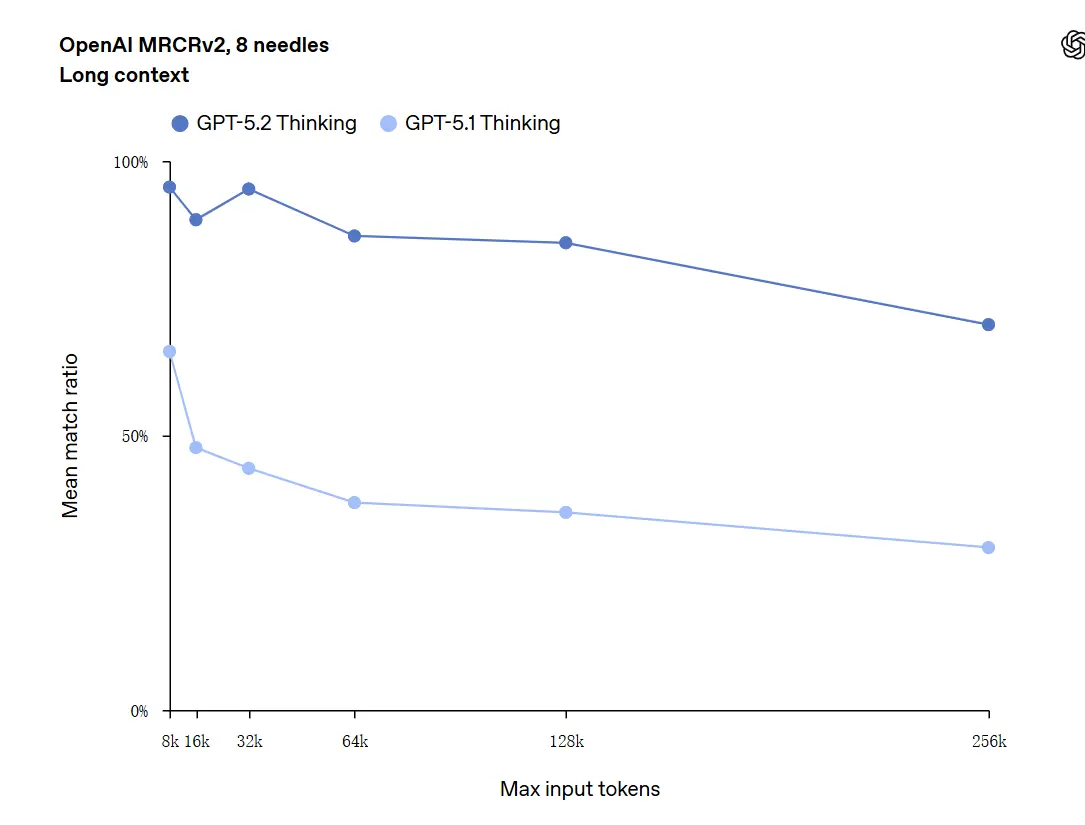
Einschränkung zu „100% Genauigkeit“: Die beschriebenen Verbesserungen gelten als „nahezu 100%“ für eng umrissene Mikro‑Aufgaben; OpenAIs Daten sind besser beschrieben als „State of the Art und in vielen Fällen auf oder über dem Niveau menschlicher Expert:innen bei den evaluierten Aufgaben“, nicht wörtlich fehlerfrei in allen Anwendungen. Benchmarks zeigen große Fortschritte, aber keine universelle Perfektion.
3) Was ist neu beim visuellen Verständnis und multimodalen Reasoning?
