

as of December 15, 2025 the public facts show Google’s Gemini 3 Pro (preview) and OpenAI’s GPT-5.2 both set new frontiers in reasoning, multimodality and long-context work — but they take different engineering routes (Gemini → sparse MoE + huge context; GPT-5.2 → dense/“routing” designs, compaction and x-high reasoning modes) and therefore trade off peak benchmark wins vs. engineering predictability, tooling, and ecosystem. Which is “better” depends on your primary need: extreme-context, multimodal agentic applications lean toward Gemini 3 Pro; stable enterprise developer tooling, predictable costs and immediate API availability favor GPT-5.2.
What is GPT-5.2 and what are its main features?
GPT-5.2 is OpenAI’s December 11, 2025 release in the GPT-5 family (variants: Instant, Thinking, Pro). It’s positioned as the company’s most capable model for “professional knowledge work” — optimized for spreadsheets, presentations, long-context reasoning, tool calling, code generation, and vision tasks. OpenAI made GPT-5.2 available to paid ChatGPT users and via the OpenAI API (Responses API / Chat Completions) under model names such as gpt-5.2, gpt-5.2-chat-latest, and gpt-5.2-pro.
Model variants and intended use
- gpt-5.2 / GPT-5.2 (Thinking) — best for complex, multi-step reasoning (the default “Thinking” family variant used in the Responses API).
- gpt-5.2-chat-latest / Instant — lower latency day-to-day assistant and chat use.
- gpt-5.2-pro / Pro — highest fidelity / reliability for hardest problems (extra compute, supports
reasoning_effort: "xhigh").
Key technical features (user-facing)
- Vision & multimodal improvements — better spatial reasoning on images and improved video understanding when paired with code tools (Python tool), plus support for the code-interpreter style tools for executing snippets.
- Configurable reasoning effort (
reasoning_effort: none|minimal|low|medium|high|xhigh) to trade latency/cost vs. depth.xhighis new for GPT-5.2 (and supported on Pro). - Improved long-context handling and compaction features to reason across hundreds of thousands of tokens (OpenAI reports strong MRCRv2 / long-context metrics).
- Advanced tool calling & agentic workflows — stronger multi-turn coordination, better orchestration of tools across a “single mega-agent” style architecture (OpenAI highlights Tau2-bench tool performance).
What is Gemini 3 Pro Preview?
Gemini 3 Pro Preview is Google’s most advanced generative AI model, released as part of the broader Gemini 3 family in November 2025. The model is built with emphasis on multimodal understanding—capable of comprehending and synthesizing text, images, video, and audio—and features a large context window (~1 million tokens) for handling extensive documents or code bases.
Google positions Gemini 3 Pro as state-of-the-art in reasoning depth and nuance, and it serves as the core engine for multiple developer and enterprise tools, including Google AI Studio, Vertex AI, and agentic development platforms like Google Antigravity.
As of now, Gemini 3 Pro is in preview—meaning functionality and access are still expanding, but the model already benchmarks highly across logic, multimodal comprehension, and agentic workflows.
Key technical & product features
- Context window: Gemini 3 Pro Preview supports a 1,000,000-token input context window (and up to 64k token outputs), which is a major practical advantage for ingesting extremely large documents, books, or video transcripts in a single request.
- API features:
thinking_levelparameter (low/high) to trade off latency and reasoning depth;media_resolutionsettings to control multimodal fidelity and token usage; search grounding, file/URL context, code execution and function calling are supported. Thought signatures and context caching help maintain state across multi-call workflows. - Deep Think mode / higher reasoning: A “Deep Think” option gives an extra reasoning pass to push scores on tough benchmarks. Google publishes Deep Think as a separate high-performance path for complex problems.
- Multimodal native support: Text, image, audio, and video inputs with tight grounding for search and product integrations (Video-MMMU scores and other multimodal benchmarks are highlighted).
