

In einer Landschaft, die von der „Skalieren-um-jeden-Preis“-Philosophie dominiert wird – in der Modelle wie Flux.2 und Hunyuan-Image-3.0 die Parameterzahlen in den massiven Bereich von 30B bis 80B treiben – ist ein neuer Herausforderer aufgetaucht, der den Status quo aufmischt. Z-Image, entwickelt vom Tongyi Lab von Alibaba, wurde offiziell gestartet und sprengt Erwartungen mit einer schlanken Architektur von 6 Milliarden Parametern, die die Ausgabequalität der Branchenriesen rivalisiert und gleichzeitig auf Consumer-Hardware läuft.
Veröffentlicht Ende 2025, fesselte Z-Image (und die blitzschnelle Variante Z-Image-Turbo) die KI-Community sofort und überschritt innerhalb von 24 Stunden nach dem Debüt die Marke von 500.000 Downloads. Mit fotorealistischen Bildern in nur 8 Inferenzschritten ist Z-Image nicht einfach nur ein weiteres Modell; es ist eine demokratisierende Kraft im generativen KI-Bereich, die hochfidele Kreation auf Laptops ermöglicht, an denen Wettbewerber scheitern würden.
Was ist Z-Image?
Z-Image ist ein neues, Open-Source-Bildgenerierungs-Foundation-Modell, entwickelt vom Forschungsteam Tongyi-MAI / Alibaba Tongyi Lab. Es ist ein generatives Modell mit 6 Milliarden Parametern, das auf einer neuartigen Scalable Single-Stream Diffusion Transformer (S3-DiT)-Architektur basiert, die Text-Token, visuelle semantische Token und VAE-Token zu einem einzigen Verarbeitungsstrom verkettet. Das Designziel ist eindeutig: erstklassigen Fotorealismus und Befolgung von Anweisungen liefern, während die Inferenzkosten drastisch gesenkt werden und die praktische Nutzung auf Consumer-Hardware ermöglicht wird. Das Z-Image-Projekt veröffentlicht Code, Modellgewichte und eine Online-Demo unter einer Apache-2.0-Lizenz.
Z-Image wird in mehreren Varianten ausgeliefert. Die am meisten diskutierte Veröffentlichung ist Z-Image-Turbo — eine destillierte, wenige-Schritte-Version, optimiert für den Einsatz — plus das nicht destillierte Z-Image-Base (Foundation-Checkpoint, besser zum Fine-Tuning geeignet) und Z-Image-Edit (anweisungsgetuned für Bildbearbeitung).
Der „Turbo“-Vorteil: 8-Schritt-Inferenz
Die Flaggschiff-Variante Z-Image-Turbo nutzt eine progressive Destillationstechnik namens Decoupled-DMD (Distribution Matching Distillation). Dies ermöglicht es dem Modell, den Generierungsprozess von den üblichen 30–50 Schritten auf lediglich 8 Schritte zu komprimieren.
Ergebnis: Generationszeiten unter einer Sekunde auf Enterprise-GPUs (H800) und praktisch Echtzeit-Performance auf Consumer-Karten (RTX 4090), ohne den „plastischen“ oder „ausgewaschenen“ Look, der für andere Turbo/Lightning-Modelle typisch ist.
4 Schlüsselmerkmale von Z-Image
Z-Image ist vollgepackt mit Funktionen, die sowohl technischen Entwicklern als auch kreativen Profis zugutekommen.
1. Unübertroffener Fotorealismus & Ästhetik
Trotz nur 6 Milliarden Parametern erzeugt Z-Image Bilder mit verblüffender Klarheit. Es glänzt bei:
- Hauttextur: Reproduktion von Poren, Unregelmäßigkeiten und natürlicher Beleuchtung bei menschlichen Motiven.
- Materialphysik: Präzises Rendern von Glas-, Metall- und Stofftexturen.
- Beleuchtung: Überlegene Handhabung von cineastischer und volumetrischer Beleuchtung im Vergleich zu SDXL.
2. Native zweisprachige Textdarstellung
Einer der größten Schmerzpunkte bei der KI-Bildgenerierung war die Textrendering-Fähigkeit. Z-Image löst dies mit nativer Unterstützung für sowohl Englisch als auch Chinesisch.
- Es kann komplexe Poster, Logos und Beschilderungen mit korrekter Rechtschreibung und Kalligraphie in beiden Sprachen erzeugen – eine Fähigkeit, die bei westlich geprägten Modellen oft fehlt.
