

En sus actualizaciones de octubre, OpenAI informó que alrededor de 0.15% de usuarios activos semanales tener conversaciones que contienen indicadores explícitos de una posible planificación o intención suicida, una proporción que, cuando se escala a la gran base de usuarios de ChatGPT, corresponde a más de un millón de personas cada semana Al discutir temas relacionados con el suicidio con el servicio, se ha puesto el foco en una pregunta delicada: ¿pueden los modelos de lenguaje grandes responder de manera significativa y segura cuando las personas plantean preocupaciones graves de salud mental (incluida la psicosis, la manía, la intención suicida y la dependencia emocional profunda) en un chat?
Por lo tanto, las actualizaciones de octubre de OpenAI para GPT-5 —lanzadas en producción como gpt-5-oct-3 Actualización: representa el esfuerzo más explícito y mesurado de la compañía para que los modelos de lenguaje extenso (LLM) sean más seguros y útiles cuando los usuarios plantean problemas de salud mental. Los cambios no son una solución mágica; son un conjunto de medidas técnicas, de proceso y de evaluación destinadas a reducir resultados perjudiciales o inútiles, destacar recursos profesionales y disuadir a los usuarios de usar el modelo como sustituto de la atención clínica. Pero ¿cuánto ha mejorado el sistema en la práctica? ¿Qué ha cambiado exactamente? ¿Cuáles son los riesgos restantes?
¿Qué se actualizó OpenAI en gpt-5 y por qué es importante?
OpenAI implementó una actualización del modelo GPT-5 predeterminado de ChatGPT (comúnmente referenciado en las comunicaciones como gpt-5-oct-3) destinado específicamente a fortalecer el comportamiento del modelo en conversaciones sensibles — aquellos que incluyen signos de psicosis o manía, ideación o planificación suicida, o el tipo de dependencia emocional de una IA que puede desplazar las relaciones del mundo real.
Los cambios se basaron en consultas con más de 170 expertos en salud mental y en nuevas taxonomías internas y evaluaciones automatizadas diseñadas en torno a “comportamientos deseados” concretos, después de ser optimizadas por expertos en psicología, el modelo GPT-5:
- En conjuntos de desafíos específicos de salud mental, el nuevo modelo GPT-5 obtuvo resultados ~ 92% compatible con la taxonomía de comportamiento deseado de la empresa (en comparación con porcentajes mucho más bajos para versiones anteriores en conjuntos de pruebas difíciles).
- Para los escenarios de autolesión y suicidio, las evaluaciones automatizadas aumentaron ~ 91% cumplimiento de 77% sobre la variante anterior de GPT-5 en el punto de referencia específico descrito. OpenAI también informa ~ 65% reducción en las tasas de respuestas que “no cumplen totalmente” en varios dominios de salud mental en el tráfico de producción.
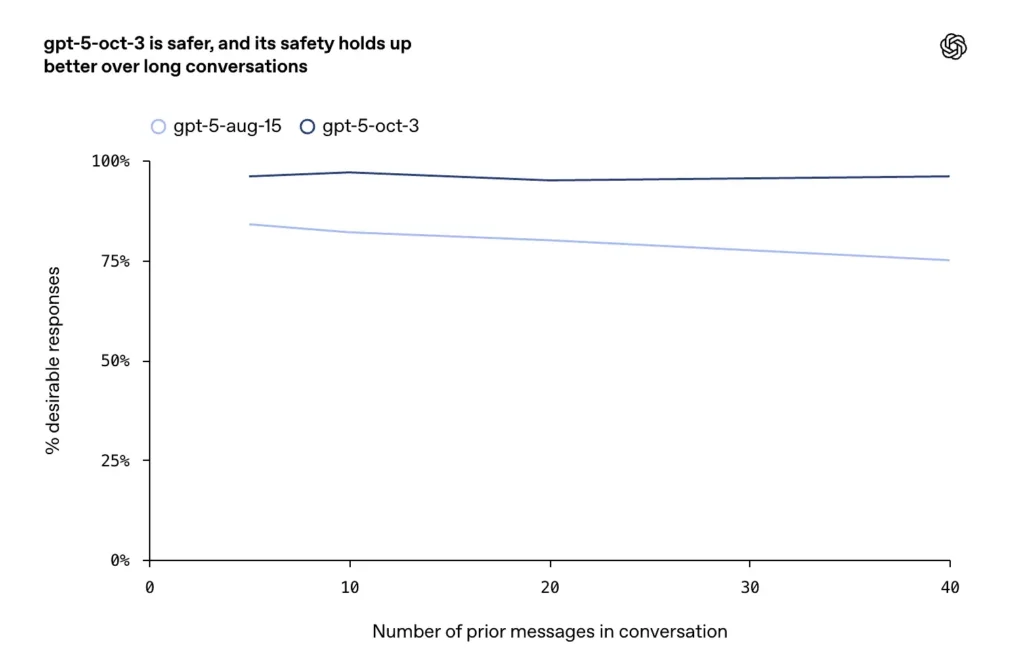
- Se informaron mejoras en conversaciones largas, adversarias o prolongadas (un modo de falla conocido para los modelos de chat), donde la compañía dice que las actualizaciones de octubre mantienen una mayor consistencia y seguridad en turnos de diálogo extendidos.