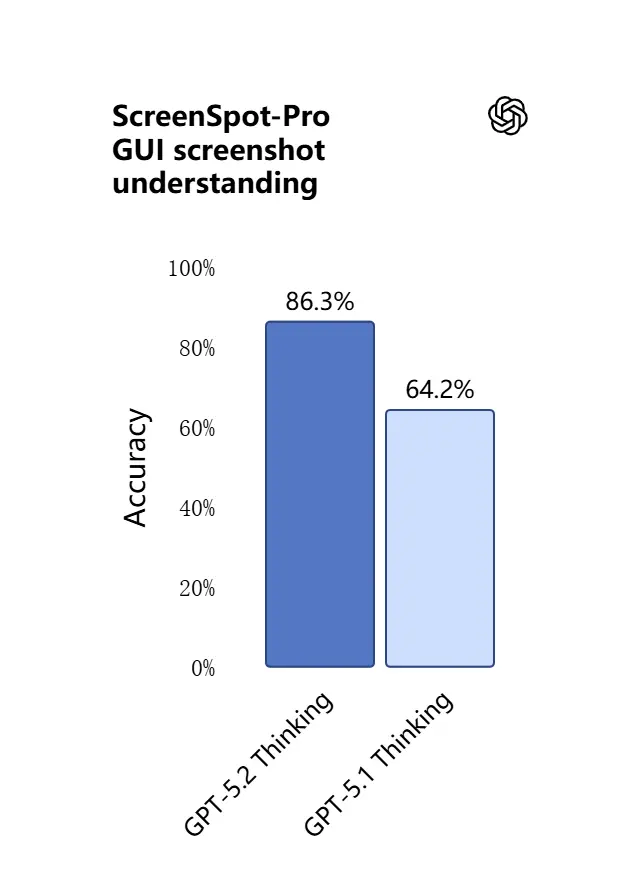
Die Vision‑Fähigkeiten in GPT‑5.2 sind schärfer und praxisnäher. Das Modell ist besser darin, Screenshots zu interpretieren, Diagramme und Tabellen zu lesen, UI‑Elemente zu erkennen und visuelle Eingaben mit langem Textkontext zu kombinieren. Es geht nicht nur um Captioning: GPT‑5.2 kann strukturierte Daten aus Bildern extrahieren (z. B. Tabellen in einem PDF), Grafiken erklären und über Diagramme so schlussfolgern, dass nachgelagerte Tool‑Aktionen unterstützt werden (z. B. aus einem fotografierten Bericht eine Tabelle generieren).
.webp)
Praktischer Effekt: Teams können vollständige Foliensätze, gescannte Forschungsberichte oder bildlastige Dokumente direkt in das Modell einspeisen und um dokumentübergreifende Synthesen bitten — das reduziert die manuelle Extraktionsarbeit erheblich.
4) Wie haben sich Tool‑Aufrufe und Aufgabenausführung verändert?
GPT‑5.2 treibt agentisches Verhalten weiter voran: Es ist besser darin, mehrstufige Aufgaben zu planen, zu entscheiden, wann externe Tools aufgerufen werden sollen, und Sequenzen aus API‑/Tool‑Aufrufen auszuführen, um einen Job end‑to‑end abzuschließen. Verbesserungen beim „agentischen Tool‑Calling“ — das Modell schlägt einen Plan vor, ruft Tools auf (Datenbanken, Compute, Dateisysteme, Browser, Code‑Runner) und synthetisiert Ergebnisse zuverlässiger als frühere Modelle zu einem finalen Artefakt. Die API führt Routing‑ und Sicherheitskontrollen ein (Listen erlaubter Tools, Tool‑Scaffolding) und die ChatGPT‑UI kann Anfragen automatisch an die passende 5.2‑Variante (Instant vs. Thinking) routen.
GPT‑5.2 erreichte 98.7% im Tau2‑Bench‑Telekom‑Benchmark und demonstriert damit seine ausgereiften Tool‑Calling‑Fähigkeiten in komplexen, mehrstufigen Aufgaben.
