

GPT-5-Codex ist OpenAIs neue, entwicklungsorientierte Variante von GPT-5, die speziell für die agentenbasierte Softwareentwicklung innerhalb der Codex-Produktfamilie optimiert wurde. Es ist für umfangreiche Entwicklungs-Workflows in der Praxis konzipiert: Erstellung kompletter Projekte von Grund auf, Hinzufügen von Funktionen und Tests, Debugging, Refactoring und Durchführung von Code-Reviews bei gleichzeitiger Interaktion mit externen Tools und Test-Suites. Diese Version stellt eher eine gezielte Produktverbesserung als ein brandneues Basismodell dar: OpenAI hat GPT-5-Codex in Codex CLI, die Codex IDE-Erweiterung, Codex Cloud, GitHub-Workflows und ChatGPT-Mobilfunktionen integriert; die API-Verfügbarkeit ist geplant, aber nicht sofort verfügbar.
Was ist GPT-5-Codex – und warum existiert es?
GPT-5-Codex ist GPT-5, „spezialisiert auf Programmierung“. Anstatt ein allgemeiner Konversationsassistent zu sein, wird es mit Reinforcement Learning und ingenieurspezifischen Datensätzen optimiert und trainiert, um iterative, toolgestützte Programmieraufgaben (z. B. Tests durchführen, Fehler iterieren, Module refaktorieren und PR-Konventionen einhalten) besser zu unterstützen. OpenAI sieht es als Nachfolger früherer Codex-Bemühungen, baut aber auf dem GPT-5-Backbone auf, um die Argumentationstiefe bei großen Codebasen zu verbessern und mehrstufige Entwicklungsaufgaben zuverlässiger auszuführen.
Die Motivation ist praktischer Natur: Entwickler-Workflows basieren zunehmend auf Agenten, die mehr können als nur einzelne Snippet-Vorschläge. Durch die gezielte Ausrichtung eines Modells auf den Kreislauf „Generieren → Tests ausführen → Reparieren → Wiederholen“ und auf organisatorische PR-Normen zielt OpenAI darauf ab, eine KI zu schaffen, die sich wie ein Teammitglied anfühlt und nicht wie eine Quelle einmaliger Vervollständigungen. Dieser Wechsel von „Funktion generieren“ zu „Feature ausliefern“ macht den einzigartigen Wert des Modells aus.
Wie ist GPT-5-Codex aufgebaut und trainiert?
Architektur auf hoher Ebene
GPT-5-Codex ist eine Variante der GPT-5-Architektur (der breiteren GPT-5-Linie) und keine von Grund auf neue Architektur. Das bedeutet, dass es das transformatorbasierte Kerndesign, die Skalierungseigenschaften und die verbesserten Argumentationsfähigkeiten von GPT-5 übernimmt, aber Codex-spezifisches Training und RL-basierte Feinabstimmung speziell für Softwareentwicklungsaufgaben hinzufügt. Der Nachtrag von OpenAI beschreibt GPT-5-Codex als an komplexen, realen Entwicklungsaufgaben trainiert und betont das bestärkende Lernen in Umgebungen, in denen Code ausgeführt und validiert wird.
Wie wurde es für Code trainiert und optimiert?
Das Trainingsprogramm von GPT-5-Codex betont reale Ingenieuraufgaben. Es nutzt eine Feinabstimmung im Stil des bestärkenden Lernens für Datensätze und Umgebungen, die aus konkreten Softwareentwicklungs-Workflows erstellt wurden: Multi-File-Refactoring, PR-Diffs, laufende Test-Suites, Debugging-Sitzungen und menschliche Prüfsignale. Das Trainingsziel besteht darin, die Korrektheit aller Code-Änderungen zu maximieren, Tests zu bestehen und Prüfkommentare mit hoher Präzision und Relevanz zu erstellen. Dieser Fokus unterscheidet Codex von allgemeiner, chatorientierter Feinabstimmung: Die Verlustfunktionen, Bewertungsmechanismen und Belohnungssignale sind auf die Entwicklungsergebnisse ausgerichtet (bestandene Tests, korrekte Diffs, weniger fehlerhafte Kommentare).