¿Por qué importa?
OpenAI afirmó que, dada la escala actual de ChatGPT, incluso porcentajes muy pequeños de conversaciones sensibles corresponden a un número absoluto muy elevado de personas. La compañía informó que, en una semana típica:
- sobre la 0.07% de los usuarios activos muestran posibles signos compatibles con psicosis o manía; y
- sobre la 0.15% de los usuarios activos tienen conversaciones que incluyen indicadores explícitos de una posible planificación o intención suicida; y
- aproximadamente 0.15% de los usuarios activos muestran “niveles elevados” de apego emocional a ChatGPT.
Para hacer concretos esos porcentajes: el CEO de OpenAI dijo que ChatGPT tiene ~800 millones de usuarios activos semanalesLa multiplicación da como resultado el número absoluto de usuarios:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Las categorías son ruidosas y se superponen (una sola conversación podría aparecer en más de una categoría) y que estas son estima derivados de taxonomías de detección interna en lugar de diagnósticos clínicos.
¿Cómo implementó OpenAI estos cambios: mecanismo de mejora de cinco pasos?
OpenAI describe un proceso multifacético, basado en la experiencia de expertos. A continuación, se presenta un resumen reproducible. mecanismo de mejora de cinco pasos que se corresponde con las divulgaciones de la empresa y las prácticas comunes en ingeniería de seguridad de modelos.
Mecanismo de mejora de cinco pasos
- Taxonomía y etiquetado guiados por expertos. Convocar a psiquiatras, psicólogos y médicos de atención primaria para definir los comportamientos y el lenguaje que indican psicosis/manía, intención de autolesionarse o dependencia emocional malsana; crear conjuntos de datos etiquetados y reglas de adjudicación.
- Recopilación de datos específicos y sugerencias seleccionadas. Recopilar fragmentos de conversaciones representativas, ejemplos de casos extremos y aportes adversarios; complementar con transcripciones de juegos de roles controlados producidos con la supervisión de un médico.
- Ajuste/puesta a punto del modelo con objetivos de seguridad. Entrene o ajuste el modelo base en el conjunto de datos seleccionados con términos de pérdida que penalicen el refuerzo de delirios, proporcionen plantillas de respuesta segura y promuevan el enrutamiento a recursos de crisis.
- Clasificador + capa de barandilla (seguridad en tiempo de ejecución). Implemente un clasificador rápido o una capa de monitoreo que detecte giros de alto riesgo en tiempo real y modifique los parámetros de decodificación del modelo, cambie a un respondedor especializado o escale a canales de revisión humana. (Esto es crucial para evitar comportamientos inestables cuando la conversación se desvía).
- Evaluación de expertos humanos y calibración continua. Indique a los médicos que califiquen a ciegas las respuestas del modelo utilizando rúbricas de evaluación clínica; mida las tasas de respuesta no deseada; itere en la taxonomía, los datos de entrenamiento y las indicaciones del sistema. Mantenga la telemetría de producción y vuelva a ejecutar los puntos de referencia con regularidad.
A continuación se muestra un pseudocódigo/bosquejo técnico compacto que captura el flujo de tiempo de ejecución que implementan la mayoría de los equipos de seguridad (esto es ilustrativo y no propietario):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
El flujo de trabajo de producción generalmente combina clasificadores a corto plazo (rápidos), respondedores más lentos pero de mayor calidad (indicaciones especializadas/puntos de control optimizados) y revisión humana para los casos marcados. Esto no es puramente académico: los médicos revisaron más de... 1,800 Las respuestas del modelo se calificaron según la taxonomía y esas revisiones moldearon materialmente la forma en que se escribieron las indicaciones y los comportamientos alternativos.
