

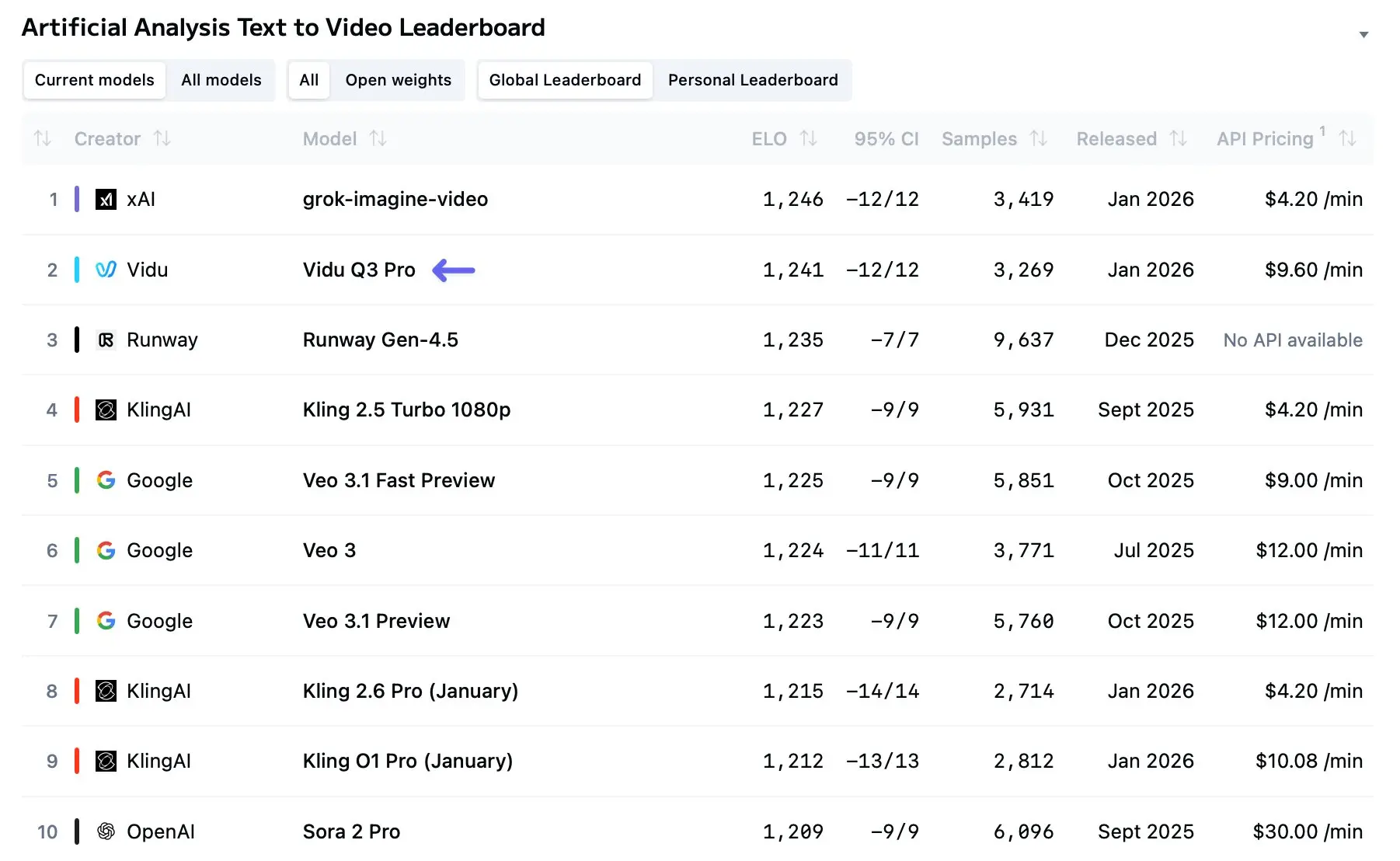
Vidu Q3 trat Anfang 2026 in die Diskussion ein als eines der bislang klarsten Signale dafür, dass KI-gestützte Videogenerierung sich von kurzen, neuartigen Clips hin zu echten Erzählungen mit mehreren Einstellungen entwickelt. In den Monaten seit der breiten Veröffentlichung ist Vidu Q3 zu einem festen Bestandteil in Creator-Workflows, Forschungspiloten und kommerziellen Piloten geworden — und das aus gutem Grund: Es treibt Dauer, audiovisuelle Integration und Mehrfachaufnahme-Kohärenz weiter voran als die meisten früheren Modelle und bietet gleichzeitig eine entwicklerorientierte API für die programmgesteuerte Nutzung.
