

En los últimos meses se ha producido un rápido auge de la programación agentiva: modelos especializados que no solo responden a solicitudes puntuales, sino que planifican, editan, prueban e iteran en repositorios completos. Dos de los ejemplos más destacados son Compositor, un modelo de codificación de baja latencia diseñado específicamente para este fin, introducido por Cursor con su versión Cursor 2.0, y Códice GPT-5La variante de GPT-5 de OpenAI, optimizada para agentes y ajustada para flujos de trabajo de codificación sostenidos, ilustra las nuevas líneas divisorias en las herramientas para desarrolladores: velocidad frente a profundidad, conocimiento del espacio de trabajo local frente a razonamiento generalista, y la comodidad de la "codificación intuitiva" frente al rigor de la ingeniería.
De un vistazo: diferencias cara a cara
- Intención de diseño: GPT-5-Codex: razonamiento profundo y agente, y robustez para sesiones largas y complejas; Composer: iteración ágil y consciente del espacio de trabajo, optimizada para la velocidad.
- Superficie de integración primaria: GPT-5-Codex — Producto Codex/API de respuestas, IDE, integraciones empresariales; Composer — Editor de cursores e interfaz de usuario multiagente de cursores.
- Latencia/iteración: Composer hace hincapié en los giros de menos de 30 segundos y afirma grandes ventajas de velocidad; GPT-5-Codex prioriza la minuciosidad y las carreras autónomas de varias horas cuando sea necesario.
Probé el API del códice GPT-5 modelo proporcionado por CometAPI (un proveedor de agregación de API de terceros, cuyos precios de API son generalmente más baratos que los oficiales), resumió mi experiencia utilizando el modelo Composer de Cursor 2.0 y comparó los dos en varias dimensiones de juicio de generación de código.
¿Qué son Composer y el códec GPT-5?
¿Qué es el GPT-5-Codex y qué problemas pretende resolver?
GPT-5-Codex de OpenAI es una versión especializada de GPT-5 que, según OpenAI, está optimizada para escenarios de codificación automatizada: ejecución de pruebas, edición de código a escala de repositorio e iteración autónoma hasta superar las comprobaciones. Su enfoque principal reside en su amplia capacidad para diversas tareas de ingeniería: razonamiento profundo para refactorizaciones complejas, operación automatizada a largo plazo (donde el modelo puede dedicar desde minutos hasta horas al razonamiento y las pruebas) y un rendimiento superior en pruebas de referencia estandarizadas diseñadas para reflejar problemas de ingeniería reales.
¿Qué es Composer y qué problemas pretende resolver?
Composer es el primer modelo de codificación nativo de Cursor, presentado con Cursor 2.0. Cursor describe Composer como un modelo vanguardista, centrado en agentes, diseñado para una baja latencia y una iteración rápida en los flujos de trabajo de los desarrolladores: planificación de diferencias entre múltiples archivos, aplicación de búsqueda semántica en todo el repositorio y finalización de la mayoría de las tareas en menos de 30 segundos. Se entrenó con acceso a herramientas en el bucle (entornos de búsqueda, edición y prueba) para ser eficiente en tareas de ingeniería prácticas y minimizar la fricción de los ciclos repetidos de solicitud-respuesta en la codificación diaria. Cursor posiciona a Composer como un modelo optimizado para la velocidad de los desarrolladores y los bucles de retroalimentación en tiempo real.
Alcance del modelo y comportamiento en tiempo de ejecución
- Compositor: Optimizado para interacciones rápidas y centradas en el editor, y para garantizar la coherencia entre múltiples archivos. La integración de Cursor a nivel de plataforma permite a Composer tener un mayor acceso al repositorio y participar en la orquestación multiagente (por ejemplo, dos agentes de Composer frente a otros), lo que, según Cursor, reduce las dependencias no detectadas entre archivos.
- Códice GPT-5: Optimizado para un razonamiento más profundo y de longitud variable. OpenAI destaca la capacidad del modelo para priorizar un razonamiento más profundo sobre el tiempo de cómputo cuando sea necesario —desde segundos para tareas sencillas hasta horas para ejecuciones autónomas extensas—, lo que permite refactorizaciones más exhaustivas y una depuración guiada por pruebas.