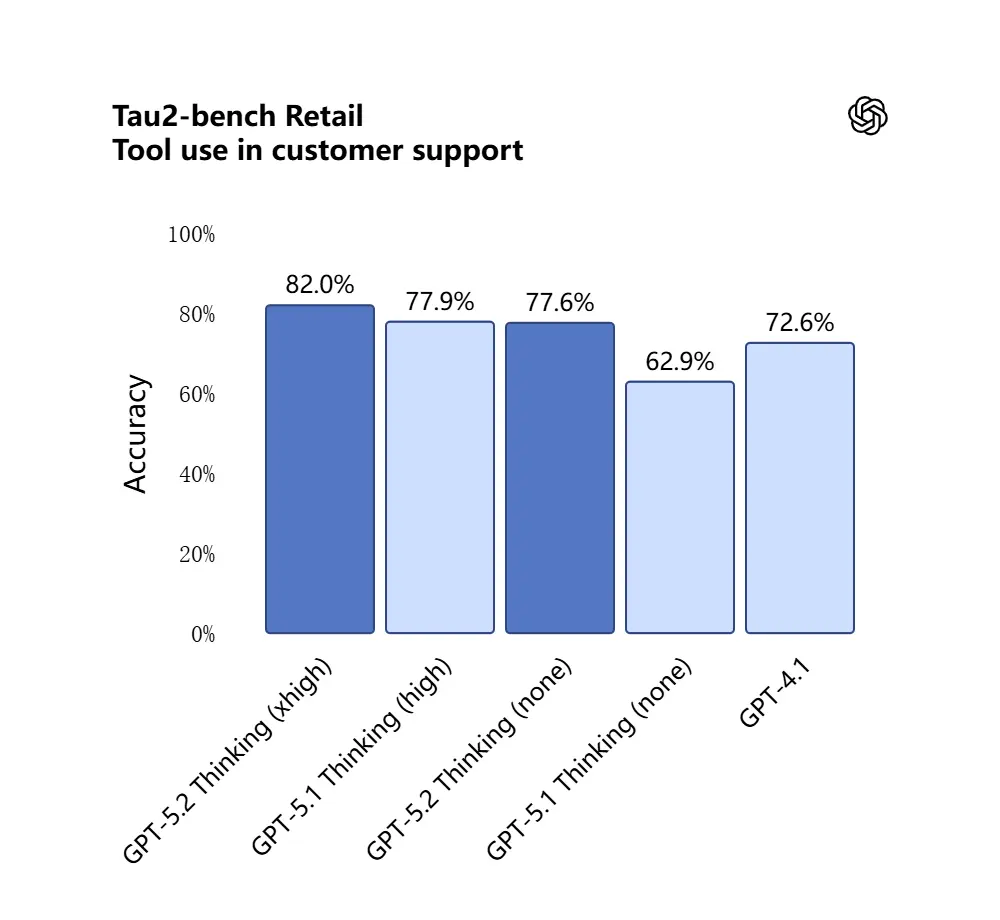
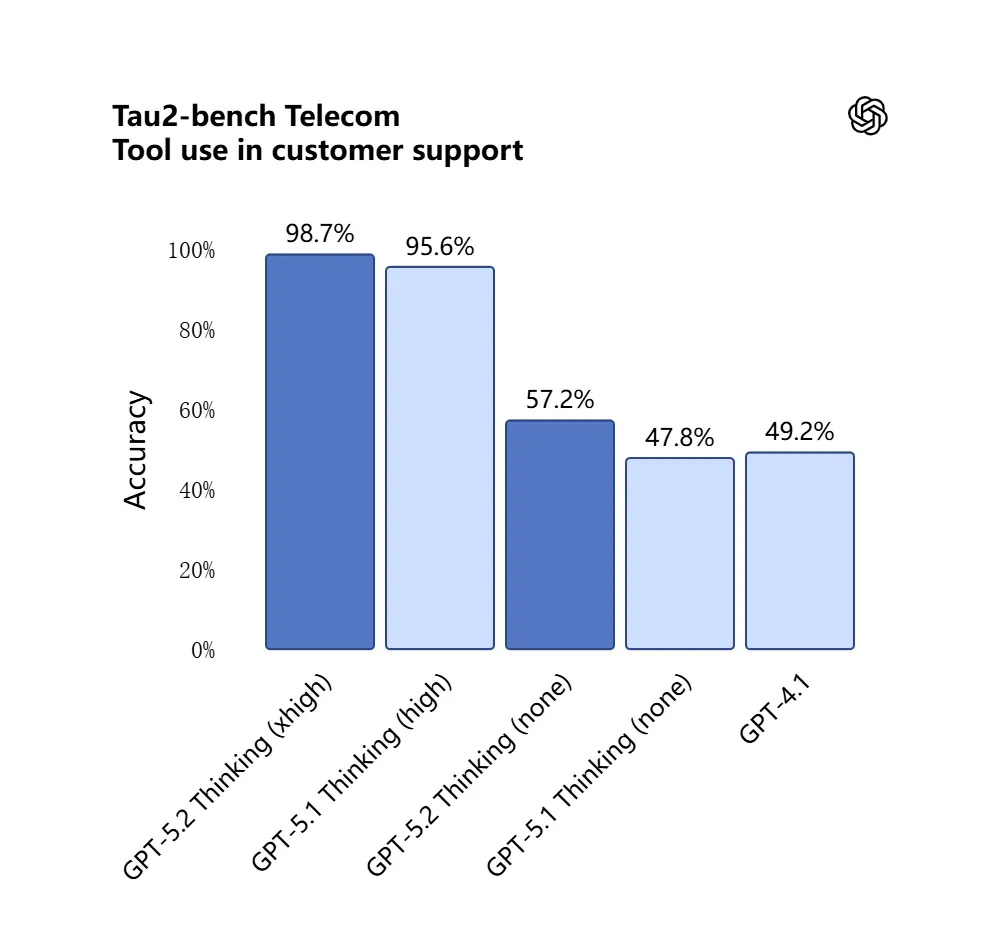
Warum das wichtig ist: Dadurch wird GPT‑5.2 als autonomer Assistent nützlicher für Workflows wie „diese Verträge einlesen, Klauseln extrahieren, eine Tabelle aktualisieren und eine Zusammenfassungs‑E‑Mail schreiben“ — Aufgaben, die zuvor eine sorgfältige Orchestrierung erforderten.
5) Programmierfähigkeit weiterentwickelt
GPT‑5.2 ist bei Software‑Engineering‑Aufgaben deutlich besser: Es schreibt vollständigere Module, generiert und führt Tests zuverlässiger aus, versteht komplexe Projekt‑Abhängigkeitsgraphen und neigt weniger zu „lazy coding“ (Auslassen von Boilerplate oder fehlende Verdrahtung von Modulen). Auf industriegradigen Coding‑Benchmarks (SWE‑bench Pro, etc.) setzt GPT‑5.2 neue Rekorde. Für Teams, die LLMs als Pair‑Programmierer einsetzen, kann diese Verbesserung die manuelle Verifikation und Nacharbeit nach der Generierung reduzieren.
Im SWE‑Bench‑Pro‑Test (realweltliche, industrielle Software‑Engineering‑Aufgabe) stieg die Punktzahl von GPT‑5.2 Thinking auf 55.6%, während es im SWE‑Bench Verified einen neuen Höchstwert von 80% erreichte.
_Software%20engineering.webp)
In der Praxis bedeutet das:
- Automatisches Debugging von Code in Produktionsumgebungen führt zu höherer Stabilität;
- Unterstützung für mehrsprachige Programmierung (nicht auf Python beschränkt);
- Fähigkeit, End‑to‑End‑Reparaturaufgaben eigenständig abzuschließen.
Worin unterscheiden sich GPT-5.2 und GPT-5.1?
Kurz gesagt: GPT‑5.2 ist eine iterative, aber substanzielle Verbesserung. Es behält die Architektur und multimodalen Grundlagen der GPT‑5‑Familie bei, treibt aber vier praktische Dimensionen voran:
- Tiefe und Konsistenz des Reasoning. 5.2 führt höhere Reasoning‑Aufwandsstufen ein und verbessert die Verkettung für mehrstufige Probleme; 5.1 hatte das Reasoning bereits verbessert, aber 5.2 hebt die Decke für komplexe Mathematik und mehrstufige Logik an.
- Langkontext‑Zuverlässigkeit. Beide Versionen haben den Kontext erweitert, aber 5.2 ist darauf abgestimmt, die Genauigkeit tief in sehr langen Eingaben zu halten (OpenAI behauptet verbesserte Retention bis hin zu Hunderttausenden Tokens).
- Vision + multimodale Treue. 5.2 verbessert das Querverknüpfen zwischen Bildern und Text — z. B. das Lesen eines Diagramms und die Integration dieser Daten in eine Tabelle — und zeigt eine höhere Aufgabenebene‑Genauigkeit.