Was ist Vidu Q3?
Vidu Q3 ist die neueste Flaggschiff-Iteration der Large Video Model (LVM)-Architektur von ShengShu Technology. Anders als seine Vorgänger (Vidu 1.0 und 1.5), die separate Workflows für die visuelle Generierung und die Audiopostproduktion erforderten, ist Vidu Q3 eine „All-in-one“-generative Engine.
Der zentrale Durchbruch von Vidu Q3 ist die Fähigkeit, hochauflösende Visuals und hochqualitatives Audio gleichzeitig zu erzeugen.[ Durch das gemeinsame Verständnis der Physik von Schall und Licht beseitigt das Modell das „Uncanny Valley“ des desynchronisierten Audios, das bei Konkurrenzmodellen häufig zu sehen ist. Es unterstützt bis zu 16 Sekunden kontinuierliche Generierung in nativer 1080p-Auflösung und positioniert sich damit als produktionsreifes Tool für Kurzfilme, Werbespots und narratives Storytelling.
Wie funktioniert Vidu Q3 unter der Haube?
Während die Kerndetails der Architektur proprietär sind, baut Vidu auf der U-ViT-Fusion aus Diffusionsmodellen und Transformern auf — ein Design, das für das Gleichgewicht aus Kohärenz, zeitlicher Kontinuität und Ausdrucksstärke in der Videogenerierung bekannt ist.
Diese hybride Architektur ermöglicht es dem Modell, über längere Sequenzen hinweg über Bewegung, Klang und narrativen Kontext zu „schließen“.
6 herausragende Funktionen von Vidu Q3
1. Generierung mit verlängerter Dauer — wie lang kann es werden?
Eines der Aushängeschilder von Vidu Q3 ist die längere Dauer pro Einzelgenerierung. Viele frühere Generationsmodelle konzentrierten sich auf Mikroclips; Q3 verlängert die Clip-Länge bewusst, um einfache Handlungsbögen und Sequenzen mit mehreren Einstellungen zu ermöglichen, ohne Creators zu zwingen, viele winzige Clips zusammenzuschneiden. Plattformdokumentationen und Partnerportale werben mit bis zu ~16 Sekunden nativer Generierung in einem Durchlauf (Format- und Qualitätsoptionen können je nach Anbieter und API-Plan variieren). Das ist wichtig, denn der Sprung von 4–8 Sekunden auf 16 Sekunden verändert, wie Szenen geplant, Beats geschrieben und Audio-Cues getaktet werden.
2. Visuelle Wiedergabetreue und zeitliche Kohärenz
Unabhängige Bewertungen und frühe Benchmarks zeigen, dass Vidu Q3 klarere Bilder und weniger Verzerrungen auf Frame-Ebene liefert als frühere Consumer-Modelle. Verbesserungen in der Architektur und Datenaugmentation scheinen Flimmern zu reduzieren und die Bewegungskontinuität für Clips unter 10–16 Sekunden zu verbessern. Das Modell kann jedoch weiterhin mit dichten Szenen mit vielen Motiven (Menschenmengen, komplexe physische Interaktionen) ringen, bei denen Okklusion und feine Bewegungen starkes physikalisches Verständnis erfordern. Vergleichsportale und Modell-Bestenlisten haben Vidu Q3 bereits weit oben in T2V-Listen (Text-zu-Video) platziert, auch wenn die Platzierungen je nach Benchmark und Datensatz variieren.
3. Native Audio- und Videogenerierung
Im Gegensatz zu Systemen, die stumme Visuals erzeugen und Audio der Postproduktion überlassen, integriert Vidu Q3 die Audiogenerierung im Modell. Das Ergebnis sind lippensynchroner Dialog, getimte SFX und optionale Hintergrundmusik, die parallel zu den Frames produziert werden. Die Integration von Klang auf Modellebene reduziert Ausrichtungsfehler (Lip-Sync-Drift, Offbeat-Cues) und verkürzt den Produktionszyklus für Demos, Previews und viele fertige Kurzformate.
4. Intelligente Kamerasteuerung und Multi-Shot-Narrative
Die „Smart-Camera“-Funktionen von Q3 interpretieren Prompts für Kamerabewegungen (Pan, Dolly, Tracking) und Sequenzen mit mehreren Einstellungen. Anstatt einen einzelnen statischen Blickwinkel zu produzieren, kann das Modell geplante Schnitte und Übergänge erzeugen, sodass der resultierende Clip wie eine inszenierte Szene wirkt. Für Creators wandelt sich die Ausgabe von „ein einzelnes komponiertes Bild, das sich bewegt“ zu „eine kurze Szene mit mehreren Einstellungen“. Das verbessert die Sehbarkeit und ermöglicht reichhaltigeres visuelles Erzählen in einer einzigen Generierung.
