

La serie Claude de Anthropic se ha convertido en un pilar fundamental en el cambiante panorama de los grandes modelos de lenguaje, especialmente para empresas y desarrolladores que buscan capacidades de IA de vanguardia. Con el lanzamiento de Claude Opus 4.1 el 5 de agosto de 2025, Anthropic ofrece una actualización gradual pero significativa respecto a su predecesor, Claude Opus 4 (lanzado el 22 de mayo de 2025). Este artículo examina las diferencias clave entre Opus 4.1 y Opus 4.0 en cuanto a rendimiento, arquitectura, seguridad y aplicabilidad en el mundo real, basándose en anuncios oficiales, benchmarks independientes y comentarios del sector.
Claude Opus 4.1 ya está disponible a través de la API (ID del modelo) claude-opus-4-1-20250805), Amazon Bedrock, Vertex AI de Google Cloud y en las interfaces de pago de Claude. Como actualización incremental, mantiene la compatibilidad total con Opus 4: el precio, los puntos de conexión y todas las integraciones existentes siguen funcionando sin cambios.
¿Qué es Claude Opus 4.0 y por qué es importante?
Claude Opus 4.0 marcó un avance sustancial en la búsqueda de Anthropic de inteligencia de vanguardia, combinando razonamiento robusto, manejo de contexto extendido y una sólida competencia en codificación en un único modelo. Logró:
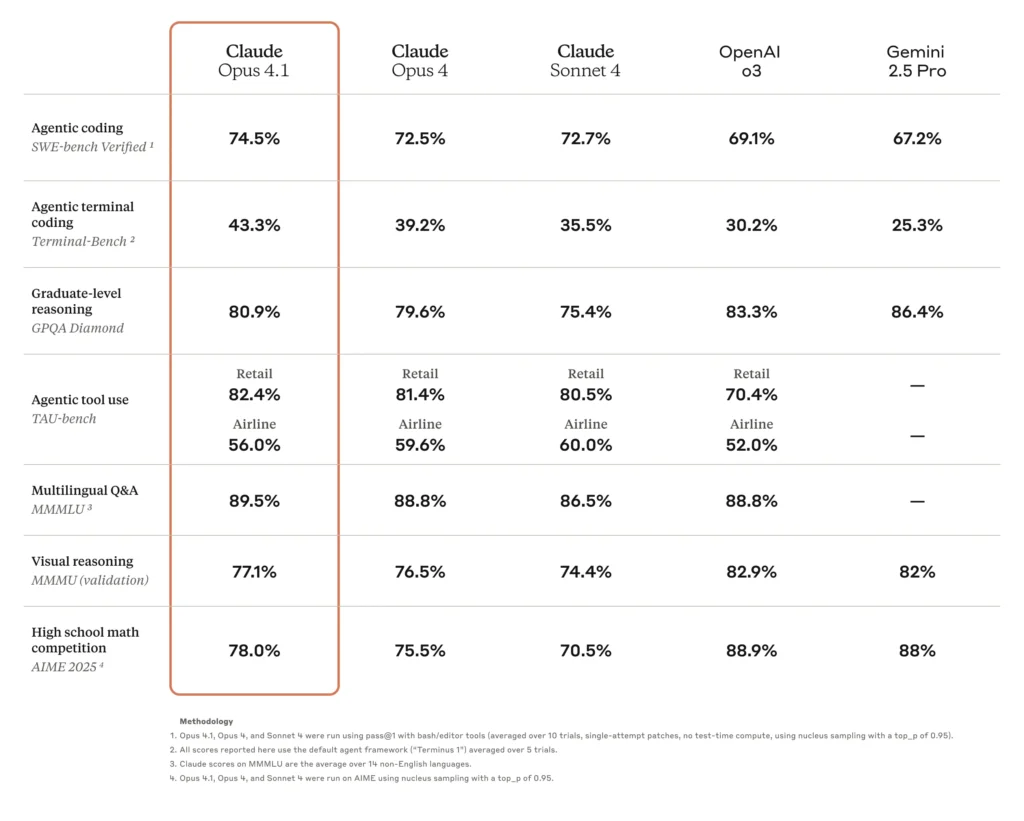
- Alta precisión de codificación:Opus 4.0 obtuvo un puntaje de 72.5% en SWE-bench Verified, un punto de referencia para desafíos de codificación del mundo real, lo que demuestra una importante aplicabilidad en el mundo real a las tareas de desarrollo de software.
- Capacidades de agente avanzadasEl modelo se destacó en la ejecución de tareas autónomas de varios pasos, lo que permitió que agentes de IA sofisticados gestionaran flujos de trabajo, desde la orquestación de marketing hasta la asistencia en la investigación.
- Habilidad creativa y analíticaMás allá de la codificación, Opus 4.0 ofreció un rendimiento de última generación en escritura creativa, análisis de datos y razonamiento complejo, lo que lo convirtió en un colaborador versátil tanto para dominios comerciales como técnicos.