- Agentisches Tool‑Verhalten und API‑Funktionen. 5.2 stellt neue Reasoning‑Aufwandsparameter (
xhigh) und Kontext‑Kompaktionsfunktionen in der API bereit, und OpenAI hat die Routing‑Logik in ChatGPT verfeinert, sodass die UI automatisch die beste Variante auswählen kann. - Weniger Fehler, höhere Stabilität: GPT‑5.2 reduziert seine „Illusionsrate“ (Rate falscher Antworten) um 38%. Es beantwortet Recherche‑, Schreib‑ und Analysefragen zuverlässiger und reduziert Fälle „erfundener Fakten“. Bei komplexen Aufgaben ist sein strukturierter Output klarer und die Logik stabiler. Gleichzeitig ist die Antwortsicherheit des Modells bei Aufgaben rund um psychische Gesundheit deutlich verbessert. In sensiblen Szenarien wie psychischer Gesundheit, Selbstverletzung, Suizid und emotionaler Abhängigkeit arbeitet es robuster.
In System‑Evaluierungen erzielte GPT‑5.2 Instant 0.995 (von 1.0) bei der Aufgabe „Mental Health Support“, deutlich höher als GPT‑5.1 (0.883).
Quantitativ zeigen OpenAIs veröffentlichte Benchmarks messbare Zugewinne auf GDPval, Mathe‑Benchmarks (FrontierMath) und Software‑Engineering‑Evaluationen. GPT‑5.2 übertrifft GPT‑5.1 bei Aufgaben wie Tabellenarbeit im Junior‑Investmentbanking um einige Prozentpunkte.
Ist GPT-5.2 kostenlos — wie viel kostet es?
Kann ich GPT‑5.2 kostenlos nutzen?
OpenAI hat GPT‑5.2 zunächst für bezahlte ChatGPT‑Pläne und API‑Zugriff ausgerollt. Historisch betrachtet behält OpenAI die schnellsten/tiefsten Modelle hinter Bezahltarifen bei, während leichtere Varianten später breiter verfügbar gemacht werden; bei 5.2 sagte das Unternehmen, der Rollout beginne in den Bezahlplänen (Plus, Pro, Business, Enterprise) und die API stehe Entwicklern zur Verfügung. Das bedeutet, dass der sofortige kostenlose Zugriff begrenzt ist: Der Free‑Tier kann später einen reduzierten oder gerouteten Zugriff erhalten (z. B. auf leichtere Subvarianten), wenn OpenAI den Rollout skaliert.
Die gute Nachricht ist, dass CometAPI jetzt mit GPT-5.2 integriert ist und derzeit eine Weihnachtsaktion läuft. Sie können GPT‑5.2 jetzt über CometAPI nutzen; die Playground‑Umgebung erlaubt die freie Interaktion mit GPT‑5.2, und Entwickler können die GPT‑5.2‑API nutzen (CometAPI ist mit 20% des OpenAI‑Preises bepreist), um Workflows zu bauen.
Was kostet es über die API (Entwickler/Produktion)?
Die API‑Nutzung wird pro Token abgerechnet. OpenAIs veröffentlichte Plattformpreise zum Start zeigen (CometAPI ist mit 20% des OpenAI‑Preises bepreist):
- GPT‑5.2 (Standard‑Chat) — $1.75 pro 1M Input‑Tokens und $14 pro 1M Output‑Tokens (Rabatte für gecachte Inputs gelten).
- GPT‑5.2 Pro (Flaggschiff) — $21 pro 1M Input‑Tokens und $168 pro 1M Output‑Tokens (deutlich teurer, da es für hochgenaue, rechenintensive Workloads gedacht ist).
- Zum Vergleich war GPT‑5.1 günstiger (z. B. $1.25 in / $10 out pro 1M Tokens).
Interpretation: Die API‑Kosten sind im Vergleich zu früheren Generationen gestiegen; der Preis signalisiert, dass das Premium‑Reasoning und die Langkontext‑Leistung von 5.2 als eigene Produktstufe bepreist sind. Für Produktionssysteme hängen die Gesamtkosten stark davon ab, wie viele Tokens Sie eingeben/ausgeben und wie oft Sie gecachte Eingaben wiederverwenden (gecachte Inputs erhalten hohe Rabatte).