So sieht „agentisches“ Training aus
- Ausführungsorientierte Feinabstimmung: Das Modell wird in Kontexten trainiert, in denen generierter Code ausgeführt, getestet und ausgewertet wird. Feedbackschleifen ergeben sich aus Testergebnissen und menschlichen Präferenzsignalen und regen das Modell dazu an, so lange zu iterieren, bis eine Testsuite erfolgreich ist.
- Reinforcement Learning aus menschlichem Feedback (RLHF): Im Prinzip ähnlich wie frühere RLHF-Arbeiten, aber auf mehrstufige Codierungsaufgaben angewendet (PR erstellen, Tests ausführen, Fehler beheben), sodass das Modell die zeitliche Kreditzuweisung über eine Abfolge von Aktionen lernt.
- Kontext im Repository-Maßstab: Training und Evaluierung umfassen große Repositories und Refactorings, die dem Modell helfen, dateiübergreifendes Denken, Namenskonventionen und Auswirkungen auf Codebasisebene zu erlernen. ()
Wie handhabt GPT-5-Codex die Verwendung von Tools und Umgebungsinteraktionen?
Ein zentrales Architekturmerkmal ist die verbesserte Fähigkeit des Modells, Tools aufzurufen und zu koordinieren. Codex kombinierte Modellausgaben bisher mit einem kleinen Laufzeit-/Agentensystem, das Tests ausführen, Dateien öffnen oder Suchvorgänge aufrufen konnte. GPT-5-Codex erweitert dies, indem es lernt, wann Tools aufgerufen werden müssen, und Testfeedback besser in die nachfolgende Codegenerierung integriert – wodurch der Kreis zwischen Synthese und Verifizierung effektiv geschlossen wird. Dies wird durch Training auf Trajektorien erreicht, bei denen das Modell sowohl Aktionen ausgibt (wie „Test X ausführen“) als auch spätere Generierungen anhand von Testausgaben und Diffs konditioniert.
Was kann GPT-5-Codex eigentlich – was sind seine Funktionen?
Eine der entscheidenden Produktinnovationen ist adaptive DenkdauerGPT-5-Codex passt die Menge der durchgeführten versteckten Schlussfolgerungen an: Triviale Anfragen werden schnell und kostengünstig ausgeführt, während komplexe Refactorings oder lang andauernde Aufgaben dem Modell ermöglichen, viel länger zu „denken“. Gleichzeitig verbraucht das Modell für kleine, interaktive Runden weit weniger Token als eine allgemeine GPT-5-Instanz und spart 93.7 % der Token (einschließlich Inferenz und Ausgabe) im Vergleich zu GPT-5. Diese variable Schlussfolgerungsstrategie soll bei Bedarf schnelle Antworten und bei Bedarf eine gründliche, gründliche Ausführung ermöglichen.
Kernkompetenzen
- Projektgenerierung und Bootstrapping: Erstellen Sie komplette Projektskelette mit CI, Tests und grundlegender Dokumentation anhand von Eingabeaufforderungen auf hoher Ebene.
- Agententests und Iteration: Code generieren, Tests ausführen, Fehler analysieren, Code patchen und erneut ausführen, bis die Tests erfolgreich sind – und so Teile der Schleife „Bearbeiten → Testen → Korrigieren“ eines Entwicklers effektiv automatisieren.
- Umfassendes Refactoring: Führen Sie systematische Refactorings für viele Dateien durch, während Verhalten und Tests beibehalten werden. Dies ist ein definierter Optimierungsbereich für GPT-5-Codex im Vergleich zu generischem GPT-5.
- Codeüberprüfung und PR-Generierung: Erstellen Sie PR-Beschreibungen, Änderungsvorschläge mit Unterschieden und Überprüfungskommentare, die den Projektkonventionen und den Erwartungen an die menschliche Überprüfung entsprechen.
- Code-Argumentation im großen Kontext: Bessere Navigation und Argumentation bei Codebasen mit mehreren Dateien, Abhängigkeitsdiagrammen und API-Grenzen im Vergleich zu generischen Chatmodellen.
- Visuelle Ein- und Ausgänge: Bei der Arbeit in der Cloud kann GPT-5-Codex Bilder/Screenshots akzeptieren, den Fortschritt visuell überprüfen und visuelle Artefakte (Screenshots der erstellten Benutzeroberfläche) an Aufgaben anhängen – ein praktischer Segen für das Front-End-Debugging und visuelle QA-Workflows.