5. Mehrfachreferenz-Konsistenz und Charaktertreue
Vidu (als Plattform) hat in „Reference to Video“- und Mehrfachreferenz-Konsistenzsysteme investiert, die es Creators erlauben, mehrere Referenzbilder hochzuladen, um die Charakteridentität über Frames hinweg zu fixieren. Q3 erweitert diese Ansätze, um das Erscheinungsbild von Charakteren und Requisiten über mehrere Kamerawinkel und Schnitte hinweg konsistent zu halten — eine grundlegende, aber wesentliche Voraussetzung für kohärente narrative Ausgaben. Das ist besonders nützlich für Anime- oder stilisierte Projekte, bei denen konsistente Charakterzeichnung entscheidend ist.
6. Entwicklerreife: APIs und Workflow
Die Vidu-Modellsuite — einschließlich Q3 — ist über Web-UIs und eine programmgesteuerte REST-API verfügbar. Entwickler können Text-zu-Video- oder Bild-plus-Text-Jobs an einen Inferenz-Endpunkt senden, eine Task-ID erhalten und die Ergebnisse abfragen (typisches asynchrones Job-Muster). Die API bietet Parameter wie Auflösung, Seitenverhältnis, Dauer, Bewegungsamplitude und einen Schalter für die Audiogenerierung. Damit ist Q3 für Automatisierung, Batch-Workflows und die Integration in Redaktions-Pipelines zugänglich.
Wie schneidet Vidu Q3 im Vergleich zu Sora 2 und Veo 3.1 ab?
Kurzfassung: Vidu Q3 konkurriert stark bei längeren narrativen Ausgaben und integrierter Audio/Video-Erzeugung für 10–20-sekündige Szenen, Sora 2 glänzt bei physikalisch plausibler Einzelaufnahme-Realität und Social-Integration, und Veo 3.1 führt bei Pixel-Polish, Tools für Mehrframe-Kontinuität und Enterprise-API-Integration. Nachfolgend erläutern wir die Unterschiede entlang praktischer Achsen.
Welches Modell ist stärker bei Realismus und Physik: Sora 2 oder Vidu Q3?
Sora 2 (OpenAI) wurde explizit auf physikalische Plausibilität und Weltsimulation trainiert — öffentliche Hinweise heben fortgeschrittenes Physikverhalten, genaue Objektinteraktionen und hochrealistische Bewegungsbahnen hervor. Sora 2 bietet zudem synchronisiertes Audio und Social-App-Integrationen (einschließlich Cameos und einer mobilen App) und ist damit außergewöhnlich stark für lebensechte, physikalisch kohärente Szenen. Wenn Ihr Briefing genaue Kollisionen, realistische Dynamik oder fotorealistischen menschlichen Bewegungsablauf in kurzen, in sich geschlossenen Shots verlangt, ist Sora 2 oft überlegen.
Vidu Q3 hingegen ist eher als Storytelling-Engine positioniert: längere Clips, Sequenzen mit mehreren Einstellungen und Regie-ähnliche Kamerasteuerung. Das bedeutet nicht, dass Vidu an Realismus spart, aber die primären Gewinne liegen in narrativer Kontinuität und kombinierter Audiovisual-Ausgabe statt in reiner Physiksimulation. Für filmisches Kurz-Storytelling (z. B. ein 16-sekündiges Produktdemo mit Schnitten und VO) ist der Q3-Workflow oft schneller und einfacher.
Welches Modell ist besser für filmischen Feinschliff und hohe Wiedergabetreue: Veo 3.1 vs. Vidu Q3?
Veo 3.1 (Google / DeepMind / Gemini) wurde als hochqualitatives, Enterprise-taugliches Angebot mit starken Kontinuitätskontrollen, nativer Audiogenerierung und Support innerhalb der Cloud-/Vertex-/Gemini-Stacks von Google vermarktet. Veo 3.1 führte fortgeschrittene „Ingredients to Video“-Funktionen ein, native Unterstützung für vertikale Formate (9:16) sowie Hochskalierung auf hohe Auflösungen (einschließlich 4K-Fähigkeiten in einigen Flows). Für Projekte, die die höchste Pixelqualität, präzise Farbharmonie und straffe Enterprise-APIs erfordern, ist Veo 3.1 häufig die erste Wahl.
