API de audio GPT-4o: unificado /chat/completions Extensión de punto final que acepta entradas de audio (y texto) codificadas con Opus y devuelve voz sintetizada o transcripciones con parámetros configurables (modelo=gpt-4o-audio-preview-<date>, speed, temperature) para interacciones de voz por lotes y en streaming.
Información básica de audio GPT-4o
Vista previa de audio de GPT-4o (gpt-4o-audio-preview-2025-06-03) es la más nueva de OpenAI modelo de lenguaje grande centrado en el habla Disponible a través del estándar API de finalización de chat En lugar del canal en tiempo real de latencia ultrabaja. Basada en la misma base "omni" que GPT-4o, esta variante se especializa en... entrada y salida de voz de alta fidelidad Para conversaciones por turnos, creación de contenido, herramientas de accesibilidad y flujos de trabajo de agencia que no requieren tiempos de milisegundos. Hereda todas las fortalezas del razonamiento textual de los modelos de clase GPT-4, a la vez que añade... Conversión de voz a voz de extremo a extremo (S2S) tuberías deterministas llamada de función, Y el nuevo speed parámetro para el control de la velocidad de voz.
Conjunto de características principales del audio GPT-4o
• Procesamiento unificado de voz a voz – El audio se transforma directamente en tokens semánticamente ricos, se razona y se resintetiza sin servicios STT/TTS externos, lo que produce timbre de voz consistente, prosodia y retención del contexto.
• Seguimiento mejorado de instrucciones – La puesta a punto de junio de 2025 ofrece +19 pp pasa al 1 en tareas de comando de voz en comparación con la línea base GPT-2024o de mayo de 4, lo que reduce las alucinaciones en dominios como atención al cliente y redacción de contenido.
• Llamada de herramienta estable – Los resultados del modelo JSON estructurado que se ajusta al esquema de llamada de funciones de OpenAI, lo que permite que las API de backend (búsqueda, reserva, pagos) se activen con >95 % de precisión de argumentos.
• speed Parámetro (0.25–4×) – Los desarrolladores pueden modular la reproducción de voz para un aprendizaje a ritmo lento, una narración normal o modos rápidos de "lectura rápida audible". sin resintetizando el texto externamente.
• Toma de turnos consciente de las interrupciones – Si bien no está tan impulsado por la latencia como la variante en tiempo real, la vista previa admite transmisión parcial:Los tokens se emiten tan pronto como se calculan, lo que permite a los usuarios interrumpir anticipadamente si es necesario.
Arquitectura técnica de GPT-4o
• Transformador de una sola pila – Como todos los derivados de GPT-4o, la vista previa de audio emplea un codificador-decodificador unificado donde el texto y los tokens acústicos pasan a través de bloques de atención idénticos, promoviendo la conexión a tierra intermodal.
• Tokenización jerárquica de audio – PCM de 16 kHz sin procesar → parches log-mel → códigos acústicos gruesos → tokens semánticosEsta compresión multietapa logra Reducción del ancho de banda de 40 a 50 veces preservando al mismo tiempo los matices y permitiendo clips de varios minutos por ventana de contexto.
• Pesos cuantificados NF4 – La inferencia se sirve en Flotante normal de 4 bits precisión, reduciendo la memoria de la GPU a la mitad en comparación con fp16 y manteniendo Más de 70 RTF de transmisión (factor de tiempo real) en nodos A100-80 GB.
• Atención de transmisión y almacenamiento en caché de KV – Las incrustaciones rotatorias de ventanas deslizantes mantienen el contexto durante aproximadamente 30 s de voz mientras mantienen O(L) Uso de memoria, ideal para editores de podcasts o herramientas de lectura asistida.
Versiones y nombres — Vista previa de la pista con compilaciones con sello de fecha
| Identificador | Channel | Proposito | Fecha de lanzamiento | Estabilidad |
|---|---|---|---|---|
| gpt-4o-audio-preview-2025-06-03 | API de finalización de chat | Interacciones de audio por turnos, tareas de agencia | Junio 03 2025 | Vista previa (Se agradecen los comentarios) |
Elementos claves del nombre:
- gpt-4o – Familia omni multimodal.
- audio – Optimizado para casos de uso de voz.
- realice una vista previa – El contrato API puede evolucionar; aún no está disponible en GA.
- 2025-06-03 – Instantánea de capacitación e implementación para reproducibilidad.