La combinación de amplitud y profundidad de Opus 4.0 estableció un nuevo estándar para la IA empresarial, lo que impulsó una rápida adopción en los planes Claude Pro, Max, Team y Enterprise, así como la integración en Amazon Bedrock y Vertex AI de Google Cloud.
¿Qué novedades hay en Claude Opus 4.1?
Mejoras de referencia en tareas de codificación
Una de las mejoras más destacadas de Opus 4.1 es su mayor precisión de codificación. En SWE-bench Verified, Opus 4.1 obtiene... 74.5%, en comparación con el 4.0% de Opus 72.5. Esta ganancia de 2 puntos, aunque aparentemente modesta, equivale a reducciones significativas en los ciclos de depuración y una precisión mejorada en la síntesis y refactorización de código.
¿De qué manera son más confiables las tareas de agencia?
Opus 4.1 ofrece capacidades de razonamiento a largo plazo más robustas, lo que permite a los agentes de IA gestionar procesos complejos de varios pasos con mayor consistencia. Según AWS, el modelo ahora funciona como un "colaborador virtual ideal" para tareas que requieren cadenas de pensamiento extensas, como la gestión autónoma de campañas y la orquestación de flujos de trabajo multifuncionales.
Precisión de refactorización de múltiples archivos
Una característica destacada de Opus 4.1 es su enfoque conservador ante cambios de código a gran escala. Mientras que Opus 4.0 a veces introducía ediciones innecesarias en archivos interconectados, Opus 4.1 destaca por aislar los ajustes mínimos necesarios, identificando las correcciones exactas sin modificaciones colaterales.
¿Cómo se comparan en términos de puntos de referencia clave?
Puntos de referencia de codificación
| Modelo | SWE-bench verificado (%) | Puntuación de refactorización de múltiples archivos |
|---|---|---|
| Opus 4.0 | 72.5 | Base |
| Opus 4.1 | 74.5 | Ganancia de +1.2 σ |
Fuente: Tarjeta del sistema antrópico y puntos de referencia independientes
Búsqueda e investigación agenética
El Opus 4.1 muestra una 15% Mejora en las evaluaciones de agencia de TAU-bench, lo que refleja una mejor retención del contexto e iniciativa en las tareas de investigación. Los usuarios reportan una convergencia más rápida en la información relevante y resúmenes multidocumentales más coherentes.
Las comparaciones de referencia en tareas de "búsqueda agentica" muestran que Opus 4.1 obtiene puntuaciones más altas en planificación, uso de herramientas y resolución dinámica de problemas. La evaluación interna de investigación agentica de Anthropic indica una mejora del 5-7 % en la precisión del razonamiento multipaso en comparación con Opus 4.0, lo que permite una ejecución más fiable de flujos de trabajo como los canales de análisis de datos automatizados y la generación de informes de investigación. Estos avances se deben en parte a una mejor trazabilidad del razonamiento intermedio, una función que ofrece a los usuarios finales una mejor visibilidad de las rutas de decisión del modelo.
¿Qué tareas de codificación específicas obtienen los mayores beneficios?
- Refactorización de múltiples archivos:Opus 4.1 exhibe una consistencia mejorada al atravesar módulos interdependientes, reduciendo los errores entre archivos en más del 15% en las pruebas internas.
- Localización y reparación de errores:El modelo identifica de manera más confiable la causa raíz de los casos de prueba fallidos, reduciendo el tiempo promedio de resolución en un 25%.
- Generación de documentaciónLa fluidez mejorada del lenguaje natural admite cadenas de documentación de API más completas y conscientes del contexto, así como comentarios en línea.
¿Cómo gestiona Opus 4.1 las tareas de varios pasos?
- Heurísticas de planificación mejoradas, reduciendo los errores de planificación en cadenas de tareas de 10 pasos en un 8%.
- Integración mejorada del uso de herramientas, lo que permite llamadas API más precisas con menos errores de formato.
- Indicaciones de razonamiento provisional, lo que permite a los desarrolladores verificar y ajustar el razonamiento interno del modelo en “puntos de control” ajustables.
Métricas de cumplimiento de instrucciones
Las evaluaciones de un solo turno muestran que Opus 4.1 alcanzó una tasa de respuesta inofensiva del 98.76 % en solicitudes infractoras, en comparación con el 97.27 % de Opus 4.0, lo que indica un rechazo más estricto de contenido prohibido (). Las tasas de rechazo excesivo en consultas inofensivas se mantienen comparativamente bajas (0.08 % frente a 0.05 %), lo que garantiza que el modelo mantenga la capacidad de respuesta cuando corresponde.
¿Qué mejoras de seguridad y alineación están presentes?
Mejoras en la evaluación de un solo turno
Las auditorías de seguridad abreviadas de Anthropic para Opus 4.1 confirmaron un rendimiento consistente o mejorado en los parámetros de seguridad infantil, sesgo y alineación. Por ejemplo, las tasas de respuesta inofensiva bajo pensamiento extendido aumentaron del 97.67 % al 99.06 %.