Versión corta: Composer = Modelo de codificación integrado en el IDE de Cursor, que tiene en cuenta el espacio de trabajo; GPT-5-Codex = Variante especializada de GPT-5 de OpenAI para ingeniería de software, disponible a través de Responses/Codex.
¿Cómo se comparan en velocidad Composer y GPT-5-Codex?
¿Qué alegaron los vendedores?
Cursor posiciona a Composer como un codificador de vanguardia: las cifras publicadas destacan su rendimiento de generación, medido en tokens por segundo, y afirman tiempos de finalización interactiva de 2 a 4 veces más rápidos que los modelos de vanguardia en el entorno interno de Cursor. Informes independientes (prensa y pruebas iniciales) indican que Composer genera código a una velocidad de entre 200 y 250 tokens por segundo en el entorno de Cursor y que, en muchos casos, completa tareas de codificación interactivas típicas en menos de 30 segundos.
El GPT-5-Codex de OpenAI no está concebido como un experimento de latencia; prioriza la robustez y un razonamiento más profundo y, en cargas de trabajo comparables de alto razonamiento, puede ser más lento cuando se utiliza en tamaños de contexto más grandes, según informes de la comunidad y hilos de problemas.
Cómo evaluamos la velocidad (metodología)
Para realizar una comparación de velocidad justa, debe controlar el tipo de tarea (finalizaciones rápidas frente a razonamientos largos), el entorno (latencia de red, integración local frente a integración en la nube) y medir ambos. tiempo hasta el primer resultado útil y reloj de pared de extremo a extremo (incluidos los pasos de ejecución o compilación de pruebas). Puntos clave:
- Tareas elegidas — Generación de fragmentos pequeños (implementación de un punto final de API), tarea mediana (refactorizar un archivo y actualizar las importaciones), tarea grande (implementar una función en tres archivos, actualizar las pruebas).
- Métrica — tiempo hasta el primer token, tiempo hasta la primera diferencia útil (tiempo hasta que se emite el parche candidato) y tiempo total incluyendo la ejecución y verificación de las pruebas.
- Repeticiones — cada tarea se ejecuta 10 veces, y se utiliza la mediana para reducir el ruido de la red.
- Medio Ambiente — mediciones tomadas de una máquina de desarrollador en Tokio (para reflejar la latencia del mundo real) con un enlace estable de 100/10 Mbps; los resultados variarán según la región.
A continuación se muestra un ejemplo reproducible. arnés de velocidad para GPT-5-Codex (API de respuestas) y una descripción de cómo medir Composer (dentro de Cursor).
Acelerador de velocidad (Node.js) — GPT-5-Codex (API de respuestas):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
Esto mide la latencia de solicitud de extremo a extremo para GPT-5-Codex utilizando la API de respuestas pública (la documentación de OpenAI describe la API de respuestas y el uso del modelo gpt-5-codex).
Cómo medir la velocidad de Composer (Cursor):
Composer se ejecuta dentro de Cursor 2.0 (versión de escritorio/VS Code). Cursor no proporciona (al momento de escribir este texto) una API HTTP externa general para Composer que se ajuste a la API de respuestas de OpenAI; la fortaleza de Composer reside en Integración de espacio de trabajo con estado en el IDEPor lo tanto, mida Composer como lo haría un desarrollador humano:
- Abre el mismo proyecto dentro de Cursor 2.0.
- Utilice Composer para ejecutar la misma solicitud como una tarea de agente (crear ruta, refactorizar, cambio de varios archivos).
- Inicie un cronómetro cuando envíe el plan de Composer; deténgalo cuando Composer emita la diferencia atómica y ejecute el conjunto de pruebas (la interfaz de Cursor puede ejecutar pruebas y mostrar una diferencia consolidada).
- Repita 10 veces y utilice la mediana.
Los materiales publicados por Cursor y las reseñas prácticas muestran que Composer completa muchas tareas comunes en menos de ~30 segundos en la práctica; este es un objetivo de latencia interactiva en lugar del tiempo de inferencia del modelo en bruto.
