

Google DeepMind anunció hoy importantes expansiones de su familia Gemini 2.5, presentando las versiones estables de Gemini 2.5 Pro y Gemini 2.5 Flash, junto con una vista previa del nuevo modelo Gemini 2.5 Flash-Lite. Estas actualizaciones reflejan el compromiso continuo de Google de ofrecer una gama de modelos de IA que equilibran costo, velocidad y rendimiento para diversas cargas de trabajo.
Versiones estables: Gemini 2.5 Pro y Flash
El 17 de junio de 2025, Google anunció la disponibilidad general de Gemini 2.5 Pro y Gemini 2.5 Flash. La versión Pro ofrece la máxima capacidad de razonamiento y está diseñada para tareas de alta complejidad, como la generación avanzada de código, el análisis científico y la síntesis de datos a gran escala. Por otro lado, Gemini 2.5 Flash ofrece una opción de gama media optimizada para usos cotidianos que requieren baja latencia, ideal para chatbots, resúmenes y creación de contenido a gran escala.
Descripción general: Tres modelos de la familia Gemini -2.5
| Modelo | Estado | Ventajas | Casos de uso ideales |
|---|---|---|---|
| Gemini 2.5 Flash‑Lite (avance) | Vista previa | El más rápido y económico; multimodal; razonamiento controlable; habilitado por herramientas | Tareas de gran volumen como chatbots, resúmenes y búsquedas. |
| Géminis 2.5 Flash | Estable | Equilibrado: baja latencia, buen razonamiento, multimodal | Conversaciones en tiempo real, atención al cliente |
| Géminis 2.5 Pro | Estable | Más capaces: razonamiento profundo, amplio contexto, multimodal | Investigación, codificación compleja, tareas científicas |
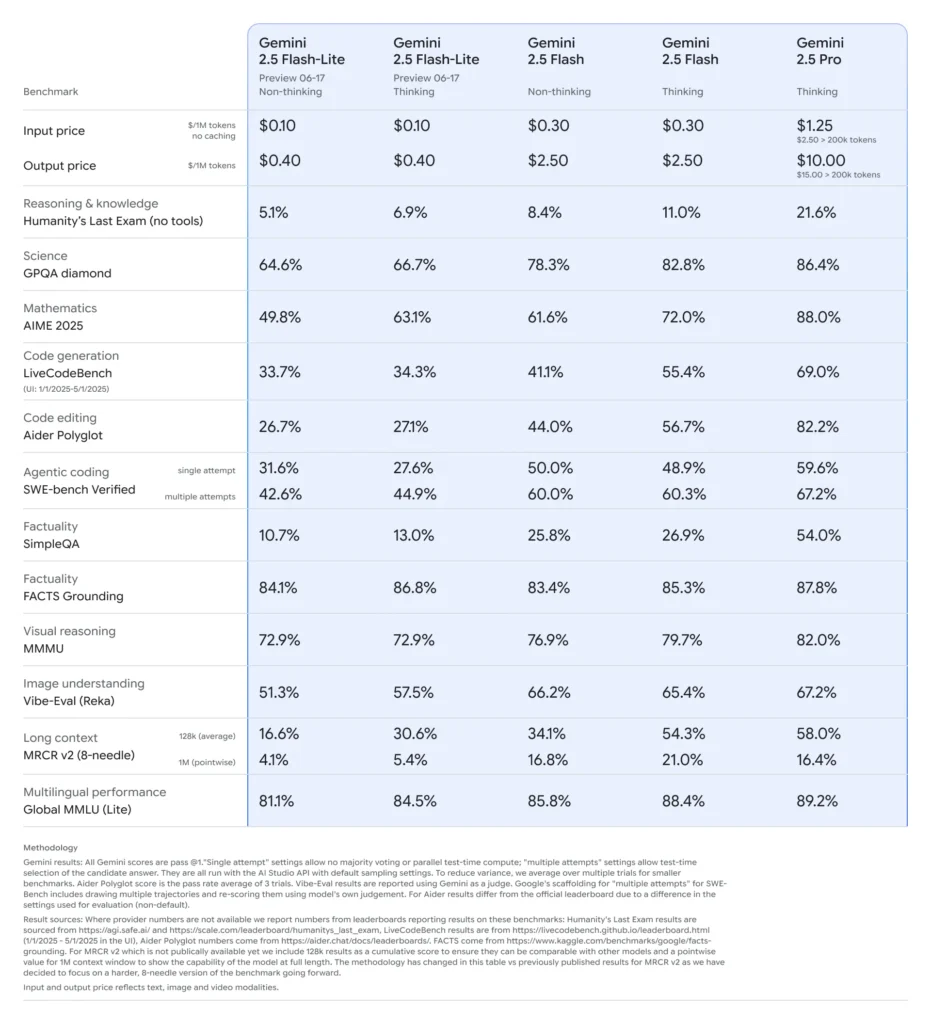
Gemini 2.5 Flash‑Lite: Aspectos destacados de la vista previa
Latencia ultrabaja y ahorro de costesDiseñado para aplicaciones de alto volumen en tiempo real, como traducción, clasificación y resumen. Ofrece una inferencia más rápida y un menor coste por llamada en comparación con Flash‑Lite 2.0 y la versión completa de Flash.