Sesgo y robustez
En el índice de referencia de sesgo de BBQ, la puntuación de sesgo desambiguado de Opus 4.1 se sitúa en -0.51 frente a -0.60 de Opus 4.0, con una precisión superior al 90 % para consultas desambiguadas y casi perfecta para las ambiguas. Estas variaciones marginales indican una neutralidad sostenida y una alta fidelidad en contextos sensibles.
¿Qué sustenta las mejoras arquitectónicas?
Ajuste de modelos y actualizaciones de datos
El equipo de Anthropic implementó protocolos de ajuste refinados centrados en:
- Corpus de código ampliado:Incorporación de más repositorios de archivos múltiples anotados.
- Escenarios de agencia aumentados:Seleccionar cadenas de tareas más largas durante el entrenamiento para potenciar el razonamiento a largo plazo.
- Bucles de retroalimentación humana mejorados:Aprovechar el aprendizaje de refuerzo dirigido a partir de la retroalimentación humana (RLHF) sobre indicaciones de casos extremos para mitigar las alucinaciones.
Estos ajustes producen ganancias mensurables sin alterar la arquitectura central de Transformer, lo que garantiza una compatibilidad inmediata con las API antrópicas existentes.
Infraestructura y latencia
Si bien la latencia de inferencia bruta sigue siendo comparable a Opus 4.0, Anthropic optimizó su infraestructura de servicio para reducir los tiempos de inicio en frío 12%, mejorando la capacidad de respuesta para aplicaciones interactivas como Claude Chat y las integraciones de Copilot.
¿Cuáles son las implicaciones para los desarrolladores y las empresas?
Precios y disponibilidad
Claude Opus 4.1 se ofrece en el mismo precio Opus 4.0 en todos los canales (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). No se requieren cambios de código para actualizar; los usuarios simplemente seleccionan "Opus 4.1" en el selector de modelos.
Expansión de casos de uso
- Ingeniería de software:Depuración más rápida, generación de pruebas más precisa, integración mejorada del pipeline CI/CD.
- Agentes de inteligencia artificialFlujos de trabajo autónomos más confiables en marketing, finanzas e investigación.
- Inteligencia empresarial:Resumen mejorado, generación de informes y análisis profundos para la toma de decisiones basada en datos.
Estas actualizaciones se traducen en menores costos de desarrollo y un mayor retorno de la inversión para las iniciativas impulsadas por IA.
¿Qué sigue para Claude Opus?
Anthropic señala que Opus 4.1 es solo un paso en una hoja de ruta más amplia. El equipo anticipa mejoras significativamente mayores en las próximas versiones, probablemente enfocadas en:
- Ventanas de contexto aún más largas (más de 200K tokens).
- Capacidades multimodales para la comprensión integrada de imágenes, audio y código.
- Mayor interpretabilidad herramientas para rastrear rutas de decisión durante acciones de agencia.
Las empresas y los desarrolladores deben monitorear los canales de Anthropic para obtener actualizaciones, ya que cada actualización incremental consolida la posición de Claude entre los asistentes de IA más capaces y seguros disponibles.
Primeros Pasos
CometAPI es una plataforma API unificada que agrega más de 500 modelos de IA de proveedores líderes.De hecho, se puede acceder a Claude Opus 4.1 a través de CometAPI. Listas de CometAPI anthropic/claude-opus-4.1 Entre sus modelos compatibles, por lo que puede enrutar solicitudes a través de la API de CometAPI, los modelos específicos para el código del cursor también están disponibles.
Para comenzar, explore las capacidades del modelo en el Playground y consultar el Claude Opus 4.1 Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API".
URL base: https://api.cometapi.com/v1/chat/completions
Parámetro del modelo:
"claude-opus-4-1-20250805"→ Opus 4.1 estándar"claude-opus-4-1-20250805-thinking"→ Opus 4.1 con razonamiento extendido habilitadocometapi-opus-4-1-20250805→Exclusiva de CometAPI. Versión estándar diseñada específicamente para cursor de contactocometapi-opus-4-1-20250805-thinking→ Exclusivo de CometAPI. Versión de razonamiento extendido específicamente para cursor de contacto
En resumenClaude Opus 4.1 se basa en las fortalezas de Opus 4.0 al ofrecer mejoras específicas en la precisión de la codificación, el razonamiento agéntico y el rendimiento de la infraestructura, sin aumentar los costos ni alterar las vías de integración. Ya sea que esté refinando bases de código complejas, orquestando flujos de trabajo de agentes autónomos o generando información empresarial de alta calidad, Opus 4.1 ofrece una actualización convincente que equilibra precisión y versatilidad. A medida que el panorama de la IA continúa acelerándose, el ritmo constante de mejoras de Anthropic posiciona a Claude Opus como la opción predilecta para las organizaciones que buscan aprovechar las capacidades más avanzadas de los modelos de lenguaje.