Was das in der Praxis bedeutet
- Für den gelegentlichen Einsatz über die ChatGPT‑UI sind monatliche Abos (Plus, Pro, Business, Enterprise) der Hauptweg. Die Preise der ChatGPT‑Abostufen haben sich mit dem 5.2‑Release nicht verändert (OpenAI hält die Planpreise stabil, auch wenn sich die Modellangebote ändern).
- Für Produktion & Entwicklung sollten Sie Token‑Kosten einplanen. Wenn Ihre App viele lange Antworten streamt oder lange Dokumente verarbeitet, dominieren die Output‑Token‑Kosten ($14 / 1M Tokens für Thinking) die Ausgaben, sofern Sie Inputs nicht sorgfältig cachen und Outputs wiederverwenden.
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAI brachte GPT‑5.2 mit drei zweckbezogenen Varianten auf den Markt, die zu den Anwendungsfällen passen: Instant, Thinking und Pro:
- GPT‑5.2 Instant: Schnell, kosteneffizient, abgestimmt auf Alltagsarbeit — FAQs, How‑tos, Übersetzungen, schnelle Entwürfe. Niedrige Latenz; gute Erstentwürfe und einfache Workflows.
- GPT‑5.2 Thinking: Tiefere, hochwertigere Antworten für dauerhafte Arbeit — Langdokument‑Zusammenfassungen, mehrstufige Planung, detaillierte Code‑Reviews. Ausgewogene Latenz und Qualität; das Standard‑„Arbeitspferd“ für professionelle Aufgaben.
- GPT‑5.2 Pro: Höchste Qualität und Vertrauenswürdigkeit. Langsamer und teurer; am besten für schwierige, risikoreiche Aufgaben (komplexes Engineering, juristische Synthesen, hochpreisige Entscheidungen) und wenn ein „xhigh“‑Reasoning‑Aufwand erforderlich ist.
Vergleichstabelle
| Feature / Kennzahl | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| Zweck | Alltagstätigkeiten, schnelle Entwürfe | Tiefe Analysen, lange Dokumente | Höchste Qualität, komplexe Probleme |
| Latenz | Am niedrigsten | Moderat | Am höchsten |
| Reasoning‑Aufwand | Standard | Hoch | xHigh verfügbar |
| Am besten geeignet für | FAQ, Tutorials, Übersetzungen, kurze Prompts | Zusammenfassungen, Planung, Tabellen, Coding‑Aufgaben | Komplexes Engineering, juristische Synthese, Forschung |
| API‑Namensbeispiele | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| Input‑Token‑Preis (API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| Output‑Token‑Preis (API) | $14 / 1M | $14 / 1M | $168 / 1M |
| Verfügbarkeit (ChatGPT) | Rollout; Bezahlpläne, dann breiter | Rollout für Bezahlpläne | Pro‑Nutzer:innen / Enterprise (bezahlt) |
| Typischer Anwendungsfall | E‑Mail‑Entwurf, kleine Code‑Snippets | Mehrblatt‑Finanzmodell bauen, langes Bericht‑Q&A | Codebase auditieren, produktionsreifes Systemdesign erzeugen |
Für wen eignet sich GPT-5.2?
GPT‑5.2 ist für eine breite Zielgruppe gedacht. Im Folgenden rollenbasierte Empfehlungen:
Unternehmen & Produktteams
Wenn Sie Produkte für Wissensarbeit bauen (Research‑Assistenten, Vertragsprüfung, Analyse‑Pipelines oder Entwickler‑Tools), können GPT‑5.2s Langkontext‑ und agentische Fähigkeiten die Integrationskomplexität deutlich reduzieren. Unternehmen, die robustes Dokumentverständnis, automatisiertes Reporting oder intelligente Copilots benötigen, werden Thinking/Pro nützlich finden. Microsoft und andere Plattformpartner integrieren 5.2 bereits in Produktivitäts‑Stacks (z. B. Microsoft 365 Copilot).
Entwickler‑ und Engineering‑Teams
Teams, die LLMs als Pair‑Programmierer nutzen oder Code‑Generierung/Testing automatisieren möchten, profitieren von der verbesserten Programmier‑Treue in 5.2. API‑Zugriff (mit thinking‑ oder pro‑Modi) ermöglicht tiefere Synthesen großer Codebasen dank des 400k‑Token‑Kontextfensters. Rechnen Sie bei der API mit höheren Kosten, wenn Sie Pro verwenden, aber die Reduktion manueller Debugging‑ und Review‑Aufwände kann sich bei komplexen Systemen lohnen.