Para llevar: El objetivo de diseño de Composer es la edición interactiva rápida dentro de un editor; si su prioridad son los ciclos de codificación conversacionales con baja latencia, Composer está diseñado para ese caso de uso. GPT-5-Codex está optimizado para la precisión y el razonamiento automatizable en sesiones más largas; puede sacrificar algo más de latencia a cambio de una planificación más profunda. Las cifras del proveedor respaldan esta estrategia.
¿Cómo se comparan Composer y GPT-5-Codex en cuanto a precisión?
Qué significa precisión en la programación de IA
La precisión en este caso es multifacética: corrección funcional (¿El código compila y pasa las pruebas?) corrección semántica (¿El comportamiento cumple con las especificaciones?), y robustez (Aborda casos límite y problemas de seguridad).
Números de proveedores y prensa
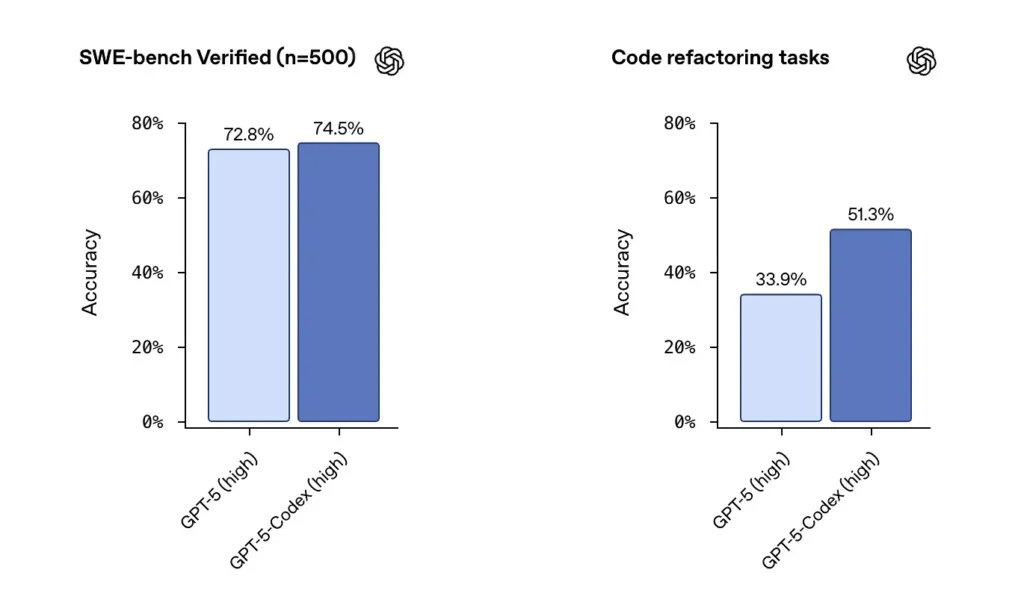
OpenAI informa del sólido rendimiento de GPT-5-Codex en conjuntos de datos verificados por SWE-bench y destacó un tasa de éxito 74.5% en una prueba de referencia de codificación del mundo real (informada en la prensa) y un aumento notable en el éxito de la refactorización (51.3% frente a 33.9 para GPT-5 base en su prueba de refactorización interna).
El lanzamiento de Cursor indica que Composer suele destacar en ediciones con múltiples archivos y sensibles al contexto, donde la integración del editor y la visibilidad del repositorio son cruciales. Tras mis pruebas, constaté que Composer generó menos errores de dependencias no detectadas durante las refactorizaciones de múltiples archivos y obtuvo mejores resultados en las pruebas de revisión a ciegas para ciertas cargas de trabajo con múltiples archivos. Las características de latencia y agentes paralelos de Composer también me ayudan a mejorar la velocidad de iteración.
Pruebas de precisión independientes (método recomendado)
Una prueba justa utiliza una combinación de:
- Pruebas unitarias: proporcionar el mismo repositorio y conjunto de pruebas a ambos modelos; generar código, ejecutar pruebas.
- Pruebas de refactorización: proporcionar una función intencionalmente desordenada y pedirle al modelo que la refactorice y agregue pruebas.
- Revisiones de seguridad: ejecutar análisis estático y herramientas SAST en el código generado (por ejemplo, Bandit, ESLint, semgrep).