Quick preview — GPT-5.2 vs Gemini 3 Pro
Compact comparison table with the most important facts (sources cited).
| Aspect | GPT-5.2 (OpenAI) | Gemini 3 Pro (Google / DeepMind) |
|---|---|---|
| Vendor / positioning | OpenAI — flagship GPT-5.x upgrade focused on professional knowledge work, coding, and agentic workflows. | Google DeepMind / Google AI — flagship Gemini generation focused on ultra long-context multimodal reasoning and tool integration. |
| Main model flavors | Instant, Thinking, Pro (and Auto switching between them). Pro adds higher reasoning effort. | Gemini 3 family including Gemini 3 Pro and Deep-Think modes; multimodal / agentic focus. |
| Context window (input / output) | ~400,000 token total input capacity; up to 128,000 output / reasoning tokens (designed for very long documents & codebases). | Up to ~1,000,000 token input/context window (1M) with up to 64K-token outputs |
| Key strengths / focus | Long-context reasoning, agentic tool-calling, coding, structured workplace tasks (spreadsheets, presentations); safety/system-card updates emphasize reliability. | Multimodal understanding at scale, reasoning + image composition, very large context + “Deep Think” reasoning mode, strong tool/agent integrations in Google ecosystem. |
| Multimodal & image capabilities | Improved vision and multimodal grounding; tuned for tool use and document analysis. | High-fidelity image generation + reasoning-enhanced composition, multi-reference image editing and legible text rendering. |
| Latency / interactivity | Vendor emphasizes faster inference and prompt responsiveness (lower latency than prior GPT-5.x models); multiple tiers (Instant / Thinking / Pro). | Google emphasizes optimized “Flash”/serving and comparable interactive speeds for many flows; Deep Think mode trades off latency for deeper reasoning. |
| Notable features / differentiators | Reasoning effort levels (medium/high/xhigh), improved tool-calling, high-quality code generation, high token-efficiency for enterprise workflows. | 1M token context, strong native multimodal ingest (video/audio), “Deep Think” reasoning mode, tight Google product integrations (Docs/Drive/NotebookLM). |
| Typical best uses (short) | Long-document analysis, agentic workflows, complex coding projects, enterprise automation (spreadsheets/reports). | Extremely large multimodal projects, long-horizon agentic workflows that need 1M-token context, advanced image + reasoning pipelines. |
How do GPT-5.2 and Gemini 3 Pro compare architecturally?
Core architecture
- Benchmarks / real-work evals: GPT-5.2 Thinking achieved 70.9% wins/ties on GDPval (44-occupation knowledge work eval) and large gains on engineering and math benchmarks vs previous GPT-5 variants. Major improvements in coding (SWE-Bench Pro) and domain science QA (GPQA Diamond).
- Tooling & agents: Strong built-in support for tool calling, Python execution, and agentic workflows (document search, file analysis, data science agents). 11x speed / <1% cost vs human experts for some GDPval tasks (measure of potential economic value , 70.9% vs. previous ~38.8%), and shows concrete gains in spreadsheet modeling (e.g., +9.3% on a junior investment banking task vs GPT-5.1).
- Gemini 3 Pro: Sparse Mixture-of-Experts Transformer (MoE). The model activates a small set of experts per token, enabling extremely large total parameter capacity with sublinear per-token compute. Google publishes a model card clarifying the Sparse MoE design is a core contributor to the improved performance profile. This architecture makes it feasible to push model capacity far higher without linear inference cost.
- GPT-5.2 (OpenAI): OpenAI continues to use Transformer-based architectures with routing/compaction strategies in the GPT-5 family (a “router” triggers different modes — Instant vs Thinking — and the company documents compaction and token-management techniques for long contexts). GPT-5.2 emphasize training and evaluation to “think before answering” and compaction for long-horizon tasks rather than announcing classic sparse-MoE at scale.
Implications of the architectures
- Latency & cost tradeoffs: MoE models like Gemini 3 Pro can offer higher peak capability per token while keeping inference cost lower for many tasks because only a subset of experts run. They can, however, add complexity to serving and scheduling (cold-start expert balancing, IO). GPT-5.2’s approach (dense/routed with compaction) favors predictable latency and developer ergonomics — especially when integrated into established OpenAI tooling like Responses, Realtime, Assistants and batch APIs.
- Scaling long context: Gemini’s 1M input token capability lets you feed extremely long documents and multimodal streams natively. GPT-5.2’s ~400k combined context (input+output) is still massive and covers most enterprise needs but is smaller than Gemini’s 1M spec. For very large corpora or multi-hour video transcripts, Gemini’s spec gives a clear technical advantage.
