Gemini 3 Pro Preview
Gemini 3 Pro (Preview) is Google/DeepMind’s newest flagship multimodal reasoning model in the Gemini 3 family. It is positioned as their “most intelligent model yet,” designed for deep reasoning, agentic workflows, advanced coding, and long-context multimodal understanding (text, images, audio, video, code and tool integrations).
Key features
- Modalities: Text, image, video, audio, PDFs (and structured tool outputs).
- Agentic/tooling: Built-in function calling, search-as-tool, code execution, URL context, and support for orchestrating multi-step agents. Thought-signature mechanism preserves multi-step reasoning across calls.
- Coding & “vibe coding”: Optimized for front-end generation, interactive UI generation, and agentic coding (it tops relevant leaderboards reported by Google). It’s marketed as their strongest “vibe-coding” model yet.
- New developer controls:
thinking_level(low|high) to trade off cost/latency vs reasoning depth, andmedia_resolutioncontrols multimodal fidelity per image or video frame. These help balance performance, latency, and cost.
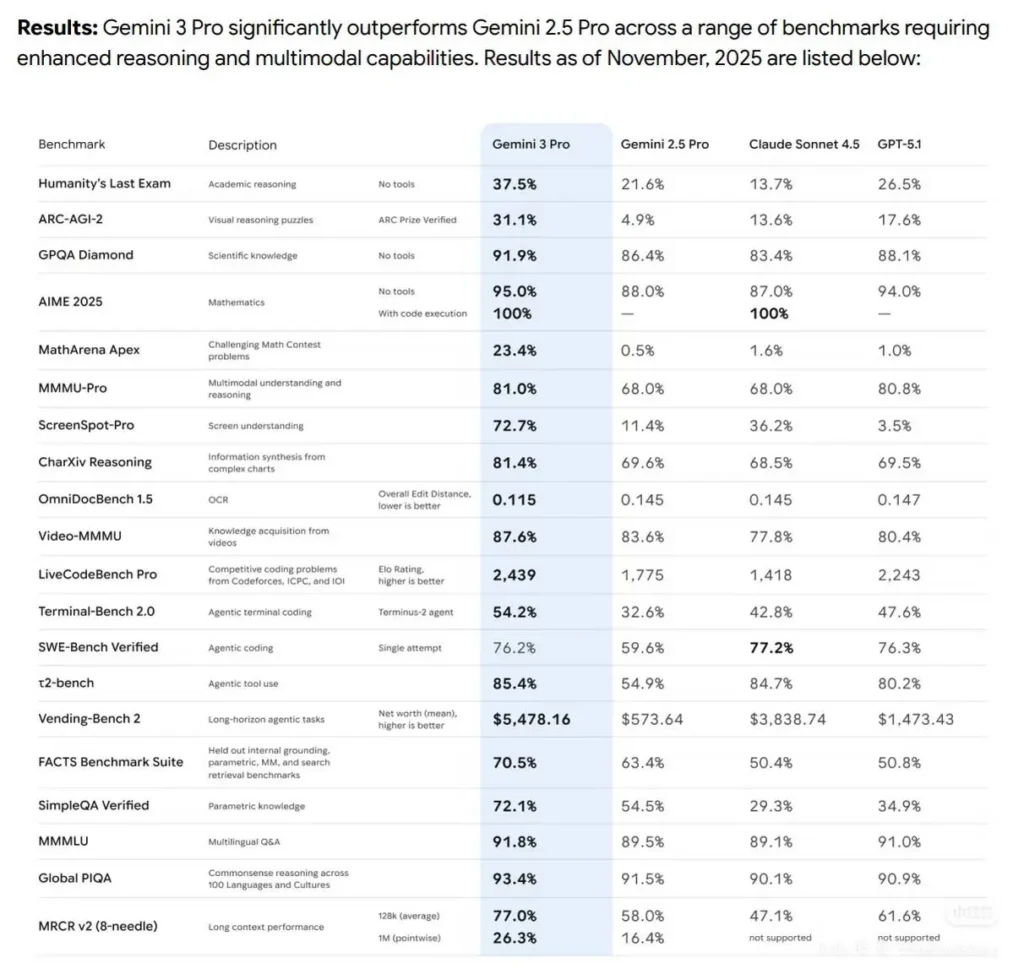
Benchmark performance
- The Gemini3Pro achieved first place in LMARE with a score of 1501, surpassing Grok-4.1-thinking’s 1484 points and also leading Claude Sonnet 4.5 and Opus 4.1.
- It also achieved first place in the WebDevArena programming arena with a score of 1487.
- In Humanity’s Last Exam academic reasoning, it achieved 37.5% (without tools); in GPQA Diamond science, 91.9%; and in the MathArena Apex math competition, 23.4%, setting a new record.
- In multimodal capabilities, the MMMU-Pro achieved 81%; and in Video-MMMU video comprehension, 87.6%.
Technical details & architecture
- “Thinking level” parameter: Gemini 3 exposes a
thinking_levelcontrol that lets developers trade off depth of internal reasoning vs latency/cost. The model treatsthinking_levelas a relative allowance for internal multi-step reasoning rather than a strict token guarantee. Default is typicallyhighfor Pro. This is an explicit new control for developers to tune multi-step planning and chain-of-thought depth. - Structured outputs & tools: The model supports structured JSON outputs and can be combined with built-in tools (Google Search grounding, URL context, code execution, etc.). Some structured-output+tools features are preview-only for
gemini-3-pro-preview. - Multimodal and agentic integrations: Gemini 3 Pro is explicitly built for agentic workflows (tooling + multiple agents over code/terminals/browser).
Limitations & known caveats
- Not perfect factuality — hallucinations remain possible. Despite strong factuality improvements claimed by Google, grounded verification and human review are still necessary in high-stakes settings (legal, medical, financial).
- Long-context performance varies by task. Support for a 1M input window is a hard capability, but empirical effectiveness can drop on some benchmarks at extreme lengths (observed pointwise declines at 1M on some long-context tests).
- Cost & latency trade-offs. Large contexts and higher
thinking_levelsettings increase compute, latency and cost; pricing tiers apply based on token volumes. Usethinking_leveland chunking strategies to manage costs. - Safety & content filters. Google continues to apply safety policies and moderation layers; certain content and actions remain restricted or will trigger refusal modes.
How Gemini 3 Pro Preview compares to other top models
High level comparison (preview → qualitative):
Against Gemini 2.5 Pro: Step-change improvements in reasoning, agentic tool use, and multimodal integration; much larger context handling and better long-form understanding. DeepMind shows consistent gains across academic reasoning, coding, and multimodal tasks.
Against GPT-5.1 and Claude Sonnet 4.5 (as reported): On Google/DeepMind’s benchmark slate Gemini 3 Pro is presented as leading on several agentic, multimodal, and long-context metrics (see Terminal-Bench, MMMU-Pro, AIME). Comparative results vary by task.
Typical and high-value use cases
- Large document / book summarization & Q&A: long context support makes it attractive for legal, research, and compliance teams.
- Code understanding & generation at repo scale: integration with coding toolchains and improved reasoning helps large codebase refactors and automated code review workflows.
- Multimodal product assistants: image + text + audio workflows (customer support that ingests screenshots, call snippets, and documents).
- Media generation & editing (photo → video): earlier Gemini family features now include Veo / Flow-style photo→video capabilities; preview suggests deeper multimedia generation for prototypes and media workflows.