- Revisión humana: puntuaciones de revisión de código realizadas por ingenieros experimentados en cuanto a mantenibilidad y mejores prácticas.
Ejemplo: entorno de pruebas automatizadas (Python): ejecuta el código generado y las pruebas unitarias.
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
Utilice este patrón para comprobar automáticamente si la salida del modelo es funcionalmente correcta (si supera las pruebas). Para tareas de refactorización, ejecute el framework con el repositorio original y las diferencias del modelo, y compare los porcentajes de éxito de las pruebas y los cambios en la cobertura.
Para llevar: En pruebas de rendimiento sin procesar, GPT-5-Codex ofrece excelentes resultados y una gran capacidad de refactorización. En flujos de trabajo reales de edición y reparación de múltiples archivos, la gestión del espacio de trabajo de Composer puede generar una mayor aceptación práctica y menos errores mecánicos (importaciones faltantes, nombres de archivo incorrectos). Para lograr la máxima corrección funcional en tareas algorítmicas de un solo archivo, GPT-5-Codex es una opción sólida; para cambios en múltiples archivos que requieren seguir convenciones dentro de un IDE, Composer suele destacar.
Composer vs GPT-5: ¿Cómo se comparan en cuanto a calidad de código?
¿Qué se considera calidad?
La calidad incluye legibilidad, nomenclatura, documentación, cobertura de pruebas, uso de patrones idiomáticos y buenas prácticas de seguridad. Se mide tanto automáticamente (mediante analizadores de código estático y métricas de complejidad) como cualitativamente (mediante revisión humana).
Diferencias observadas
- Códice GPT-5Posee gran capacidad para generar patrones idiomáticos cuando se le solicita explícitamente; destaca por su claridad algorítmica y puede generar conjuntos de pruebas completos cuando se le pide. Las herramientas Codex de OpenAI incluyen registros integrados de pruebas, informes y ejecución.
- CompositorOptimizado para observar automáticamente el estilo y las convenciones de un repositorio, Composer puede seguir los patrones de proyecto existentes y coordinar las actualizaciones de múltiples archivos (propagación de nombres/refactorizaciones, importación de actualizaciones). Ofrece una excelente mantenibilidad bajo demanda para proyectos grandes.
Ejemplos de comprobaciones de calidad de código que puedes ejecutar
- linters — ESLint / pylint
- Complejidad: — radón / complejidad de escamas8
- Seguridad — semgrep / Bandido
- Cobertura de prueba — Ejecuta coverage.py o vitest/nyc para JS
Automatice estas comprobaciones tras aplicar el parche al modelo para cuantificar las mejoras o los retrocesos. Ejemplo de secuencia de comandos (repositorio JS):
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
Revisión humana y mejores prácticas
En la práctica, los modelos requieren instrucciones para seguir las mejores prácticas: solicitar docstrings, anotaciones de tipo, fijación de dependencias o patrones específicos (p. ej., async/await). GPT-5-Codex funciona de maravilla con directivas explícitas; Composer se beneficia del contexto implícito del repositorio. Utilice un enfoque combinado: indique el modelo explícitamente y deje que Composer aplique el estilo del proyecto si está dentro de Cursor.
Recomendación: Para trabajos de ingeniería con múltiples archivos dentro de un IDE, prefiera Composer; para pipelines externos, tareas de investigación o automatización de cadenas de herramientas donde pueda llamar a una API y proporcionar un contexto amplio, GPT-5-Codex es una opción sólida.
Opciones de integración y despliegue
Composer se incluye en Cursor 2.0, integrado en el editor y la interfaz de usuario de Cursor. El enfoque de Cursor prioriza un único plano de control del proveedor que ejecuta Composer junto con otros modelos, lo que permite a los usuarios ejecutar múltiples instancias de modelos en la misma línea de comandos y comparar los resultados dentro del editor. ()
GPT-5-Codex se está integrando en la oferta Codex de OpenAI y en la familia de productos ChatGPT, estando disponible a través de los planes de pago de ChatGPT y una API que plataformas de terceros como CometAPI ofrecen con una mejor relación calidad-precio. OpenAI también está integrando Codex en las herramientas para desarrolladores y los flujos de trabajo de sus socios en la nube (por ejemplo, integraciones con Visual Studio Code y GitHub Copilot).
