

El lanzamiento de GLM-5, presentado esta semana por Zhipu AI de China (con marca pública como Z.AI / zai-org en muchos canales para desarrolladores), marca otro paso en el ritmo acelerado de lanzamientos de modelos grandes. El nuevo modelo se posiciona como el buque insignia de Zhipu: de mayor escala, afinado para tareas agénticas de largo horizonte y construido con decisiones de ingeniería destinadas a reducir el coste de inferencia preservando un contexto largo. Los primeros informes del sector y notas prácticas de desarrolladores sugieren avances significativos en programación, razonamiento de múltiples pasos y orquestación de agentes en comparación con iteraciones previas de GLM — y en algunas pruebas incluso desafía a Claude 4.5.
¿Qué es GLM-5 y quién lo construyó?
GLM-5 es la última gran versión de la familia GLM: un modelo fundacional grande y de código abierto desarrollado y publicado por Z.ai (el equipo detrás de la serie GLM). Anunciado a principios de febrero de 2026, GLM-5 se presenta como un modelo de próxima generación específicamente afinado para tareas “agénticas”, es decir, flujos de trabajo de múltiples pasos y largo horizonte donde un modelo debe planificar, llamar herramientas, ejecutar y mantener el contexto durante conversaciones extendidas o agentes automatizados. El lanzamiento es notable no solo por el diseño del modelo, sino también por cómo y dónde se entrenó: Z.ai utilizó una combinación de hardware y cadenas de herramientas nacionales chinas como parte de un impulso hacia la autosuficiencia.
Las cifras reportadas de arquitectura y entrenamiento incluyen:
- Escalado de parámetros: GLM-5 escala hasta aproximadamente 744B parámetros (con un recuento de expertos “activos” más pequeño citado en algunas notas técnicas, p. ej., 40B activos), frente a tamaños de la familia GLM-4 anteriores alrededor de 355B/32B activos.
- Datos de preentrenamiento: El tamaño del corpus de entrenamiento aumentó supuestamente de ~23 billones de tokens (generación GLM-4) a ~28.5 billones de tokens para GLM-5.
- Atención dispersa / DeepSeek Sparse Attention (DSA): Un esquema de atención dispersa para preservar el contexto largo mientras reduce el coste computacional durante la inferencia.
- Énfasis de diseño: decisiones de ingeniería centradas en la orquestación de agentes, el razonamiento de largo contexto y la inferencia rentable.
Orígenes y posicionamiento
GLM-5 se basa en una línea que incluyó GLM-4.5 (lanzado a mediados de 2025) y algunas actualizaciones iterativas como 4.7. Z.ai posiciona GLM-5 como un salto desde el “vibe coding” (salidas de código rápidas de un solo paso) hacia la “ingeniería agéntica”: razonamiento sostenido, orquestación multiherramienta y síntesis de sistemas a lo largo de ventanas de contexto prolongadas. El material público enfatiza que GLM-5 fue diseñado para manejar tareas complejas de ingeniería de sistemas — construir, coordinar y mantener comportamientos de agentes de múltiples pasos en lugar de solo responder consultas aisladas.
¿Cuáles son las novedades de GLM-5?
Cambios arquitectónicos principales
- Escalado disperso masivo (MoE): GLM-5 adopta una arquitectura Mixture-of-Experts dispersa mucho más grande. Cifras públicas de páginas para desarrolladores y artículos independientes sitúan el modelo en aproximadamente 744B parámetros totales con ~40B activos por token — un salto significativo respecto a la configuración de ~355B / 32B activos de GLM-4.5. Este escalado disperso permite al modelo presentar una capacidad total muy grande manteniendo el cómputo por token manejable.
- DeepSeek Sparse Attention (DSA): Para preservar la capacidad de contexto largo sin escalar linealmente el coste de inferencia, GLM-5 integra un mecanismo de atención dispersa (con la marca DeepSeek) para mantener dependencias de largo alcance a escala mientras recorta el coste de la atención sobre contextos de longitud extrema.
Ingeniería agéntica como objetivo de diseño fundamental
Una de las características principales de GLM-5 es que está diseñado explícitamente para la ingeniería agéntica — es decir, el modelo está pensado no solo para chat de un turno o tareas de resumen, sino como el “cerebro” de agentes de múltiples pasos que pueden planificar, emitir llamadas a herramientas, gestionar estado y razonar a través de contextos largos. Z.ai posiciona GLM-5 para servir en bucles de orquestación: descomponer problemas complejos, llamar herramientas/APIs externas y seguir tareas largas durante muchos turnos.