Tooling, agents, and multimodal plumbing
- OpenAI: deep integration for tool calling, Python execution, “Pro” reasoning modes, and paid agent ecosystems (ChatGPT Agents / enterprise tool integrations). Strong focus on code-centric workflows and spreadsheet / slides generation as first-class outputs.
- Google / Gemini: built-in grounding to Google Search (optional billed feature), code execution, URL and file context, and explicit media resolution controls to trade tokens for visual fidelity. The API offers
thinking_leveland other knobs to tune cost/latency/quality.
How do the benchmark numbers compare
Context windows and token handling
- Gemini 3 Pro Preview: 1,000,000 input tokens / 64k output tokens (Pro preview model card). Knowledge cutoff: January 2025 (Google).
- GPT-5.2: OpenAI demonstrates strong long-context performance (MRCRv2 scores across 4k–256k needle tasks with >85–95% ranges on many settings) and uses compaction features; OpenAI’s public context examples indicate robust performance even at very large contexts but OpenAI lists variant-specific windows (and emphasizes compaction rather than a single 1M number). For API use, model names are
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-pro.
Reasoning and agentic benchmarks
- OpenAI (selected): Tau2-bench Telecom 98.7% (GPT-5.2 Thinking), strong gains in multi-step tool usage and agentic tasks (OpenAI highlights collapsing multi-agent systems into a “mega-agent”). GPQA Diamond and ARC-AGI showed step increases over GPT-5.1.
- Google (selected): Gemini 3 Pro: LMArena 1501 Elo, MMMU-Pro 81%, Video-MMMU 87.6%, high GPQA and Humanity’s Last Exam scores; Google also demonstrates strong long-horizon planning via agentic examples.
Tooling & agents:
GPT-5.2: Strong built-in support for tool calling, Python execution, and agentic workflows (document search, file analysis, data science agents). 11x speed / <1% cost vs human experts for some GDPval tasks (measure of potential economic value , 70.9% vs. previous ~38.8%), and shows concrete gains in spreadsheet modeling (e.g., +9.3% on a junior investment banking task vs GPT-5.1).
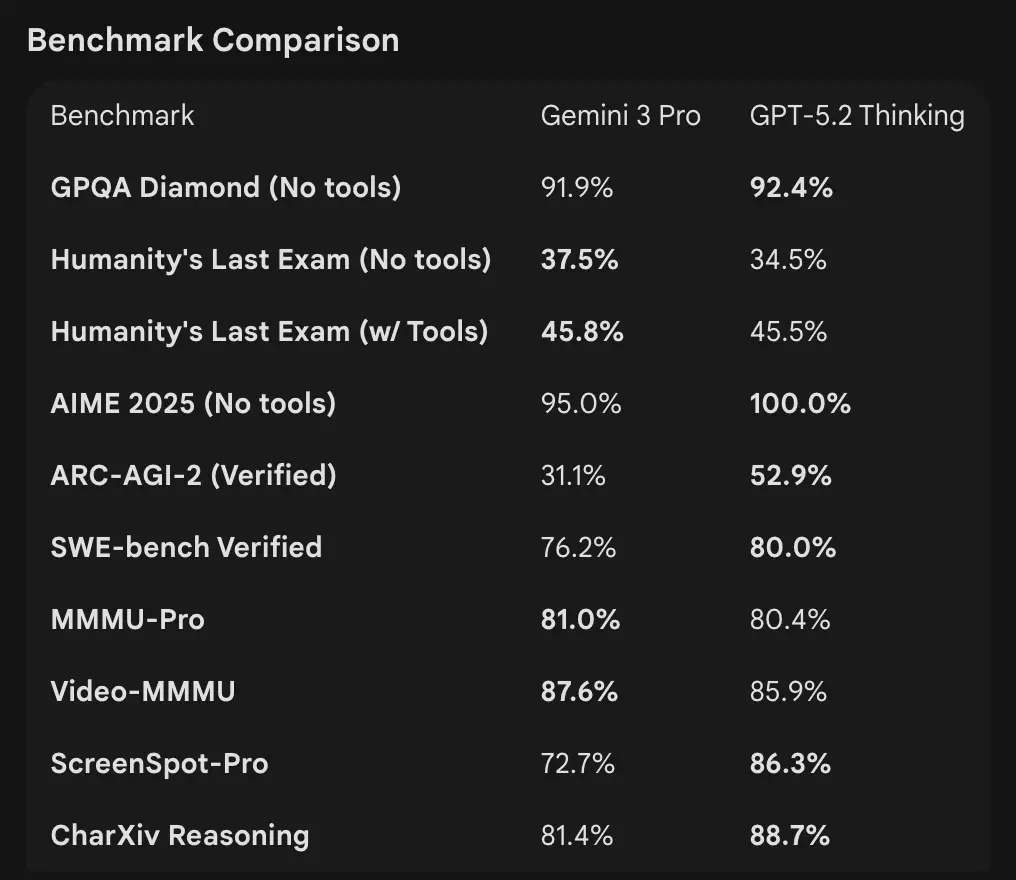
Interpretation: benchmarks are complementary — OpenAI emphasizes real-world knowledge work benchmarks (GDPval) showing GPT-5.2 excels at production tasks like spreadsheets, slides, and long agentic sequences. Google emphasizes raw reasoning leaderboards and extremely large single-request context windows. Which matters more depends on your workload: agentic, long-document enterprise pipelines favor GPT-5.2’s proven GDPval performance; ingestion of massive raw context (e.g., entire video corpora / full books in one pass) favors Gemini’s 1M input window.
How do multimodal capabilities compare?
Inputs & outputs