Rendimiento fundamental mejorado:Supera los modelos Flash-Lite anteriores en puntos de referencia de generación de código, lógica, matemáticas, razonamiento multimodal y ciencia.
Costo y eficienciaPrecios de Flash‑Lite (vista previa): ~$0.10 por 1 millón de tokens de entrada y ~$0.40 por 1 millón de tokens de salida, significativamente más barato que Flash ($0.30/$2.50) y Pro ($1.25/$10).
Capacidades completas de Gemini -2.5:
- Pensamiento controlable:Los usuarios pueden establecer “presupuestos de pensamiento” (límites de tokens) para intercambiar velocidad por profundidad. Flash-Lite puede activar esta opción según sea necesario.
- Entrada multimodal:Admite texto, imágenes, audio y vídeo (incluidos clips de una hora de duración), con capacidades para analizar gráficos, interfaz de usuario, escenas y resúmenes de eventos.
- Integración de herramientas:Incluye Búsqueda de Google, ejecución de código y una ventana de contexto de un millón de tokens, que coincide con las capacidades de Flash y Pro.
Posicionamiento en la curva precio-rendimiento
Google posiciona la alta velocidad y el bajo costo de Flash‑Lite en el Frontera de Pareto, lo que significa que se encuentra entre los modelos más rentables y a la vez más capaces del mundo (). En evaluaciones comparativas, Flash‑Lite representa el mejor valor:Inteligente y asequible.
Acerca de Flash y Pro
- Géminis 2.5 FlashModelo de pensamiento multimodal, estable y de baja latencia. Se sitúa por debajo de Pro, pero prácticamente a la par con GPT-4o en capacidad, con velocidad y rentabilidad superiores ().
- Géminis 2.5 ProEl modelo más avanzado de Google. Reconocido por gestionar horas de vídeo y audio, código y cálculos complejos, y razonamiento contextual. También introduce presupuestos de pensamiento selectivos y una calidad de código mejorada para funcionar como una IA insignia estable a largo plazo.
Implementación y precios
- Disponibilidad:Los tres modelos son accesibles a través de Estudio de IA de Google, Google Cloud Vértice AI, y Aplicación Géminis .
- Estructura de costo (Precios de Vertex AI a partir del 16 de junio de 2025):
- Pro:$1.25/1M de entrada, $10/1M de salida (superior a 200 XNUMX tokens)
- Flash: $0.15/1 millón de entradas, $3.50/1 millón de salidas en modo de “pensamiento” e incluye 1,500 indicaciones fundamentadas gratuitas por día ()
- Flash‑Lite (vista previa): ~$0.10/$0.40 por 1 millón de tokens
Primeros Pasos
CometAPI proporciona una interfaz REST unificada que integra cientos de modelos de IA en un único punto de conexión, con gestión de claves API integrada, cuotas de uso y paneles de facturación. En lugar de tener que gestionar múltiples URL y credenciales de proveedores.
Los desarrolladores pueden acceder API de Gemini 2.5 Flash-Lite (versión preliminar) atravesar CometAPILos últimos modelos listados corresponden a la fecha de publicación del artículo. Para comenzar, explore las capacidades del modelo en el Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API". CometAPI Ofrecemos un precio muy inferior al oficial para ayudarte a integrarte.