OpenAI indica públicamente que utilizaron variaciones de los cinco pasos y valoraciones clínicas para evaluar los resultados:
- Los expertos revisaron más de 1,800 respuestas modelo.
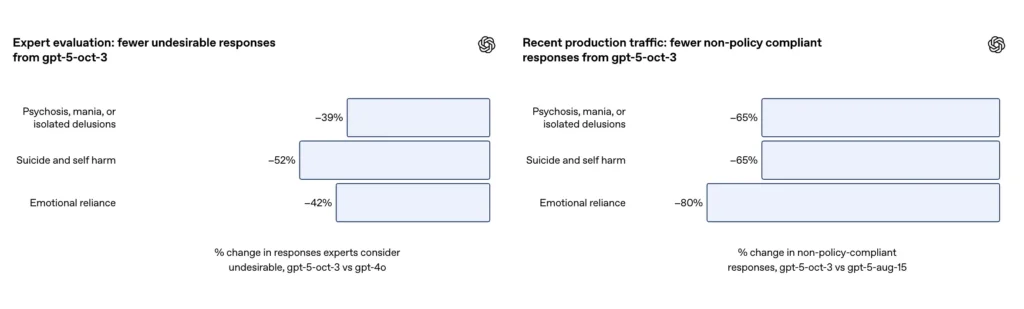
- La GPT-5 redujo las “respuestas insatisfactorias” entre un 39 y un 52 % en todas las categorías.
- La confiabilidad entre evaluadores osciló entre el 71 y el 77%, lo que indica un alto grado de consenso general a pesar de las diferencias subjetivas.
¿Cómo responde ahora el GPT-5 a la psicosis o la manía?
Lo que OpenAI le enseñó al modelo a hacer (y no hacer)
Medida: Mejorar la capacidad del modelo para reconocer y responder a síntomas graves como alucinaciones y manía. Para conversaciones que indiquen posibles creencias delirantes, alucinaciones o manía, OpenAI modificó partes de la especificación del modelo y proporcionó ejemplos de entrenamiento supervisado para que GPT-5 responda sin afirmar ni amplificar creencias infundadas. Se busca que el modelo sea empático, evite validar delirios y, cuando sea necesario, reoriente o oriente al usuario hacia medidas de seguridad prácticas y ayuda profesional.
Lo que muestra la evaluación
OpenAI informa que en un conjunto de prueba de conversaciones difíciles sobre psicosis/manía, el nuevo GPT-5 redujo sustancialmente las respuestas no deseadas en comparación con las líneas de base anteriores y que las evaluaciones automatizadas califican al modelo actualizado con un alto grado de cumplimiento en su taxonomía.
| Métrico | GPT-4o | GPT-5 | Mejoramiento |
|---|---|---|---|
| Tasa de respuesta de incumplimiento | Base | ↓ 65% | Mejora significativa |
| Evaluación de expertos clínicos | - | Reducción de las reacciones adversas en un 39% | - |
| Tasa de cumplimiento de la autoevaluación | 27% | 92% | ↑65 puntos porcentuales |
| Tasa de participación del usuario | ~0.07% de usuarios activos semanales | Extremadamente bajo pero claramente monitoreado | - |
Nota:
- Las respuestas inapropiadas disminuyeron en un 65%;
- Sólo el 0.07% de los usuarios y el 0.01% de los mensajes contenían dicho contenido;
- En evaluaciones de expertos, GPT-5 produjo un 39% menos de respuestas inapropiadas que GPT-4o;
- En las evaluaciones automatizadas, GPT-5 logró una tasa de cumplimiento del 92% (en comparación con el 27% de su predecesor).
¿Cómo aborda GPT-5 la ideación suicida y la autolesión?