Vidu Q3 behauptet sich, indem es sich auf verlängerte Dauer + Multi-Shot-Erzählkohärenz und eine creatorzentrierte Produktisierung (schnelle Web-Playgrounds, Mehrfachreferenz-Orchestrierung) konzentriert. Wenn Ihre Priorität darin liegt, eine menschlich dirigierte Kurzszene mit mehreren Kamerabewegungen und integrierten Audio-Cues zu produzieren (und Sie Länge über absolute Pixel-Politur stellen), ist Vidu Q3 überzeugend. Bei reiner fotorealer Wiedergabetreue hat Veo 3.1 typischerweise die Nase vorn.
Anfang 2026 besteht das KI-Video-Triumvirat aus OpenAIs Sora 2, Googles Veo 3.1 und Vidu Q3. So schneiden sie im direkten Vergleich ab:
| Feature | Vidu Q3 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| Max Single Clip Duration | ~16 s | Bis zu ~25 s (Pro) | 8 s (mit Funktionen zum narrativen Zusammenfügen) |
| Native Audio Generation | Ja (integriert) | Ja (experimentell) | Ja (erweitert) |
| Cinematic Camera Control | Ja (shot-aware) | Begrenzte Voreinstellungen | Ja (Konsistenz über mehrere Shots) |
| Multi-shot Narrative | Ja | Ja | Ja |
| Text Rendering in Frames | Ja | Variiert | Variiert |
| Resolution | 1080p | 1080p | 1080p / 4K in Sonderfällen |
| Primary Use Case | Narratives Storytelling, Animation | High-Budget-Konzept/Film | YouTube Shorts / TikTok |
Analyse:
- Vs. Sora 2: Sora 2 bleibt das Schwergewicht für reine visuelle Wiedergabetreue und surrealistische Vorstellungskraft („Hollywood-Qualität“). Vidu Q3 übertrifft es jedoch bei der Workflow-Effizienz dank der 16-Sekunden-Grenze und der überlegenen Audio-Integration. Für Creators, die einen „Done-in-one“-Clip benötigen, ist Q3 schneller.
- Vs. Veo 3.1: Googles Veo 3.1 überzeugt durch Geschwindigkeit bei kürzeren, auf Social Media ausgerichteten Clips (4–8 s) und ist tief in YouTube integriert. Vidu Q3 zielt höher in der Wertschöpfungskette, auf professionelle Animatorinnen/Animatoren und Filmemacher, die längere, kontinuierliche Schnitte benötigen, die Veo nicht immer konsistent halten kann.
Welche praktischen Anwendungsfälle ermöglicht Vidu Q3?
Werbung und Short-Form-Marketing
Marken können Werbekonzepte Ende-zu-Ende deutlich schneller prototypisieren: Skript schreiben, ein 16-sekündiges Visual mit synchronisiertem VO und SFX generieren, Wording und Shot-Komposition iterieren und durch Prompt-Varianten mehrere Sprachfassungen erzeugen. Für A/B-Tests von Social Creatives ist der reduzierte Durchlauf ein klarer Business-Vorteil. Fallstudien von Plattformen zeigen, dass Marketer Vidu Q3 für Mikro-Ads und Produkt-Teaser nutzen.
Storyboarding und Previsualization für Film und TV
Regisseurinnen, Regisseure und Editor-Teams verwenden kurze KI-Clips als Previsualizations (Previz), um Szenen zu blocken, Kamerabewegungen zu testen und Treatments zu pitchen. Vidu Q3s Sequenzen mit mehreren Einstellungen und smarte Kamerakontrollen sind hierbei besonders nützlich: Kreativteams können Blocking und Dialoge iterieren, ohne die Kosten von Location-Drehs. Während KI-Previz die Regie am Set nicht ersetzt, verkürzt sie die frühen Entscheidungszyklen.
E-Learning und Erklärvideos
Bildungs- und Corporate-Learning-Abteilungen können prägnante animierte Erklärsegmente mit synchronisierter Erzählstimme und annotierten SFX erstellen. Für standardisierte Inhalte (Produktschulungen, Onboarding) reduziert das die Abhängigkeit von teuren Produktionshäusern und beschleunigt lokalisierte Versionen. Die Time-to-Publish und die nativen Audio-Fähigkeiten machen Vidu Q3 für diese Use Cases attraktiv.