Por qué importa el diseño agéntico
Los flujos de trabajo agénticos son centrales para la automatización en el mundo real: asistentes de investigación automatizados, ingenieros de software autónomos, orquestación de operaciones y control de simulaciones. Un modelo diseñado para este mundo necesita planificación sólida, comportamiento estable de llamadas a herramientas y robustez a lo largo de miles de tokens de contexto.
Mejora en programación, razonamiento y comportamiento de “largo horizonte”
GLM-5 enfatiza la mejora en generación de código y razonamiento. Z.ai afirma mejoras dirigidas en la capacidad del modelo para escribir, refactorizar y depurar código, además de un razonamiento multietapa más consistente en interacciones largas. Informes de acceso temprano independientes y evaluaciones de socios hallaron que el modelo es notablemente más fuerte en tareas orientadas a desarrolladores que generaciones previas de GLM.
Funciones prácticas para desarrolladores
- Ventanas de contexto más grandes para alojar documentación, bases de código y el estado de la conversación.
- Primitivas para invocar herramientas de forma segura y gestionar resultados.
- Mejor rendimiento en few-shot y chain-of-thought para descomponer y ejecutar tareas complejas.
- Funciones agénticas y llamadas a herramientas: GLM-5 enfatiza el soporte nativo para agentes: llamadas a funciones/herramientas, sesiones con estado y mejor gestión de diálogos largos y secuencias de uso de herramientas. Esto facilita la creación de agentes que integren búsqueda web, bases de datos o automatización de tareas.
¿Cómo rinde GLM-5 en benchmarks?
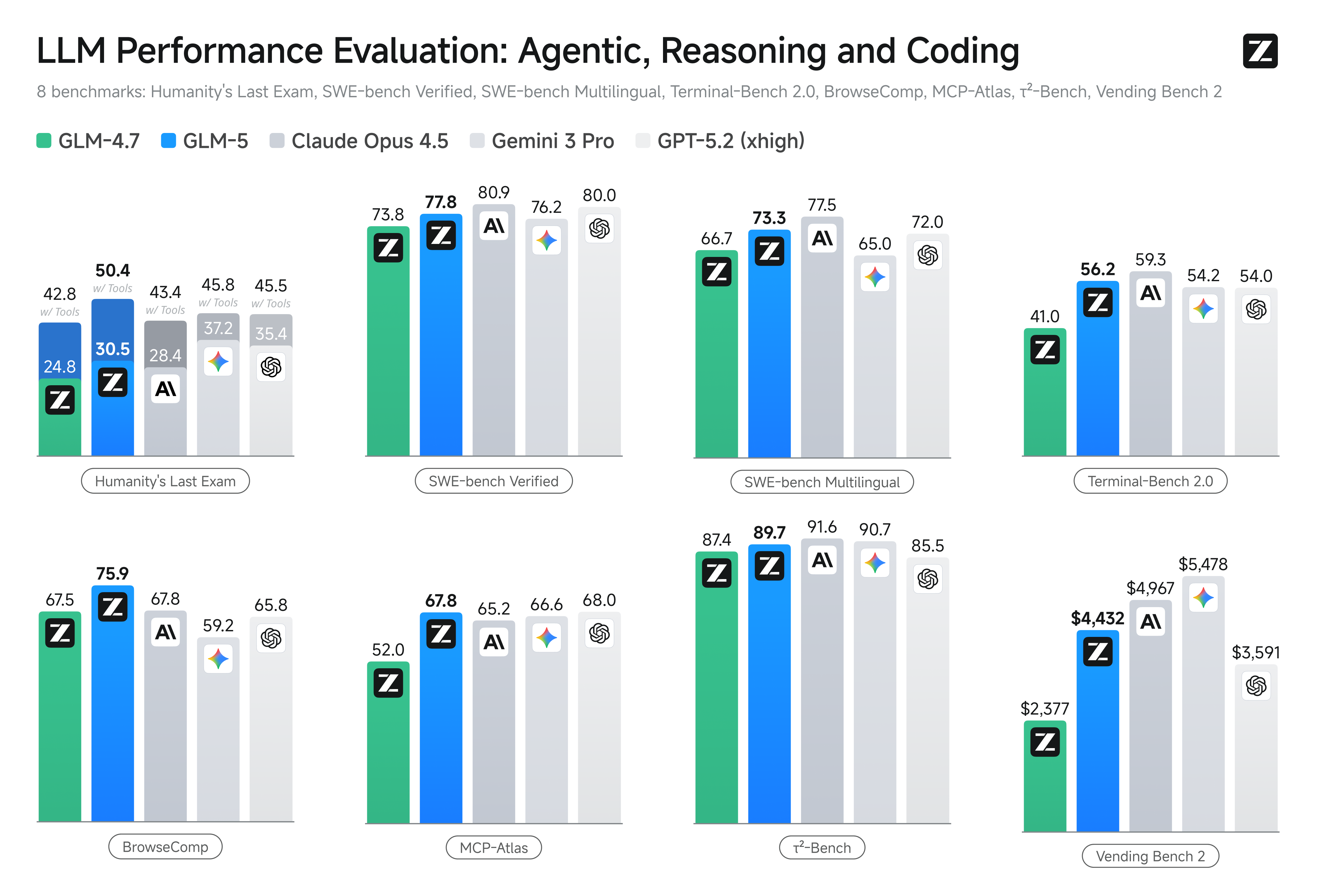
Aspectos destacados específicos de benchmarks
- Benchmarks de programación: GLM-5 se acerca (y en algunos casos iguala) el rendimiento en programación de modelos propietarios altamente optimizados como Claude Opus 4.5 de Anthropic en tareas de código específicas. Estos resultados dependen de la tarea (pruebas unitarias, programación algorítmica, uso de APIs), pero marcan una mejora clara frente a GLM-4.5.