Editor- und Workflow-Integrationen
Codex ist tief in die Arbeitsabläufe der Entwickler integriert:
- CLI-Kodex – Terminal-First-Interaktion, unterstützt Screenshots, Aufgabenverfolgung und Agentengenehmigungen. Die CLI ist Open Source und auf agentenbasierte Codierungs-Workflows abgestimmt.
- Codex IDE-Erweiterung – bettet den Agenten in VS Code (und Forks) ein, sodass Sie lokale Unterschiede in der Vorschau anzeigen, Cloud-Aufgaben erstellen und Arbeit mit erhaltenem Status zwischen Cloud- und lokalen Kontexten verschieben können.
- Codex Cloud / GitHub – Cloud-Aufgaben können so konfiguriert werden, dass PRs automatisch überprüft, temporäre Container zum Testen erstellt und Aufgabenprotokolle und Screenshots an PR-Threads angehängt werden.
Bemerkenswerte Einschränkungen und Kompromisse
- Enge Optimierung: Einige nicht-codierende Produktionsauswertungen sind für GPT-5-Codex etwas niedriger als für die allgemeine GPT-5-Variante – eine Erinnerung daran, dass Spezialisierung auf Kosten der Allgemeingültigkeit gehen kann.
- Testverlässlichkeit: Das Verhalten von Agenten hängt von verfügbaren automatisierten Tests ab. Codebasen mit unzureichender Testabdeckung weisen Grenzen bei der automatischen Überprüfung auf und erfordern möglicherweise menschliche Überwachung.
Für welche Aufgaben ist GPT-5-Codex besonders gut oder schlecht geeignet?
Gut in: komplexe Refactorings, Erstellen von Gerüsten für große Projekte, Schreiben und Korrigieren von Tests, Befolgen von PR-Erwartungen und Diagnostizieren von Laufzeitproblemen mit mehreren Dateien.
Weniger gut in: Aufgaben, die aktuelles oder proprietäres internes Wissen erfordern, das im Arbeitsbereich nicht vorhanden ist, oder solche, die eine hohe Korrektheitsgarantie ohne menschliche Überprüfung erfordern (sicherheitskritische Systeme benötigen weiterhin Experten). Unabhängige Überprüfungen zeichnen auch ein gemischtes Bild hinsichtlich der Rohcodequalität im Vergleich zu anderen spezialisierten Codierungsmodellen – Stärken in agentenbasierten Workflows lassen sich nicht bei jedem Benchmark einheitlich in erstklassiger Korrektheit umsetzen.
Was verraten Benchmarks über die Leistung von GPT-5-Codex?
SWE-bench / SWE-bench Verifiziert: OpenAI gibt an, dass GPT-5-Codex GPT-5 bei agentenbasierten Coding-Benchmarks wie SWE-bench Verified übertrifft und bei Code-Refactoring-Aufgaben aus großen Repositories Fortschritte zeigt. Im SWE-bench Verified-Datensatz, der 500 reale Softwareentwicklungsaufgaben enthält, erreichte GPT-5-Codex eine Erfolgsquote von 74.5 %. Dies übertrifft die 5 % von GPT-72.8 im gleichen Benchmark und unterstreicht die verbesserten Fähigkeiten des Agenten. 500 Programmieraufgaben aus echten Open-Source-Projekten. Zuvor konnten nur 477 Aufgaben getestet werden, jetzt können alle 500 Aufgaben getestet werden → vollständigere Ergebnisse.