- Gemini 3 Pro Preview: supports text, image, video, audio, PDF inputs and text outputs; Google provides granular
media_resolutioncontrols and athinking_levelparameter to tune cost-vs-fidelity for multimodal work. Output token cap 64k; input up to 1M tokens. - GPT-5.2: supports rich vision and multimodal workflows; OpenAI highlights improved spatial reasoning (image component bounding estimated labels), video comprehension (Video MMMU scores) and tool-enabled vision (Python tool on vision tasks improves scores). GPT-5.2 emphasizes that complex vision + code tasks benefit greatly when tool support (Python code execution) is enabled.
Practical differences
Granularity vs. breadth: Gemini exposes a suite of multimodal knobs (media_resolution, thinking_level) aimed at letting developers tune tradeoffs per media type. GPT-5.2 emphasizes integrated tool-use (execute Python in the loop) to combine vision, code and data transformation tasks. If your use case is heavy video + image analysis with extremely large contexts, Gemini’s 1M context claim is compelling; if your workflows require executing code in the loop (data transformations, spreadsheet generation), GPT-5.2’s code tooling and agent friendliness may be more convenient.
What about API access, SDKs and pricing?
OpenAI GPT-5.2 (API & pricing)
- API:
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-provia Responses API / Chat Completions. Established SDKs (Python/JS), cookbook guides and a mature ecosystem. - Pricing (public):
1.75 / 1M input tokens** and **14 / 1M output tokens; caching discounts (90% for cached inputs) reduce effective cost for repeated data. OpenAI emphasizes token efficiency (higher per-token price but less total cost to reach a quality threshold).
Gemini 3 Pro Preview (API & pricing)
- API:
gemini-3-pro-previewvia Google GenAI SDK and Vertex AI/GenerativeLanguage endpoints. New parameters (thinking_level,media_resolution) and integration with Google groundings and tools. - Pricing (public preview): Roughly
2 / 1M input tokens** and **12 / 1M output tokens for preview tiers below 200k tokens; additional charges may apply for Search grounding, Maps, or other Google services (Search grounding billing begins Jan 5, 2026).
Use GPT-5.2 and Gemini 3 Via CometAPI
CometAPI is a gateway / aggregator API: a single, OpenAI-style REST API endpoint that gives you unified access to hundreds of models from many vendors (LLMs, image/video models, embedding models, etc.). Instead of integrating many vendor SDKs, CometAPI aims to let you call familiar OpenAI-format endpoints (chat/completions/embeddings/images) while switching models or vendors under the hood.
Developers can enjoy flagship models from two different companies simultaneously via CometAPI without switching vendors, and the API prices are more affordable, usually at 20% off.
