

GLM-4.6 es el último lanzamiento importante de la familia GLM de Z.ai (anteriormente Zhipu AI): un lenguaje grande de cuarta generación Modelo MoE (mezcla de expertos) sintonizado para Flujos de trabajo de agentes, razonamiento de contexto largo y codificación del mundo realEl lanzamiento enfatiza la integración práctica de agentes y herramientas, una gran ventana de contextoy disponibilidad de peso abierto para implementación local.
Características principales
- Contexto largo - nativo Ficha de 200K ventana contextual (ampliada de 128K). ()
- Codificación y capacidad de agencia — se comercializaron mejoras en tareas de codificación del mundo real y una mejor invocación de herramientas para los agentes.
- Eficiencia — informó ~30% menos de consumo de tokens vs GLM-4.5 en las pruebas de Z.ai.
- Despliegue y cuantificación —Se anunció por primera vez la integración de FP8 e Int4 para chips Cambricon; soporte nativo de FP8 en Moore Threads a través de vLLM.
- Tamaño del modelo y tipo de tensor — los artefactos publicados indican una parámetro ~357B modelo (tensores BF16/F32) en Hugging Face.
Detalles técnicos
Modalidades y formatos. GLM-4.6 es un solo texto LLM (modalidades de entrada y salida: texto). Longitud del contexto = 200 000 tokens; salida máxima = 128K tokens.
Cuantización y soporte de hardware. El equipo informa Cuantización FP8/Int4 en chips Cambricon y FP8 nativo ejecución en GPU Moore Threads usando vLLM para inferencia, importante para reducir el costo de inferencia y permitir implementaciones locales y en la nube.
Herramientas e integraciones. GLM-4.6 se distribuye a través de la API de Z.ai, redes de proveedores externos (por ejemplo, CometAPI) y se integra en agentes de codificación (Claude Code, Cline, Roo Code, Kilo Code).
Detalles técnicos
Modalidades y formatos. GLM-4.6 es un solo texto LLM (modalidades de entrada y salida: texto). Longitud del contexto = 200 000 tokens; salida máxima = 128K tokens.
Cuantización y soporte de hardware. El equipo informa Cuantización FP8/Int4 en chips Cambricon y FP8 nativo ejecución en GPU Moore Threads usando vLLM para inferencia, importante para reducir el costo de inferencia y permitir implementaciones locales y en la nube.
Herramientas e integraciones. GLM-4.6 se distribuye a través de la API de Z.ai, redes de proveedores externos (por ejemplo, CometAPI) y se integra en agentes de codificación (Claude Code, Cline, Roo Code, Kilo Code).
Rendimiento de referencia