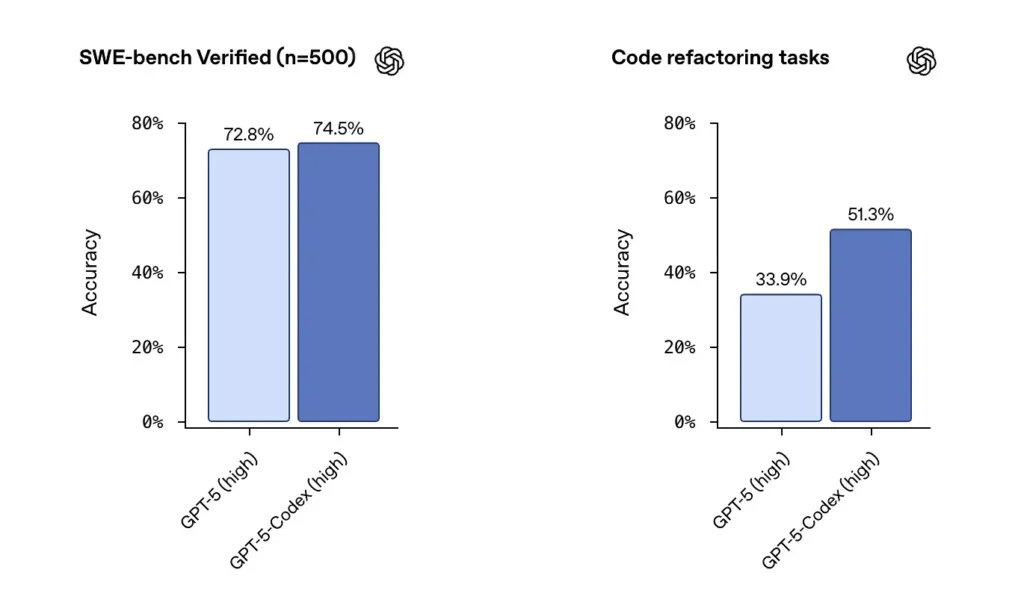
von früheren GPT-5-Einstellungen zu GPT-5-Codex haben sich die Bewertungsergebnisse für die Code-Refaktorierung deutlich verbessert – Zahlen wie die Verschiebung von ~34 % auf ~51 % bei einer bestimmten Refaktorierungsmetrik mit hoher Ausführlichkeit wurden in frühen Analysen hervorgehoben. Diese Zuwächse sind insofern bedeutsam, als sie Verbesserungen bei große, realistische Refactorings Es handelt sich dabei nicht um Spielzeugbeispiele, sondern um Beispiele, aber es bleiben Vorbehalte hinsichtlich der Reproduzierbarkeit und des genauen Test-Harnesses.
Wie können Entwickler und Teams auf GPT-5-Codex zugreifen?
OpenAI hat GPT-5-Codex in die Codex-Produktoberflächen integriert: Es ist überall dort verfügbar, wo Codex heute läuft (z. B. in der Codex-CLI