Forschende und datenintensive Analyst:innen
Wenn Sie regelmäßig Literatur synthetisieren, lange technische Berichte parsen oder modellgestütztes Versuchsdesign wollen, helfen die Langkontext‑ und Mathe‑Verbesserungen von GPT‑5.2, Workflows zu beschleunigen. Für reproduzierbare Forschung koppeln Sie das Modell mit sorgfältigem Prompt‑Engineering und Verifikationsschritten.
Kleine Unternehmen und Power‑User
ChatGPT Plus (und Pro für Power‑User) erhält gerouteten Zugriff auf 5.2‑Varianten; dadurch werden fortgeschrittene Automatisierung und hochwertige Outputs für kleinere Teams erreichbar, ohne eine API‑Integration zu bauen. Für nicht‑technische Nutzer:innen, die bessere Dokumentzusammenfassungen oder Foliensätze benötigen, liefert GPT‑5.2 spürbaren praktischen Mehrwert.
Praktische Hinweise für Entwickler und Betreiber
API‑Funktionen im Blick
reasoning.effort‑Stufen (z. B.medium,high,xhigh) erlauben es, dem Modell vorzugeben, wie viel Compute für internes Reasoning aufzuwenden ist; nutzen Sie dies, um Latenz gegen Genauigkeit pro Anfrage abzuwägen.- Kontext‑Kompaktion: Die API enthält Tools, um den Verlauf zu komprimieren und zu verdichten, sodass wirklich relevante Inhalte für lange Ketten erhalten bleiben. Das ist entscheidend, um die effektive Token‑Nutzung handhabbar zu halten.
- Tool‑Scaffolding & Allowed‑Tools‑Kontrollen: Produktionssysteme sollten explizit whitelisten, was das Modell aufrufen darf, und Tool‑Aufrufe für Audits protokollieren.
Tipps zur Kostenkontrolle
- Häufig genutzte Dokument‑Embeddings cachen und gecachte Inputs (die kräftige Rabatte erhalten) für wiederholte Anfragen gegen denselben Korpus verwenden. OpenAIs Plattformpreise enthalten erhebliche Rabatte für gecachte Inputs.
- Explorative/niedrigwertige Anfragen an Instant routen und Thinking/Pro für Batch‑Jobs oder finale Durchgänge reservieren.
- Token‑Nutzung (Input + Output) bei der Planung der API‑Kosten sorgfältig schätzen, da lange Outputs die Kosten vervielfachen.
Fazit — sollten Sie auf GPT-5.2 upgraden?
Wenn Ihre Arbeit von Langdokument‑Reasoning, dokumentübergreifender Synthese, multimodaler Interpretation (Bilder + Text) oder dem Bau von Agenten abhängt, die Tools aufrufen, ist GPT‑5.2 ein klarer Schritt nach vorn: Es erhöht die praktische Genauigkeit und reduziert manuellen Integrationsaufwand. Wenn Sie hauptsächlich hochvolumige, latenzkritische Chatbots betreiben oder streng budgetierte Anwendungen, können Instant (oder frühere Modelle) weiterhin eine vernünftige Wahl sein.
GPT‑5.2 markiert eine bewusste Verschiebung von „besserer Chat“ zu „besserer professioneller Assistent“: mehr Compute, mehr Fähigkeit und höhere Preisstufen — aber auch echte Produktivitätsgewinne für Teams, die zuverlässigen Langkontext, verbessertes Mathe/Reasoning, Bildverständnis und agentische Tool‑Ausführung nutzen können.
Los geht’s: Erkunden Sie die Fähigkeiten der GPT‑5.2‑Modelle(GPT-5.2;GPT-5.2 pro, GPT-5.2 chat ) im Playground und konsultieren Sie den API-Leitfaden für detaillierte Anleitungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und einen API‑Schlüssel erhalten haben. CometAPI bietet einen deutlich niedrigeren Preis als der offizielle, um Ihnen die Integration zu erleichtern.
Bereit? → Kostenlose Testversion der gpt-5.2-Modelle !