Gaming, Concept Art und Indie-Produktion
Indie-Entwickler und Game-Teams nutzen kurze KI-Kinoclips für Trailer, NPC-Dialog-Mockups oder Stil-Exploration. Vidu Q3s Unterstützung für Referenzbilder und Charakterkonsistenz hilft, die visuelle Identität einer Game-IP in Prototyp-Trailern kohärent zu halten. Das Modell wird auch für Pitch-Materialien eingesetzt, um Finanzierung oder Publisher-Interesse zu sichern.
Barrierefreiheit und schnelle Lokalisierung
Da Audio nativ erzeugt wird, vereinfacht Vidu Q3 mehrsprachige Versionen: dieselbe Aufnahme mit unterschiedlichen Sprachprompts generieren oder unterschiedliche Stimmfarben anfordern. Dies ermöglicht eine schnelle Lokalisierung von Marketinginhalten oder Trainingsmaterialien bei gleichzeitiger Beibehaltung einer Lippensynchronität, die für viele Kurzform-Kontexte ausreichend ist (auch wenn erstklassige Lippenanpassung für Broadcast ggf. weiterhin menschliche Feinabstimmung erfordert).
Ist Vidu Q3 das beste KI-Videomodell im Jahr 2026?
Eine einzelne „beste“ Lösung auszurufen, verkennt die Nuancen: Der Gewinner hängt vom Anwendungsfall ab.
- Für fotorealistische, physikalisch fundierte Ausgaben und konservatives Safety-Handling ist OpenAIs Sora 2 häufig die erste Wahl. Es betont Realismus und robuste Moderation und ist damit attraktiv für High-End-Produktionen und risikoaverse Unternehmen.
- Für plattformintegrierte, formatoptimierte Kurzform-Inhalte machen Veo 3.1s native vertikale Ausgaben und Googles App-Integrationen (YouTube Shorts, Google Photos) es einzigartig bequem.
- Für schnelle Audio-Video-Prototypen, Multi-Shot-Narrativkontrolle und eine starke Balance an Storytelling-Funktionen ist Vidu Q3 herausragend — besonders wenn Iterationsgeschwindigkeit und integriertes Audio wichtiger sind als absolute Fotorealistik. Frühe Benchmarks und Anbieterberichte platzieren Vidu Q3 weit oben in T2V-Rankings, und seine Features machen es zu einer praktischen Wahl für Marketer, unabhängige Creators und Studios in der Prototyping-Phase.
Einschränkungen und Überlegungen?
Auch wenn Vidu Q3 einen Durchbruch darstellt, gibt es Trade-offs:
- Die Clip-Dauer ist weiterhin gedeckelt (~16 s), längere Erzählungen erfordern also Stitching oder mehrere Prompts.
- Die Ressourcenkosten können bei HD-Generierung und komplexem Audio steigen.
- KI-Tools erfordern weiterhin redaktionelles Urteilsvermögen, um Ausgaben zu verfeinern und zu fertigen Produkten zu gestalten.
Also: Vidu Q3 ist 2026 ein Spitzenkandidat, insbesondere für Creators, die native Audio-Workflows und Multi-Shot-Storytelling priorisieren. Ob es das beste ist, hängt vom konkreten Produktionsbriefing, regulatorischen Anforderungen und der Distributionspipeline der Nutzerin/des Nutzers ab.
Fazit
Vidu Q3 sticht 2026 als führendes KI-Videomodell hervor, das erzählfertige, integrierte Audio-Video-Clips produziert und damit Kreativität und Produktionsanforderungen verbindet. Im Vergleich zu Sora 2s starker narrativer Kohärenz und Veo 3.1s filmischem Realismus bietet Vidu Q3 ein ausgewogenes Toolkit, das sich ideal für Storyteller, Content-Creators und kommerzielle Workflows eignet.
Da Benchmarks seine hohe Leistung und integrierten Funktionen zeigen, markiert Vidu Q3 einen Wendepunkt in der generativen Video-KI — komplexe audiovisuelle Produktion wird zugänglicher und effizienter.
Entwickler können auf Vidu Q3, Veo 3.1 und Sora 2 über CometAPI zugreifen, die neuesten Modelle sind zum Veröffentlichungsdatum des Artikels aufgeführt. Beginnen Sie, indem Sie die Fähigkeiten des Modells im Playground erkunden und den API-Leitfaden für detaillierte Anweisungen konsultieren. Bitte stellen Sie sicher, dass Sie sich vor dem Zugriff bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bietet einen deutlich niedrigeren Preis als der offizielle, um Ihnen die Integration zu erleichtern.
Bereit?→ Sign up fo Video generation today !
Wenn Sie mehr Tipps, Anleitungen und News zu KI möchten, folgen Sie uns auf VK, X und Discord!