und integrierten Codex-Erlebnissen). Für Entwickler, die Codex über die CLI und die ChatGPT-Anmeldung verwenden, wird das aktualisierte Codex-Erlebnis das GPT-5-Codex-Modell anzeigen. OpenAI hat angekündigt, dass das Modell „bald“ in der erweiterten API für Benutzer von API-Schlüsseln verfügbar sein wird. Zum ersten Rollout erfolgt der primäre Zugriffspfad jedoch über Codex-Tools und nicht über einen öffentlichen API-Endpunkt.
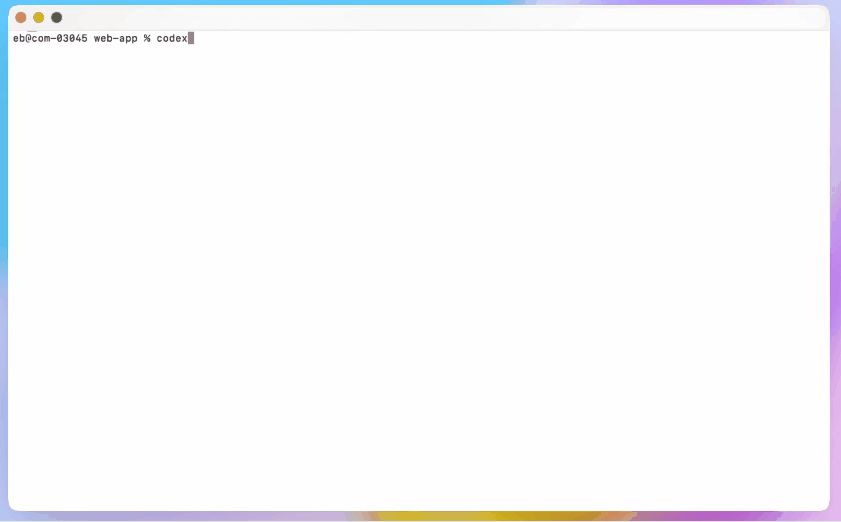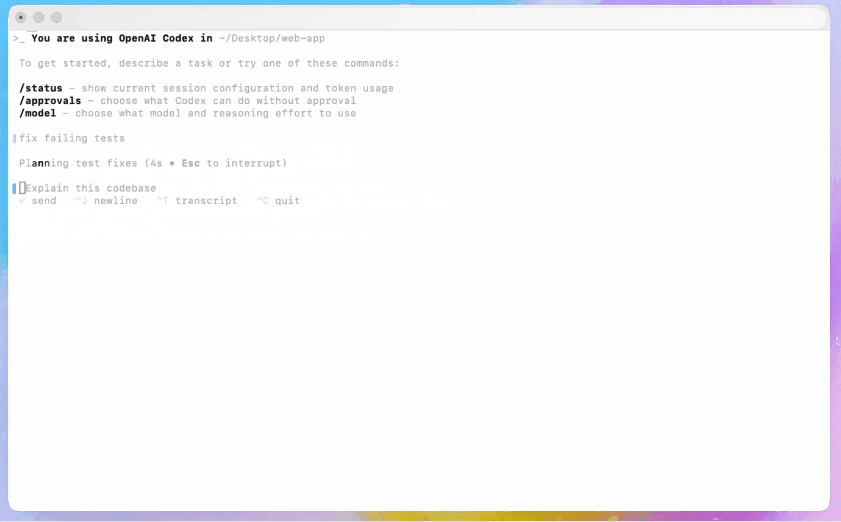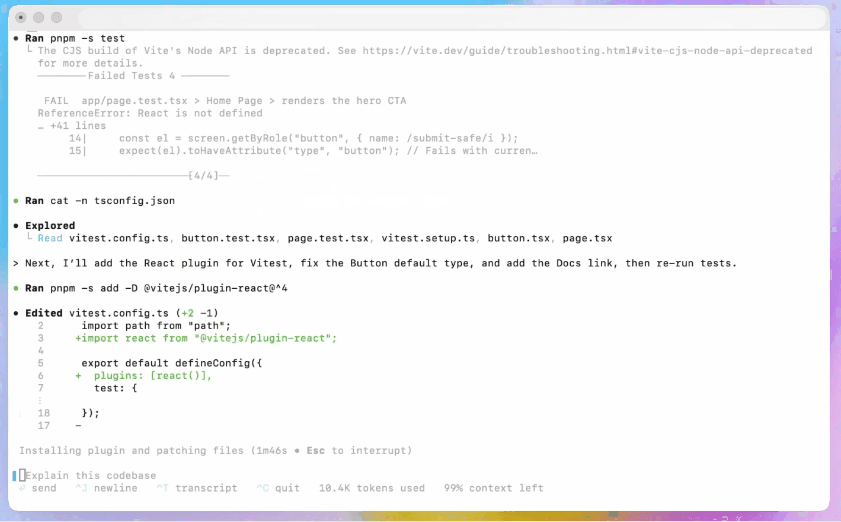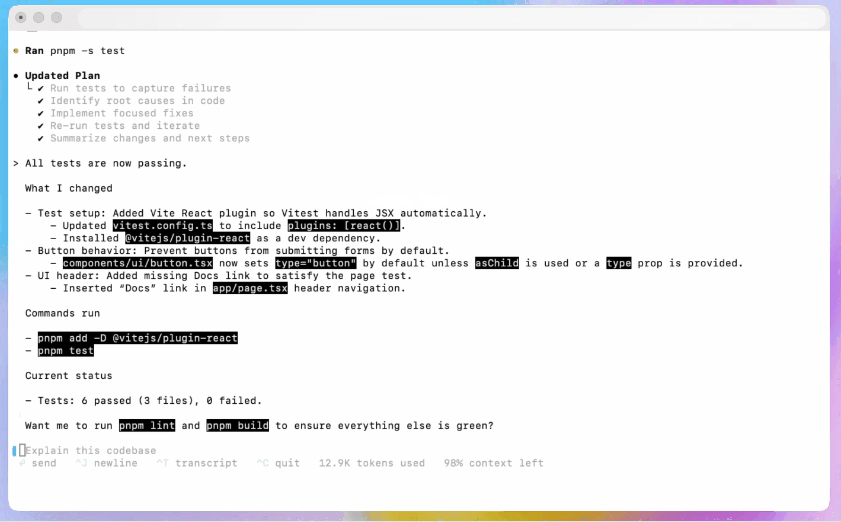
CLI-Kodex
Aktivieren Sie Codex, um PR-Entwürfe in einem Sandbox-Repository zu überprüfen, damit Sie die Kommentarqualität ohne Risiko beurteilen können. Verwenden Sie die Genehmigungsmodi zurückhaltend.