Example: quick API snippets (copy-paste to try)
Below are minimal examples you can run. They reflect the vendors’ published quickstarts (OpenAI Responses API + Google GenAI client). Replace $OPENAI_API_KEY / $GEMINI_API_KEY with your keys.
GPT-5.2 — Python (OpenAI Responses API, reasoning set to xhigh for deep problems)
# Python (requires openai SDK that supports responses API)from openai import OpenAIclient = OpenAI(api_key="YOUR_OPENAI_API_KEY")resp = client.responses.create( model="gpt-5.2-pro", # gpt-5.2 or gpt-5.2-pro input="Summarize this 50k token company report and output a 10-slide presentation outline with speaker notes.", reasoning={"effort": "xhigh"}, # deeper reasoning max_output_tokens=4000)print(resp.output_text) # or inspect resp to get structured outputs / tokens
Notes: reasoning.effort lets you trade cost vs depth. Use gpt-5.2-chat-latest for Instant chat style. OpenAI docs show examples for responses.create.
GPT-5.2 — curl (simple)
curl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5.2", "input": "Write a Python function that converts a PDF with tables into a normalized CSV with typed columns.", "reasoning": {"effort":"high"} }'
(Inspect JSON for output_text or structured outputs.)
Gemini 3 Pro Preview — Python (Google GenAI client)
# Python (google genai client) — example from Google docsfrom google import genaiclient = genai.Client(api_key="YOUR_GEMINI_API_KEY")response = client.models.generate_content( model="gemini-3-pro-preview", contents="Find the race condition in this multi-threaded C++ snippet: <paste code here>", config={ "thinkingConfig": {"thinking_level": "high"} })print(response.text)
Notes: thinking_level controls the model’s internal deliberation; media_resolution can be set for images/videos. REST and JS examples are in Google’s Gemini dev guide.
Gemini 3 Pro — curl (REST)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Explain the race condition in this C++ code: ..."}] }], "generationConfig": {"thinkingConfig": {"thinkingLevel": "high"}} }'
Google’s docs include multimodal examples (image inline data, media_resolution).
Which model is “better” — practical guidance
There is no one-size-fits-all “winner”; instead choose based on use case and constraints. Below is a short decision matrix.
Choose GPT-5.2 if:
- You need tight integration with code-execution tools (OpenAI’s interpreter/tool ecosystem) for programmatic data pipelines, spreadsheet generation, or agentic code workflows. OpenAI highlights Python tool improvements and agentic mega-agent use.
- You prioritize token efficiency per vendor claims and want explicit, predictable OpenAI per-token pricing with large discounts on cached inputs (helps batch/production workflows).
- You want the OpenAI ecosystem (ChatGPT product integration, Azure / Microsoft partnerships, and tooling around Responses API and Codex).
Choose Gemini 3 Pro if:
- You need extreme multimodal input (video + images + audio + pdfs) and want a single model that natively accepts all these inputs with a 1,000,000 token input window. Google explicitly markets this for long videos, large document + video pipelines, and interactive Search/AI Mode use cases.
- You’re building on Google Cloud / Vertex AI and want tight integration with Google search grounding, Vertex provisioning, and the GenAI client APIs. You’ll benefit from Google product integrations (Search AI Mode, AI Studio, Antigravity agent tooling).
Conclusion: Which Is Better in 2026?
In the GPT-5.2 vs. Gemini 3 Pro Preview showdown, the answer is context-dependent:
- GPT-5.2 leads in professional knowledge work, analytical depth, and structured workflows.
- Gemini 3 Pro Preview excels in multimodal understanding, integrated ecosystems, and large context tasks.
Neither model is universally “better”—instead, their strengths complement different real-world demands. Smart adopters should match model choice to specific use cases, budget constraints, and ecosystem alignment.
What is clear in 2026 is that the AI frontier has advanced significantly, and both GPT-5.2 and Gemini 3 Pro are pushing the boundaries of what intelligent systems can achieve in the enterprise and beyond.
If you want to try right away, explore GPT-5.2 and Gemini 3 Pro's capabilities of CometAPI in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Free trial of GPT-5.2 and Gemini 3 Pro !
If you want to