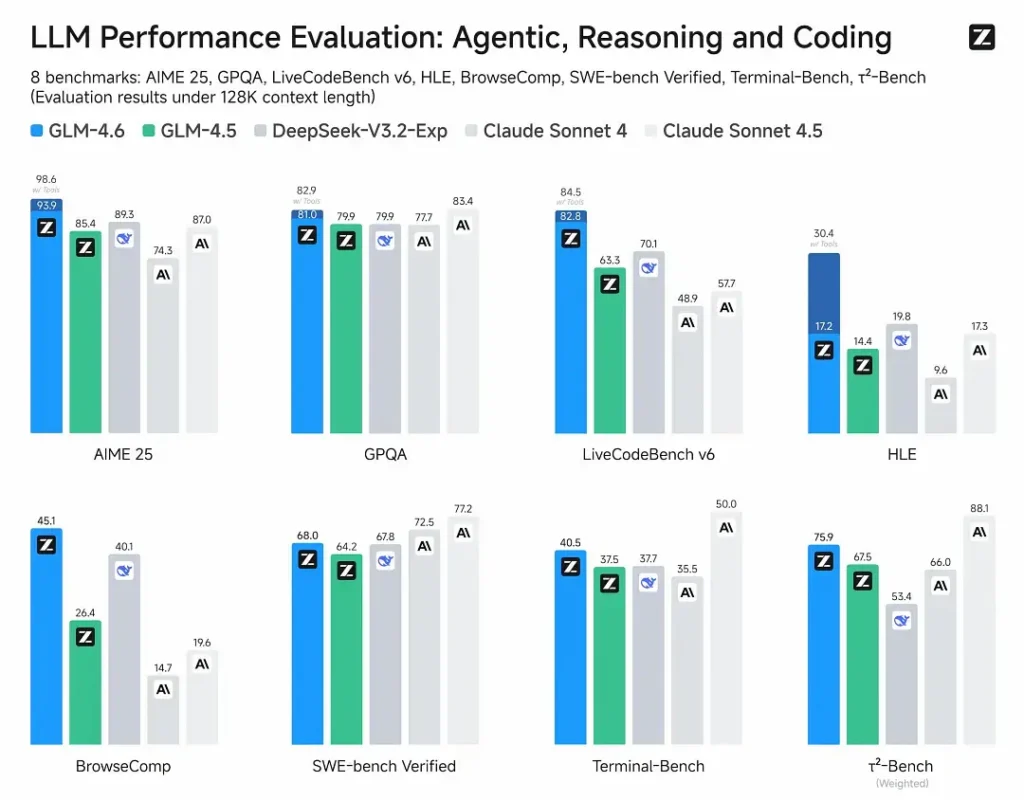
- Evaluaciones publicadas: GLM-4.6 se probó en ocho puntos de referencia públicos que cubren agentes, razonamiento y codificación y muestra claras ganancias sobre GLM-4.5En pruebas de codificación del mundo real evaluadas por humanos (CC-Bench extendido), GLM-4.6 utiliza ~15% menos tokens vs GLM-4.5 y publica un ~48.6% de tasa de victorias vs Anthropic Soneto de Claude 4 (casi paridad en muchas tablas de clasificación).
- posicionamiento: Los resultados afirman que GLM-4.6 es competitivo con los principales modelos nacionales e internacionales (los ejemplos citados incluyen DeepSeek-V3.1 y Claude Sonnet 4).
Limitaciones y riesgos
- Alucinaciones y errores: Al igual que todos los LLM actuales, GLM-4.6 puede cometer, y de hecho comete, errores factuales. La documentación de Z.ai advierte explícitamente que los resultados pueden contener errores. Los usuarios deben aplicar la verificación y recuperación/RAG para el contenido crítico.
- Complejidad del modelo y coste del servicio: Un contexto de 200K y salidas muy grandes aumentan drásticamente las demandas de memoria y latencia y pueden incrementar los costos de inferencia; se requiere ingeniería cuantificada/de inferencia para ejecutar a escala.
- Brechas de dominio: Si bien GLM-4.6 informa un sólido rendimiento de agente/codificación, algunos informes públicos señalan que aún se retrasa en ciertas versiones de modelos competitivos en microbenchmarks específicos (p. ej., algunas métricas de codificación frente a Sonnet 4.5). Evalúe cada tarea antes de reemplazar los modelos de producción.
- Seguridad y política: Los pesos abiertos aumentan la accesibilidad pero también plantean cuestiones de gestión (las mitigaciones, las barreras de seguridad y los equipos rojos siguen siendo responsabilidad del usuario).
Casos de uso
- Sistemas agentes y orquestación de herramientas: trazas de agente largas, planificación de múltiples herramientas, invocación dinámica de herramientas; el ajuste agente del modelo es un argumento de venta clave.
- Asistentes de codificación del mundo real: Generación de código multiturno, revisión de código y asistentes IDE interactivos (integrados en Claude Code, Cline, Roo Code—según Z.ai). Mejoras en la eficiencia de los tokens hacerlo atractivo para planes de desarrolladores de uso intensivo.
- Flujos de trabajo de documentos largos: resumen, síntesis de múltiples documentos, largas revisiones técnicas y legales debido a la ventana de 200K.