- Neu gestaltet um einen agentenbasierten Codierungsworkflow.
- Die Unterstützung für das Anhängen von Bildern (wie Drahtmodelle, Designs und Screenshots von UI-Fehlern) bietet Kontext für Modelle.
- Eine Aufgabenlistenfunktion wurde hinzugefügt, um den Fortschritt komplexer Aufgaben zu verfolgen.
- Bietet Unterstützung für externe Tools (Websuche, MCP-Verbindung).
- Die neue Terminalschnittstelle verbessert den Toolaufruf und die Diff-Formatierung und der Berechtigungsmodus wurde auf drei Ebenen vereinfacht (schreibgeschützt, automatisch und Vollzugriff).
IDE-Erweiterung
In IDE-Workflows integrieren: Fügen Sie die Codex IDE-Erweiterung für Entwickler hinzu, die Inline-Vorschauen und schnellere Iterationen wünschen. Das Verschieben von Aufgaben zwischen Cloud und lokal mit erhaltenem Kontext kann die Reibung bei komplexen Funktionen reduzieren.
- Unterstützt VS Code, Cursor und mehr.
- Rufen Sie Codex direkt aus dem Editor auf, um den Kontext der aktuell geöffneten Datei und des Codes für genauere Ergebnisse zu nutzen.
- Wechseln Sie nahtlos zwischen Aufgaben zwischen lokalen und Cloud-Umgebungen und bewahren Sie dabei die kontextuelle Kontinuität.
- Zeigen Sie die Ergebnisse von Cloud-Aufgaben direkt im Editor an und arbeiten Sie damit, ohne die Plattform wechseln zu müssen.
GitHub-Integration und Cloud-Funktionen
- Automatisierte PR-Überprüfung: Löst automatisch den Fortschritt vom Entwurf bis zur Fertigstellung aus.
- Unterstützt Entwickler dabei, gezielte Überprüfungen direkt im @codex-Abschnitt eines PR anzufordern.
- Deutlich schnellere Cloud-Infrastruktur: Reduzieren Sie die Antwortzeiten von Aufgaben durch Container-Caching um 90 %.
- Automatisierte Umgebungskonfiguration: Führt Setup-Skripte aus und installiert Abhängigkeiten (z. B. Pip-Installation).
- Führt automatisch einen Browser aus, überprüft Front-End-Implementierungen und hängt Screenshots an Aufgaben oder PRs an.

Welche Sicherheits- und Begrenzungsaspekte gibt es?
OpenAI legt Wert auf mehrere Schadensminderungsebenen für Codex-Agenten:
- Training auf Modellebene: gezieltes Sicherheitstraining, um sofortigen Injektionen zu widerstehen und schädliches oder risikoreiches Verhalten einzuschränken.
- Kontrollen auf Produktebene: Sandbox-Standardverhalten, konfigurierbarer Netzwerkzugriff, Genehmigungsmodi für laufende Befehle, Terminalprotokolle und Zitate zur Rückverfolgbarkeit sowie die Möglichkeit, menschliche Genehmigungen für sensible Aktionen anzufordern. OpenAI hat außerdem einen „Systemkarten-Nachtrag“ veröffentlicht, der diese Abhilfemaßnahmen und ihre Risikobewertungen beschreibt, insbesondere für biologische und chemische Domänenfunktionen.
Diese Kontrollen spiegeln die Tatsache wider, dass ein Agent, der Befehle ausführen und Abhängigkeiten installieren kann, in der realen Welt eine Angriffsfläche und ein Risiko aufweist. Der Ansatz von OpenAI besteht darin, Modelltraining mit Produktbeschränkungen zu kombinieren, um Missbrauch zu begrenzen.
Welche Einschränkungen sind bekannt?
- Kein Ersatz für menschliche Gutachter: OpenAI empfiehlt Codex ausdrücklich als zusätzlich Prüfer, kein Ersatz. Menschliche Aufsicht bleibt entscheidend, insbesondere bei Entscheidungen zu Sicherheit, Lizenzierung und Architektur.