Mayor apoyo en la ruta hacia el soporte y negativa a proporcionar instrucciones
OpenAI describe un entrenamiento ampliado y explícito para casos de autolesión y suicidio: el modelo está entrenado para reconocer señales directas e indirectas de intención o planificación, proporcionar un lenguaje empático y conciliador, presentar recursos de crisis (líneas telefónicas de ayuda, instrucciones locales de emergencia) y negarse a dar instrucciones para autolesionarse. Las actualizaciones de octubre hacen hincapié en un comportamiento más consistente en conversaciones largas, donde los modelos anteriores a veces tendían a dar respuestas inseguras o inconsistentes.
Resultados medidos
En un conjunto de evaluaciones seleccionadas de conversaciones desafiantes sobre autolesiones y suicidio, OpenAI informa que el GPT-5 actualizado logró 91% de cumplimiento con los comportamientos deseados de OpenAI, en comparación con 77% para el modelo GPT-5 anterior. La empresa también afirma que los expertos en la materia consideraron que el modelo actualizado reduce las respuestas no deseadas en aproximadamente 52% frente a GPT-4 sobre el mismo conjunto de problemas. Además, OpenAI afirma que se estima reducción de un 65% en el tráfico de producción de respuestas que “no cumplen totalmente” con su taxonomía para situaciones de autolesión después de implementar las nuevas medidas de seguridad.
| Métrico | GPT-4o | GPT-5 | Mejoramiento |
|---|---|---|---|
| Tasa de respuesta inapropiada | Base | ↓ 65% | Mejora significativa |
| Calificación de expertos clínicos | - | Las respuestas inapropiadas se redujeron en un 52%. | - |
| Tasa de cumplimiento de la autoevaluación | 77% | 91% | ↑14 puntos porcentuales |
| Tasa de participación del usuario | 0.15% semanal (millones de usuarios) | Muy bajo pero socialmente significativo | - |
Nota:
- Las respuestas inapropiadas disminuyeron en un 65%;
- Aproximadamente el 0.15% de los usuarios y el 0.05% de los mensajes implicaban posibles riesgos de suicidio;
- Las valoraciones de expertos mostraron que GPT-5 redujo las respuestas inapropiadas en un 52% en comparación con GPT-4o;
- La tasa de cumplimiento en las evaluaciones automatizadas aumentó al 91% (en comparación con el 77% de la generación anterior);
- En conversaciones prolongadas, GPT-5 mantuvo una estabilidad superior al 95%.
¿Qué es la “dependencia emocional” y cómo se abordó?
El desafío de que los usuarios formen vínculos afectivos
OpenAI define la dependencia emocional como patrones en los que un usuario muestra una dependencia potencialmente dañina de la IA, en detrimento de sus relaciones, responsabilidades o bienestar en el mundo real. No se trata de una falla de seguridad física inmediata como las instrucciones para autolesionarse, sino de un problema de seguridad conductual que puede erosionar el apoyo social y la resiliencia de una persona con el tiempo. La empresa incorporó la dependencia emocional como una categoría explícita en el desarrollo de su modelo y lo entrenó para fomentar la conexión con el mundo real, normalizar el contacto con otras personas y evitar un lenguaje que refuerce la exclusividad del apego.
En estas conversaciones, el modelo fue entrenado para:
- Anime a los usuarios a contactar con amigos, familiares o un terapeuta;
- Evite reforzar el apego a la IA;
- Responda a los delirios o creencias falsas de una manera amable y racional.
Resultados reportados
Según la adenda de OpenAI, la actualización produjo un ~80% de reducción en la tasa de respuestas del modelo que no cumplen completamente con la taxonomía de dependencia emocional en el tráfico de producción. En conversaciones de evaluación seleccionadas, las evaluaciones automatizadas calificaron el modelo actualizado en 97% de cumplimiento con el comportamiento deseado en escenarios de dependencia emocional, en comparación con el 50% del GPT-5 anterior. Las cifras sugieren una mejora significativa en la taxonomía específica y el conjunto de pruebas; sin embargo, la medición de la dependencia emocional en la naturaleza es inherentemente ruidosa y sensible a las diferencias culturales y contextuales.
| Métrico | GPT-4o | GPT-5 | Mejoramiento |
|---|---|---|---|
| Tasa de respuesta de incumplimiento | 50% | Compatible con 97% | ↓80% de respuestas inapropiadas |
| Evaluación de expertos | Las respuestas inapropiadas se redujeron en un 42%. | - | - |
| Tasa de participación del usuario | 0.15% usuarios/semana, 0.03% mensajes | Es raro, pero existe. | - |
| Comportamiento del modelo | Fomenta las relaciones en el mundo real; rechaza el “romance social simulado”. | - | - |
Nota:
- Las respuestas inapropiadas disminuyeron en un 80%;
- Aproximadamente el 0.15% de los usuarios/0.03% de los mensajes mostraron signos de posible dependencia emocional de la IA;
- La evaluación de expertos demostró que GPT-5 redujo las respuestas inapropiadas en un 42% en comparación con GPT-4o;
- El cumplimiento de la evaluación automatizada mejoró significativamente del 50% al 97%.