¿Hacia dónde podrían impulsar Composer y GPT-5-Codex la industria en el futuro?
Efectos a corto plazo
- Ciclos de iteración más rápidos: Los modelos con editores integrados, como Composer, reducen la fricción en las pequeñas correcciones y la generación de solicitudes de extracción.
- Expectativas crecientes en materia de verificación: El énfasis de Codex en las pruebas, los registros y la capacidad autónoma impulsará a los proveedores a ofrecer una verificación preconfigurada más sólida para el código generado por modelos.
A medio y largo plazo
- La orquestación multimodal se convierte en algo normal: La interfaz gráfica de usuario multiagente de Cursor es un indicio temprano de que los ingenieros pronto esperarán ejecutar varios agentes especializados en paralelo (análisis de código, seguridad, refactorización, optimización del rendimiento) y aceptar los mejores resultados.
- Ciclos de retroalimentación CI/IA más ajustados: A medida que mejoran los modelos, los pipelines de CI incorporarán cada vez más la generación de pruebas basadas en modelos y sugerencias de reparación automatizadas, pero la revisión humana y el despliegue por etapas siguen siendo cruciales.
Conclusión
Composer y GPT-5-Codex no son armas idénticas en la misma carrera armamentística; son herramientas complementarias optimizadas para diferentes etapas del ciclo de vida del software. La propuesta de valor de Composer reside en la velocidad: iteración rápida y basada en el espacio de trabajo que mantiene a los desarrolladores concentrados en el proceso. El valor de GPT-5-Codex radica en la profundidad: persistencia activa, corrección basada en pruebas y auditabilidad para transformaciones complejas. La estrategia de ingeniería pragmática consiste en orquestar ambosSe utilizan agentes tipo Composer de bucle corto para el flujo de trabajo diario y agentes estilo GPT-5-Codex para operaciones controladas de alta confianza. Las primeras pruebas de rendimiento sugieren que ambos formarán parte del conjunto de herramientas de desarrollo a corto plazo, en lugar de que uno sustituya al otro.
No existe un único ganador objetivo en todas las dimensiones. Los modelos intercambian puntos fuertes:
- Códice GPT-5: Es más eficaz en pruebas de corrección exhaustivas, razonamiento de gran alcance y flujos de trabajo autónomos de varias horas. Destaca cuando la complejidad de la tarea requiere un razonamiento prolongado o una verificación rigurosa.
- Compositor: Es más eficaz en casos de uso con integración estricta en el editor, ofrece consistencia contextual en múltiples archivos y permite una iteración rápida dentro del entorno de Cursor. Puede ser mejor para la productividad diaria de los desarrolladores cuando se necesitan ediciones inmediatas, precisas y contextuales.
Vea también Cursor 2.0 y Composer: cómo un replanteamiento multiagente sorprendió la programación de IA
Primeros Pasos
CometAPI es una plataforma API unificada que integra más de 500 modelos de IA de proveedores líderes, como la serie GPT de OpenAI, Gemini de Google, Claude de Anthropic, Midjourney, Suno y más, en una única interfaz intuitiva para desarrolladores. Al ofrecer autenticación, formato de solicitudes y gestión de respuestas consistentes, CometAPI simplifica drásticamente la integración de las capacidades de IA en sus aplicaciones. Ya sea que esté desarrollando chatbots, generadores de imágenes, compositores musicales o canales de análisis basados en datos, CometAPI le permite iterar más rápido, controlar costos y mantenerse independiente del proveedor, todo mientras aprovecha los últimos avances del ecosistema de IA.
Los desarrolladores pueden acceder API del códice GPT-5a través de CometAPI, la última versión del modelo Se actualiza constantemente con el sitio web oficial. Para empezar, explora las capacidades del modelo en el Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API". CometAPI Ofrecemos un precio muy inferior al oficial para ayudarte a integrarte.
¿Listo para ir?→ Regístrate en CometAPI hoy !
Si quieres conocer más consejos, guías y novedades sobre IA síguenos en VK, X y Discord!