Cómo llamar a la API de audio GPT-4o desde CometAPI
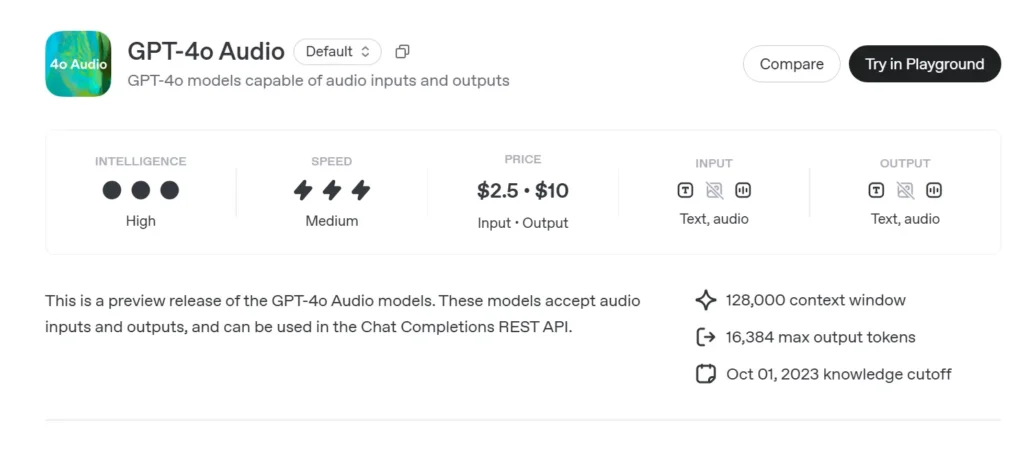
GPT-4o Audio API Precios de la API en CometAPI:
- Tokens de entrada: $2/M tokens
- Tokens de salida: $8/M tokens
Pasos requeridos
- Inicia sesión en cometapi.comSi aún no eres nuestro usuario, por favor regístrate primero.
- Obtenga la clave API de credenciales de acceso de la interfaz. Haga clic en "Agregar token" en el token API del centro personal, obtenga la clave del token: sk-xxxxx y envíe.
- Obtenga la URL de este sitio: https://api.cometapi.com/
Métodos de uso
- Seleccione la opción "**
gpt-4o-audio-preview-2025-06-03**Punto final para enviar la solicitud y configurar su cuerpo. El método y el cuerpo de la solicitud se obtienen de la documentación de la API de nuestro sitio web. Nuestro sitio web también ofrece la prueba de Apifox para su comodidad. - Reemplazar con su clave CometAPI real de su cuenta.
- Inserte su pregunta o solicitud en el campo de contenido: esto es lo que responderá el modelo.
- . Procesa la respuesta de la API para obtener la respuesta generada.
Para obtener información sobre el acceso a modelos en la API de Comet, consulte Documento API.
Para obtener información sobre el precio del modelo en Comet API, consulte https://api.cometapi.com/pricing.
Flujo de trabajo de API — Finalizaciones de chat con partes de audio y ganchos de función
- Formato de entrada –
audio/*MIME obase64Fragmentos WAV incrustados enmessages[].content. - Opciones de salida –
•mode: "text"→ texto puro para subtítulos.
•mode: "audio"→ devuelve un el streaming Carga útil de Opus o µ-law con marcas de tiempo. - Invocación de función - Añadir
functions:esquema; el modelo emiterole: "function"con argumentos JSON; el desarrollador ejecuta la llamada a la herramienta y, opcionalmente, envía el resultado de vuelta. - Control de clasificación - Establecer
voice.speed=1.25para acelerar la reproducción; rangos seguros 0.25–4.0. - Límites de tokens/audio – 128 k de contexto (~4 min de voz) en el lanzamiento; 4096 tokens de audio / 8192 tokens de texto Lo que ocurra primero.
Código de muestra e integración de API
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Destacado:
- modelo:
"gpt-4o-audio-preview-2025-06-03" - audio teclear usuario mensaje para enviar flujo binario
- velocidad: Control S velocidad de voz entre lento (0.5) y rápido (2.0)
- temperatura:Saldos creatividad vs consistencia
Indicadores técnicos — Latencia, calidad, precisión
| Métrico | Vista previa de audio | GPT-4o (solo texto) | Delta |
|---|---|---|---|
| Latencia del primer token (1 disparo) | 1.2 s avg | 0.35 s | +0.85 segundos |
| MOS (Naturalidad del habla, 5 puntos) | 4.43 | - | - |
| Cumplimiento de instrucciones (Voz) | 92% | 73% | +19 pp |
| Precisión del argumento de llamada de función | 95.8% | 87% | +8.8 pp |
| Tasa de error de palabras (STT implícita) | 5.2% | n/a | - |
| Memoria GPU/Transmisión (A100-80 GB) | 7.1 GB | 14 GB (fp16) | −49% |
Puntos de referencia ejecutados a través de la transmisión de finalizaciones de chat, tamaño de lote = 1.
Vea también API en tiempo real de GPT-4o