- Pruebas de razonamiento y agénticas: En suites de evaluación de razonamiento multietapa y agénticas (p. ej., planificación multiturno, benchmarks de descomposición de tareas), GLM-5 logró resultados de referencia entre los modelos de código abierto y en algunas métricas superó a modelos cerrados competidores en tareas específicas.
¿Cómo acceder y probar GLM-5?
GLM-5 es la quinta generación del modelo de lenguaje grande de Zhipu AI (Z.ai), construido con una arquitectura Mixture-of-Experts (~745 B totales, ~44 B activos) y orientado a un fuerte razonamiento, programación y flujos de trabajo agénticos. Se lanzó oficialmente alrededor del 12 de febrero de 2026.
A día de hoy hay dos formas principales en que la gente está accediendo:
A) Acceso oficial por API (Z.ai o agregadores)
La propia Zhipu AI ofrece APIs para sus modelos y puedes llamar a GLM-5 a través de esas APIs.
Pasos típicos:
- Regístrate para una cuenta de Z.ai/Open BigModel API.
- Obtén una clave de API desde el panel.
- Usa un endpoint de estilo OpenAPI o REST con el nombre del modelo (p. ej.,
glm-5).
(Similar a cómo llamarías a modelos GPT de OpenAI). - Configura prompts y envía solicitudes HTTP.
👉 La página de precios de Z.ai muestra precios oficiales de tokens de GLM-5 como:
- ~$1.0 por millón de tokens de entrada
- ~$3.2 por millón de tokens de salida
B) Envoltorios de API de terceros ——CometAPI
APIs como CometAPI o WaveSpeed encapsulan múltiples modelos de IA (OpenAI, Claude, Z.ai, etc.) detrás de una interfaz unificada.
- Con servicios como CometAPI puedes llamar a modelos GLM cambiando el ID del modelo.
(CometAPI actualmente admite GLM-5/GLM-4.7.) - El glm-5 de CometAPI tiene un precio del 20% del precio oficial.
| Tipo de uso | Precio |
|---|---|
| Tokens de entrada | ~$0.8 por 1M tokens |
| Tokens de salida | ~$2.56 por 1M tokens |
Por qué esto importa: Mantienes tu código cliente compatible con OpenAI existente y solo cambias la URL base/ID del modelo.
C) Autoalojamiento vía Hugging Face / pesos
Hay repositorios no oficiales de pesos de GLM-5 (p. ej., versiones llamadas glm-5/glm-5-fp8) visibles en los listados de modelos de Hugging Face.