3. Z-Image-Edit: Anweisungsbasierte Bearbeitung
Neben dem Basismodell veröffentlichte das Team Z-Image-Edit. Diese Variante ist für Bild-zu-Bild-Aufgaben feinabgestimmt und ermöglicht die Modifikation bestehender Bilder mittels natürlicher Sprachbefehle (z. B. „Lass die Person lächeln“, „Ändere den Hintergrund in einen verschneiten Berg“). Dabei bleibt die Konsistenz in Identität und Beleuchtung hoch.
4. Zugänglichkeit auf Consumer-Hardware
- VRAM-Effizienz: Läuft komfortabel auf 6GB VRAM (mit Quantisierung) bis 16GB VRAM (volle Präzision).
- Lokale Ausführung: Unterstützt vollständig die lokale Bereitstellung über ComfyUI und
diffusers, sodass Nutzer nicht auf Cloud-Dienste angewiesen sind.
Wie funktioniert Z-Image?
Single-Stream Diffusion Transformer (S3-DiT)
Z-Image weicht von klassischen Dual-Stream-Designs (separate Text- und Bild-Encoder/Streams) ab und verkettet stattdessen Text-Token, Bild-VAE-Token und visuelle semantische Token zu einem einzigen Transformer-Input. Dieser Single-Stream-Ansatz verbessert die Parameternutzung und vereinfacht die cross-modale Ausrichtung im Transformer-Backbone, was laut Autoren ein günstiges Effizienz/Qualitäts-Verhältnis für ein 6B-Modell ergibt.
Decoupled-DMD und DMDR (Destillation + RL)
Um eine Generierung mit wenigen Schritten (8 Schritte) ohne den üblichen Qualitätsverlust zu ermöglichen, entwickelte das Team einen Decoupled-DMD-Destillationsansatz. Die Technik trennt die CFG (classifier-free guidance)-Augmentation von der Verteilungsanpassung, sodass jede unabhängig optimiert werden kann. Anschließend wird ein nachgelagerter Reinforcement-Learning-Schritt (DMDR) angewandt, um semantische Ausrichtung und Ästhetik zu verfeinern. Zusammen ergeben diese Z-Image-Turbo mit deutlich weniger NFEs als typische Diffusionsmodelle bei gleichzeitig hoher Realitätsnähe.
Trainingsdurchsatz und Kostenoptimierung
Z-Image wurde mit einem Lifecycle-Optimierungsansatz trainiert: kuratierte Datenpipelines, ein verschlanktes Curriculum und effizientbewusste Implementierungsentscheidungen. Die Autoren berichten, den gesamten Trainings-Workflow in etwa 314K H800 GPU-Stunden (≈ USD $630K) abgeschlossen zu haben — eine explizite, reproduzierbare Ingenieurskennzahl, die das Modell als kosteneffizient im Vergleich zu sehr großen (>20B) Alternativen positioniert.
Benchmark-Ergebnisse des Z-Image-Modells
Z-Image-Turbo erreichte hohe Platzierungen auf mehreren aktuellen Bestenlisten, darunter eine Spitzenposition unter Open-Source-Modellen auf der Artificial Analysis Text-to-Image-Bestenliste und starke Leistung bei Auswertungen in der Alibaba AI Arena basierend auf menschlichen Präferenzen.
Doch die reale Qualität hängt auch von Prompt-Formulierung, Auflösung, Upscaling-Pipeline und zusätzlicher Nachbearbeitung ab.
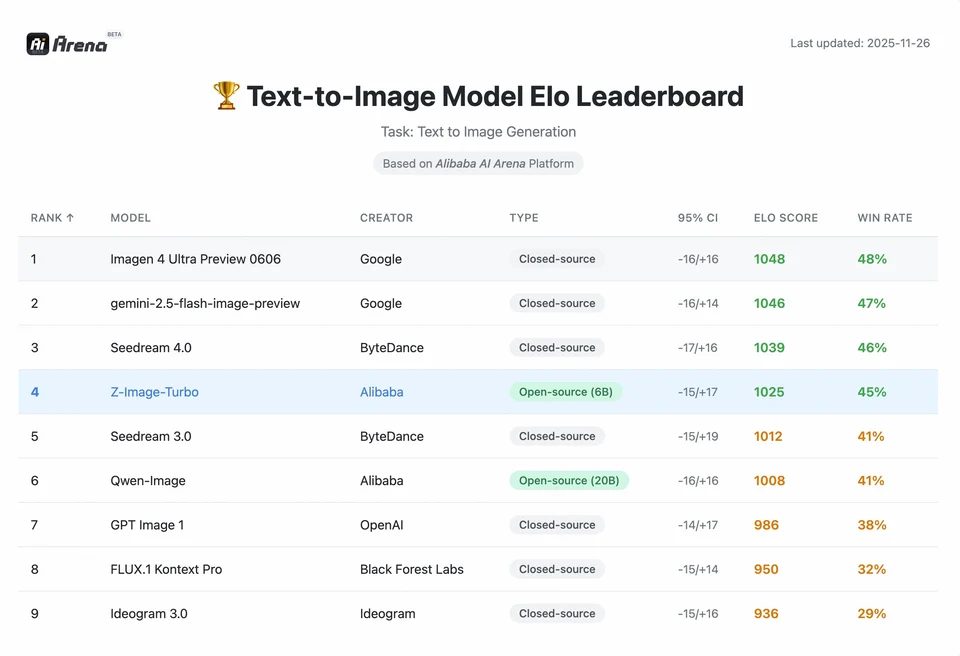
Um das Ausmaß der Leistung von Z-Image zu verstehen, müssen wir uns die Daten ansehen. Nachfolgend eine vergleichende Analyse von Z-Image gegenüber führenden Open-Source- und proprietären Modellen.