¿Cuáles son los límites y los riesgos pendientes?
Falsos negativos y falsos positivos
- Falsos negativosEl modelo puede no identificar señales sutiles o codificadas que indiquen que un usuario se encuentra en grave peligro, especialmente cuando las personas se comunican de forma indirecta o en clave.
- Falsos positivosEl sistema podría intensificar la alerta o enviar mensajes de crisis en casos que no lo requieren, lo que puede minar la confianza del usuario o generar alarmas innecesarias. Ambos tipos de errores son importantes porque influyen en el comportamiento del usuario y en su percepción de la atención recibida. OpenAI reconoce que la detección es imperfecta.
Dependencia excesiva de la automatización
Incluso el mejor modelo puede incitar a algunos usuarios a depender de las respuestas instantáneas y siempre disponibles de la IA en lugar de buscar apoyo humano constante. OpenAI señala explícitamente la dependencia emocional como una categoría de seguridad debido a este riesgo; las actualizaciones de la compañía buscan impulsar a los usuarios hacia la conexión humana, pero es difícil cambiar la dinámica social solo con mensajes.
Brechas contextuales y culturales
Las frases de seguridad que parecen apropiadas en una cultura o idioma pueden pasar por alto matices en otro. Es necesaria una localización exhaustiva y una evaluación culturalmente consciente; los resultados publicados de OpenAI aún no ofrecen desgloses completos por idioma o región.
Exposición legal y ética
Cuando fallos poco frecuentes tienen consecuencias graves, las empresas se enfrentan a riesgos legales y de reputación (como han puesto de manifiesto la cobertura mediática y las demandas). La transparencia de OpenAI sobre la magnitud del problema y sus esfuerzos por mitigar los daños es un paso importante, pero también conlleva un escrutinio regulatorio y legal.
Entonces, ¿puede GPT-5 ahora abordar problemas de salud mental?
Respuesta corta: **Es significativamente mejor en muchas tareas específicas y medibles.**Los datos publicados por OpenAI muestran reducciones significativas en las respuestas no deseadas en conjuntos de pruebas de autolesión, psicosis/manía y dependencia emocional. Se trata de mejoras reales, posibles gracias a la aportación de expertos, taxonomías más claras y una evaluación y monitorización rigurosas. Las cifras públicas de la empresa —altas tasas de cumplimiento y reducciones drásticas en las respuestas no conformes en conjuntos seleccionados— constituyen la evidencia más sólida hasta la fecha de que la ingeniería multidisciplinar deliberada y la colaboración clínica pueden modificar sustancialmente el comportamiento de los modelos.
¿Cómo acceder a la última API de GPT-5?
CometAPI es una plataforma API unificada que integra más de 500 modelos de IA de proveedores líderes, como la serie GPT de OpenAI, Gemini de Google, Claude de Anthropic, Midjourney, Suno y más, en una única interfaz intuitiva para desarrolladores. Al ofrecer autenticación, formato de solicitudes y gestión de respuestas consistentes, CometAPI simplifica drásticamente la integración de las capacidades de IA en sus aplicaciones. Ya sea que esté desarrollando chatbots, generadores de imágenes, compositores musicales o canales de análisis basados en datos, CometAPI le permite iterar más rápido, controlar costos y mantenerse independiente del proveedor, todo mientras aprovecha los últimos avances del ecosistema de IA.
Los desarrolladores pueden acceder API GPT-5 a través de CometAPI, la última versión del modelo Se actualiza constantemente con el sitio web oficial. Para empezar, explora las capacidades del modelo en el Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API". CometAPI Ofrecemos un precio muy inferior al oficial para ayudarte a integrarte.
¿Listo para ir?→ Regístrate en CometAPI hoy !
Si quieres conocer más consejos, guías y novedades sobre IA síguenos en VK, X y Discord!