Con ellos puedes:
- Descargar los pesos del modelo.
- Usar herramientas como vLLM, SGLang, xLLM o Transformers para servir localmente o en tu flota de GPU en la nube.
Pros: control máximo, sin coste continuo de API.
Contras: requisitos de cómputo enormes — probablemente múltiples GPU de alta gama y memoria (varios cientos de GB), lo que lo hace poco práctico en sistemas pequeños.
Entonces, ¿vale la pena GLM-5 y deberías mantener GLM-4.7?
Respuesta corta (resumen ejecutivo)
- Si tu trabajo necesita un comportamiento agéntico robusto de múltiples pasos, generación de código de grado de producción o automatización a nivel de sistema: GLM-5 vale la pena evaluarlo de inmediato. Su arquitectura, escala y ajuste priorizan precisamente estos resultados.
- Si necesitas microservicios rentables y de alto rendimiento (chat corto, clasificación, prompts ligeros): GLM-4.7 probablemente sigue siendo la opción más económica. GLM-4.7 conserva un conjunto de capacidades sólido a un coste por token significativamente menor en muchos proveedores y ya está probado en producción.
Respuesta más larga (recomendación práctica)
Adopta una estrategia de modelos por niveles: usa GLM-4.7 para interacciones cotidianas y de alto volumen y reserva GLM-5 para problemas de ingeniería de alto valor y orquestación agéntica. Pilota GLM-5 en una pequeña porción del producto que ponga a prueba contexto largo, integración de herramientas y corrección de código; mide tanto el tiempo de ingeniería ahorrado como el coste incremental del modelo. Con el tiempo sabrás si la mejora de capacidad de GLM-5 justifica una migración más amplia.
Con CometAPI, puedes alternar entre GLM-4.7 y GLM-5 en cualquier momento.
Casos de uso reales donde GLM-5 destaca
1. Orquestación compleja de agentes
El enfoque de diseño de GLM-5 en planificación multietapa y llamadas a herramientas lo hace muy adecuado para sistemas que deben coordinar búsqueda, llamadas a APIs y ejecución de programas (por ejemplo: asistentes de investigación automatizados, generadores de código iterativos o agentes de atención al cliente de múltiples pasos que deban consultar bases de datos y APIs externas).
2. Ingeniería de formato largo y razonamiento sobre bases de código
Cuando necesitas que el modelo analice, refactorice o sintetice a través de muchos archivos o una base de código grande, el contexto ampliado de GLM-5 y su atención dispersa son ventajas directas — menos modos de fallo causados por contexto truncado y mejor consistencia en largos tramos.
3. Síntesis intensiva en conocimiento
Analistas y equipos de producto que generan informes complejos — resúmenes de investigación multisección, resúmenes legales o presentaciones regulatorias — pueden beneficiarse de las mejoras del modelo en razonamiento multietapa sostenido y la reducción de alucinaciones en pruebas reportadas por el proveedor.
4. Automatización agéntica para flujos de trabajo
Los equipos que construyen automatización que debe orquestar múltiples sistemas (p. ej., planificación + ticketing + pipelines de despliegue) pueden usar GLM-5 como planificador y ejecutor central, respaldado por frameworks de llamadas a herramientas y envoltorios de seguridad.
Conclusión
GLM-5 es un lanzamiento importante en el panorama en rápida evolución de los modelos frontera. Su énfasis en ingeniería agéntica, programación y razonamiento mejorados, y disponibilidad de pesos abiertos lo hace atractivo para equipos que construyen sistemas de IA de largo horizonte habilitados con herramientas. Ganancias reales en tareas seleccionadas y prometedoras compensaciones coste/rendimiento — pero los compradores deberían evaluar GLM-5 frente a sus tareas específicas y ejecutar sus propios benchmarks controlados antes de comprometerse a producción.
Los desarrolladores pueden acceder a GLM-5 a través de CometAPI ahora. Para comenzar, explora las capacidades del modelo en el Playground y consulta la guía de API para instrucciones detalladas. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y obtenido la clave de API. CometAPI ofrece un precio muy inferior al oficial para ayudarte a integrar.
¿Listo para comenzar?→ Sign up fo glm-5 today !
Si quieres conocer más consejos, guías y noticias sobre IA, síguenos en VK, X y Discord!