Vergleichende Benchmark-Zusammenfassung
| Funktion / Metrik | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Architektur | S3-DiT (Single Stream) | MM-DiT (Dual Stream) | U-Net | Diffusionstransformer |
| Parameter | 6 Milliarden | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Inferenzschritte | 8 Schritte | 25 - 50 Schritte | 1 - 4 Schritte | 30 - 50 Schritte |
| Erforderlicher VRAM | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Textdarstellung | Hoch (EN + CN) | Hoch (EN) | Mittel (EN) | Hoch (CN + EN) |
| Generationsgeschwindigkeit (4090) | ~1,5 - 3,0 Sekunden | ~15 - 30 Sekunden | ~0,5 Sekunden | ~20 Sekunden |
| Fotorealismus-Score | 9,2/10 | 9,5/10 | 7,5/10 | 9,0/10 |
| Lizenz | Apache 2.0 | Non-Commercial (Dev) | OpenRAIL | Custom |
Datenanalyse & Leistungs-Insights
- Geschwindigkeit vs. Qualität: Während SDXL Turbo schneller ist (1 Schritt), verschlechtert sich die Qualität bei komplexen Prompts deutlich. Z-Image-Turbo trifft den „Sweet Spot“ bei 8 Schritten, erreicht die Qualität von Flux.2 und ist dabei 5- bis 10-mal schneller.
- Demokratisierung der Hardware: Flux.2 ist zwar leistungsstark, aber de facto hinter 24GB-VRAM-Karten (RTX 3090/4090) für angemessene Performance „eingezäunt“. Z-Image ermöglicht Nutzern mit Mittelklasse-Karten (RTX 3060/4060), lokal professionelle 1024x1024-Bilder zu generieren.
Wie können Entwickler auf Z-Image zugreifen und es nutzen?
Es gibt drei typische Ansätze:
- Hosted / SaaS (Web-UI oder API): Dienste wie z-image.ai oder andere Anbieter, die das Modell bereitstellen und eine Weboberfläche oder kostenpflichtige API für die Bildgenerierung anbieten, nutzen. Dies ist der schnellste Weg für Experimente ohne lokale Einrichtung.
- Hugging Face + diffusers-Pipelines: Die Hugging Face-
diffusers-Bibliothek enthältZImagePipelineundZImageImg2ImgPipelineund bietet typischefrom_pretrained(...).to("cuda")-Workflows. Dies ist der empfohlene Weg für Python-Entwickler, die eine unkomplizierte Integration und reproduzierbare Beispiele wünschen. - Lokale native Inferenz aus dem GitHub-Repo: Das Tongyi-MAI-Repo enthält native Inferenzskripte, Optimierungsoptionen (FlashAttention, Kompilierung, CPU-Offload) und Anweisungen zur Installation von
diffusersaus dem Quellcode für die neueste Integration. Dieser Weg ist hilfreich für Forscher und Teams, die die volle Kontrolle möchten oder eigenes Training/Fine-Tuning durchführen.
Wie sieht ein minimales Python-Beispiel aus?
Nachfolgend ein kompaktes Python-Snippet mit Hugging Face diffusers, das Text-zu-Bild mit Z-Image-Turbo demonstriert.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Hinweise: guidance_scale-Defaults und empfohlene Einstellungen unterscheiden sich für Turbo-Modelle; die Dokumentation legt nahe, dass Guidance je nach gewünschtem Verhalten bei Turbo niedrig oder null sein kann.