- Benchmarks und Behauptungen müssen sorgfältig gelesen werden: Gutachter haben beim Vergleich der Modelle auf Unterschiede bei den Bewertungsteilmengen, den Ausführlichkeitseinstellungen und den Kostenabwägungen hingewiesen. Erste unabhängige Tests deuten auf gemischte Ergebnisse hin: Codex zeigt ein starkes Agentenverhalten und Verbesserungen beim Refactoring, aber die relative Genauigkeit im Vergleich zu anderen Anbietern variiert je nach Benchmark und Konfiguration.
- Halluzinationen und unzuverlässiges Verhalten: Wie alle LLMs kann Codex halluzinieren (URLs erfinden, Abhängigkeitsdiagramme falsch darstellen), und seine mehrstündigen Agentenläufe können in Grenzfällen immer noch brüchig sein. Rechnen Sie damit, die Ergebnisse durch Tests und menschliche Überprüfung zu validieren.
Welche umfassenderen Auswirkungen hat dies auf die Softwareentwicklung?
GPT-5-Codex zeigt einen reifenden Wandel im LLM-Design: Anstatt nur die nackten Sprachfähigkeiten zu verbessern, optimieren die Anbieter Verhalten für lange, agentenbasierte Aufgaben (mehrstündige Ausführung, testgetriebene Entwicklung, integrierte Review-Pipelines). Dadurch ändert sich die Produktivitätseinheit von einem einzelnen generierten Snippet zu Aufgabenerledigung – die Fähigkeit des Modells, ein Ticket zu übernehmen, eine Reihe von Tests durchzuführen und iterativ eine validierte Implementierung zu erstellen. Wenn diese Agenten robust und gut gesteuert werden, werden sie Arbeitsabläufe verändern (weniger manuelle Refactorings, schnellere PR-Zyklen, Entwickler können sich auf Design und Strategie konzentrieren). Der Übergang erfordert jedoch sorgfältige Prozessgestaltung, menschliche Kontrolle und Sicherheits-Governance.
Fazit – Was sollten Sie mitnehmen?
GPT-5-Codex ist ein gezielter Schritt in Richtung Ingenieurqualität LLMs: Eine GPT-5-Variante, die trainiert, optimiert und als leistungsfähiger Programmieragent im Codex-Ökosystem eingesetzt wird. Sie bietet greifbare neue Funktionen – adaptive Denkzeit, lange autonome Läufe, integrierte Sandbox-Ausführung und gezielte Verbesserungen bei der Codeüberprüfung – und behält dabei die bekannten Einschränkungen von Sprachmodellen bei (Notwendigkeit menschlicher Kontrolle, Nuancen in der Bewertung und gelegentliche Halluzinationen). Für Teams ist maßvolles Experimentieren der beste Weg: Pilotierung in sicheren Repositorien, Überwachung der Ergebnismetriken und schrittweise Einbindung des Agenten in die Prüfer-Workflows. Mit dem Ausbau des API-Zugriffs durch OpenAI und der zunehmenden Verbreitung von Benchmarks von Drittanbietern sind klarere Vergleiche und konkretere Leitlinien zu Kosten, Genauigkeit und Best-Practice-Governance zu erwarten.
Erste Schritte
CometAPI ist eine einheitliche API-Plattform, die über 500 KI-Modelle führender Anbieter – wie die GPT-Reihe von OpenAI, Google Gemini, Claude von Anthropic, Midjourney, Suno und weitere – in einer einzigen, entwicklerfreundlichen Oberfläche vereint. Durch konsistente Authentifizierung, Anforderungsformatierung und Antwortverarbeitung vereinfacht CometAPI die Integration von KI-Funktionen in Ihre Anwendungen erheblich. Ob Sie Chatbots, Bildgeneratoren, Musikkomponisten oder datengesteuerte Analyse-Pipelines entwickeln – CometAPI ermöglicht Ihnen schnellere Iterationen, Kostenkontrolle und Herstellerunabhängigkeit – und gleichzeitig die neuesten Erkenntnisse des KI-Ökosystems zu nutzen.
Entwickler können zugreifen GPT-5-Codex-API Die neuesten Modelle der CometAPI sind zum Veröffentlichungsdatum des Artikels aufgeführt. Melden Sie sich vor dem Zugriff bei CometAPI an und erhalten Sie den API-Schlüssel.