- Creación de contenidos y personajes virtuales: diálogos extendidos, mantenimiento consistente de la personalidad en escenarios de múltiples turnos.
Cómo se compara GLM-4.6 con otros modelos
- GLM-4.5 → GLM-4.6: cambio radical en tamaño del contexto (128K → 200K) y Eficiencia del token (aproximadamente un 15 % menos de tokens en CC-Bench); uso mejorado del agente/herramienta.
- GLM-4.6 frente a Claude Sonnet 4 / Sonnet 4.5: Informes de Z.ai casi paridad en varias tablas de clasificación y una tasa de éxito de aproximadamente el 48.6 % en las tareas de codificación reales de CC-Bench (es decir, una competencia reñida, con algunos microbenchmarks donde Sonnet aún lidera). Para muchos equipos de ingeniería, GLM-4.6 se posiciona como una alternativa rentable.
- GLM-4.6 frente a otros modelos de contexto largo (DeepSeek, variantes de Gemini, familia GPT-4): GLM-4.6 enfatiza los flujos de trabajo de codificación de contexto amplio y agente; las fortalezas relativas dependen de la métrica (eficiencia de tokens/integración de agentes vs. precisión de síntesis de código sin procesar o canales de seguridad). La selección empírica debe basarse en las tareas.
Lanzamiento del último modelo estrella de Zhipu AI, el GLM-4.6: 355 000 millones de parámetros totales y 32 000 millones de activos. Supera al GLM-4.5 en todas sus capacidades principales.
- Codificación: se alinea con Soneto de Claude 4, el mejor en China.
- Contexto: Ampliado a 200K (desde 128K).
- Razonamiento: mejorado, admite llamada de herramientas durante la inferencia.
- Búsqueda: Llamada de herramientas mejorada y rendimiento del agente.
- Escritura: Se adapta mejor a las preferencias humanas en cuanto a estilo, legibilidad y juego de roles.
- Multilingüe: Traducción entre idiomas mejorada.
Como llamar GLM–**4.**6 API de CometAPI
GLM‑4.6 Precios de API en CometAPI: 20 % de descuento sobre el precio oficial.
- Tokens de entrada: $0.64 millones de tokens
- Tokens de salida: $2.56/M tokens
Pasos requeridos
- Inicia sesión en cometapi.comSi aún no eres nuestro usuario, por favor regístrate primero.
- Accede a tu Consola CometAPI.
- Obtenga la clave API de credenciales de acceso de la interfaz. Haga clic en "Agregar token" en el token API del centro personal, obtenga la clave del token: sk-xxxxx y envíe.

Método de uso
- Seleccione la opción "
glm-4.6Punto final para enviar la solicitud de API y configurar el cuerpo de la solicitud. El método y el cuerpo de la solicitud se obtienen de la documentación de la API de nuestro sitio web. Nuestro sitio web también ofrece la prueba de Apifox para su comodidad. - Reemplazar con su clave CometAPI real de su cuenta.
- Inserte su pregunta o solicitud en el campo de contenido: esto es lo que responderá el modelo.
- . Procesa la respuesta de la API para obtener la respuesta generada.
CometAPI proporciona una API REST totalmente compatible para una migración fluida. Detalles clave para Documento API:
- URL base: https://api.cometapi.com/v1/chat/completions
- Nombres de modelos: "
glm-4.6" - Autenticación:
Bearer YOUR_CometAPI_API_KEYencabezamiento - Tipo de contenido:
application/json.
Integración de API y ejemplos
A continuación se muestra un Python Fragmento que muestra cómo invocar GLM‑4.6 mediante la API de CometAPI. Reemplazar <API_KEY> y <PROMPT> en consecuencia:
import requests
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer <API_KEY>",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "<PROMPT>"}
],
"max_tokens": 512,
"temperature": 0.7
}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json())
Parámetros clave:
- modelo: Especifica la variante GLM‑4.6
- tokens_max:Controla la longitud de salida
- temperatura:Ajusta la creatividad frente al determinismo
Vea también Soneto de Claude 4.5