Wie führt man Bild-zu-Bild (Edit) mit Z-Image aus?
Die ZImageImg2ImgPipeline unterstützt Bildbearbeitung. Beispiel:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Dies spiegelt die offiziellen Nutzungsmuster wider und eignet sich für kreative Bearbeitungen und Inpainting-Aufgaben.
Wie sollte man Prompts und Guidance angehen?
- Mit klarer Struktur arbeiten: Strukturieren Sie Prompts für komplexe Szenen mit Angabe von Szenenkomposition, Fokusobjekt, Kamera/Objektiv, Beleuchtung, Stimmung und eventuellen Textelementen. Z-Image profitiert von detaillierten Prompts und kann Positions- und erzählerische Hinweise gut verarbeiten.
guidance_scalesorgfältig abstimmen: Für Turbo-Modelle werden oft niedrigere Guidance-Werte empfohlen; Experimentieren ist erforderlich. Für viele Turbo-Workflows liefernguidance_scale=0.0–1.0mit einem Seed und fixen Schritten konsistente Ergebnisse.- Bild-zu-Bild für kontrollierte Bearbeitungen nutzen: Wenn Komposition beibehalten, aber Stil/Farbgebung/Objekte geändert werden sollen, starten Sie mit einem Init-Bild und nutzen
strength, um den Änderungsgrad zu steuern.
Beste Anwendungsfälle und Best Practices
1. Schnelles Prototyping & Storyboarding
Use Case: Filmregisseure und Game-Designer müssen Szenen sofort visualisieren.
Warum Z-Image? Mit unter 3 Sekunden Generationszeit können Kreative in einer Sitzung durch Hunderte Konzepte iterieren, Beleuchtung und Komposition in Echtzeit verfeinern, ohne Minuten auf ein Render warten zu müssen.
2. E-Commerce & Werbung
Use Case: Produkt-Hintergründe oder Lifestyle-Aufnahmen für Merchandise generieren.
Best Practice: Z-Image-Edit verwenden.
Laden Sie ein Rohproduktfoto hoch und nutzen Sie einen Anweisungs-Prompt wie „Platziere diese Parfümflasche auf einem Holztisch in einem sonnendurchfluteten Garten.“ Das Modell bewahrt die Integrität des Produkts und halluziniert gleichzeitig einen fotorealistischen Hintergrund.
3. Zweisprachige Content-Erstellung
Use Case: Globale Marketingkampagnen, die Assets für sowohl westliche als auch asiatische Märkte benötigen.
Best Practice: Nutzen Sie die Textrendering-Fähigkeit.
- Prompt: „Ein Neonschild mit der Aufschrift ‚OPEN‘ und ‚营业中‘, leuchtend in einer dunklen Gasse.“
- Z-Image rendert sowohl die englischen als auch die chinesischen Zeichen korrekt – eine Leistung, an der die meisten anderen Modelle scheitern.
4. Ressourcenarme Umgebungen
Use Case: KI-Generierung auf Edge-Geräten oder normalen Office-Laptops.
Optimierungstipp: Verwenden Sie die INT8-quantisierte Version von Z-Image. Dadurch sinkt der VRAM-Verbrauch auf unter 6GB bei vernachlässigbarem Qualitätsverlust, was lokale Apps auf Nicht-Gaming-Laptops ermöglicht.
Fazit: Wer sollte Z-Image nutzen?
Z-Image ist für Organisationen und Entwickler konzipiert, die hohen Fotorealismus mit praktischer Latenz und Kosten wünschen und offene Lizenzen sowie On-Premises- oder Custom-Hosting bevorzugen. Besonders attraktiv ist es für Teams, die schnelle Iteration benötigen (kreative Tools, Produkt-Mockups, Echtzeit-Services) sowie für Forscher/Community-Mitglieder, die an Fine-Tuning eines kompakten, aber leistungsfähigen Bildmodells interessiert sind.
CometAPI bietet ähnlich weniger eingeschränkte Grok Image-Modelle sowie Modelle wie Nano Banana Pro, GPT- image 1.5, Sora 2 (Kann Sora 2 NSFW-Inhalte generieren? Wie können wir es ausprobieren?) usw — vorausgesetzt, Sie verfügen über die richtigen NSFW-Tipps und -Tricks, um die Beschränkungen zu umgehen und frei zu erstellen. Bevor Sie zugreifen, stellen Sie bitte sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bietet einen Preis, der deutlich unter dem offiziellen liegt, um Ihnen die Integration zu erleichtern.
Bereit?→ Kostenlose Testphase zum Erstellen !