

OpenAI publicó un avance de investigación de gpt-oss-safeguard, una familia de modelos de inferencia de peso abierto diseñada para permitir a los desarrolladores imponer su propio políticas de seguridad en el momento de la inferencia. En lugar de enviar un clasificador fijo o un motor de moderación de caja negra, los nuevos modelos se ajustan con precisión a Motivo según una política proporcionada por el desarrollador, emiten una cadena de pensamiento (CoT) que explica su razonamiento y producen resultados de clasificación estructurados. Anunciado como un avance de investigación, gpt-oss-safeguard se presenta como un par de modelos de razonamiento—gpt-oss-safeguard-120b y gpt-oss-safeguard-20b—ajustado a partir de la familia gpt-oss y diseñado explícitamente para realizar tareas de clasificación de seguridad y aplicación de políticas durante la inferencia.
¿Qué es gpt-oss-safeguard?
gpt-oss-safeguard es un par de modelos de razonamiento de solo texto con pesos abiertos que han sido post-entrenados a partir de la familia gpt-oss para **interpretar una política escrita en lenguaje natural y etiquetar el texto de acuerdo con esa política.**La característica distintiva es que la política es proporcionado en el momento de la inferencia (Política como entrada), no incorporada en los pesos estáticos del clasificador. Los modelos están diseñados principalmente para tareas de clasificación de seguridad, por ejemplo, moderación de múltiples políticas, clasificación de contenido en múltiples regímenes regulatorios o comprobaciones de cumplimiento de políticas.
¿Por qué esto importa?
Los sistemas de moderación tradicionales suelen basarse en (a) conjuntos de reglas fijas asociadas a clasificadores entrenados con ejemplos etiquetados, o (b) heurísticas/expresiones regulares para la detección de palabras clave. gpt-oss-safeguard propone un cambio de paradigma: en lugar de reentrenar los clasificadores cada vez que cambia la política, se proporciona un texto de política (por ejemplo, la política de uso aceptable de la empresa, los términos de servicio de la plataforma o las directrices de un regulador), y el modelo analiza si un contenido determinado infringe dicha política. Esto promete agilidad (cambios de política sin necesidad de reentrenar) e interpretabilidad (el modelo muestra su razonamiento).
Esta es su filosofía central: “Sustituir la memorización por el razonamiento y la adivinación por la explicación”.
Esto representa una nueva etapa en la seguridad de contenidos, pasando de “aprender reglas de forma pasiva” a “comprender reglas de forma activa”.
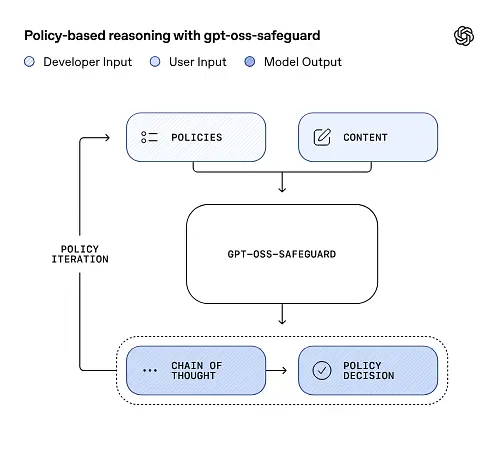
gpt-oss-safeguard puede leer directamente las políticas de seguridad definidas por los desarrolladores y seguir esas políticas para tomar decisiones durante la inferencia.
¿Cómo funciona gpt-oss-safeguard?
razonamiento de política como entrada
En el momento de la inferencia, usted proporciona dos cosas: el texto de política y la contenido del candidato El modelo trata la política como la instrucción principal y luego realiza un razonamiento paso a paso para determinar si el contenido está permitido, prohibido o requiere pasos de moderación adicionales. En la inferencia, el modelo:
- Produce un resultado estructurado que incluye una conclusión (etiqueta, categoría, confianza) y una explicación del razonamiento legible por humanos que justifica por qué se llegó a esa conclusión.
- ingiere la política y el contenido que se va a clasificar,
- internamente razona a través de las cláusulas de la póliza utilizando pasos similares a una cadena de pensamiento, y
Por ejemplo:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Responderá:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Cadena de pensamiento (CoT) y resultados estructurados
gpt-oss-safeguard puede generar un registro de seguimiento de la conclusión (CoT) completo como parte de cada inferencia. El CoT está diseñado para ser inspeccionable: los equipos de cumplimiento pueden leer por qué el modelo llegó a una conclusión, y los ingenieros pueden usar el registro para diagnosticar ambigüedades en las políticas o modos de fallo del modelo. El modelo también admite salidas estructuradas—por ejemplo, un JSON que contiene un veredicto, secciones de políticas infringidas, puntuación de gravedad y acciones correctivas sugeridas—lo que facilita su integración en los flujos de moderación.
Niveles de "esfuerzo de razonamiento" ajustables
Para equilibrar la latencia, el coste y la exhaustividad, los modelos admiten un esfuerzo de razonamiento configurable: bajo / medio / altoUn mayor esfuerzo incrementa la profundidad del razonamiento y, por lo general, produce inferencias más sólidas, aunque más lentas y costosas. Esto permite a los desarrolladores priorizar las cargas de trabajo: dedicar un menor esfuerzo al contenido rutinario y un mayor esfuerzo a casos excepcionales o contenido de alto riesgo.
¿Cuál es la estructura del modelo y qué versiones existen?
Modelo de familia y linaje
gpt-oss-safeguard son post-entrenado variantes de la versión anterior de OpenAI gpt-oss Modelos abiertos. La familia de productos de protección incluye actualmente dos tamaños disponibles:
- gpt-oss-safeguard-120b — un modelo de 120 mil millones de parámetros destinado a tareas de razonamiento de alta precisión que todavía se ejecuta en una sola GPU de 80 GB en tiempos de ejecución optimizados.
- gpt-oss-safeguard-20b — un modelo de 20 mil millones de parámetros optimizado para inferencia de menor costo y entornos periféricos o locales (puede ejecutarse en dispositivos con 16 GB de VRAM en algunas configuraciones).
Notas sobre la arquitectura y características de ejecución (qué esperar)
- Parámetros activos por token: La arquitectura subyacente de gpt-oss utiliza técnicas que reducen el número de parámetros activados por token (una mezcla de atención densa y dispersa / diseño de estilo de mezcla de expertos en el gpt-oss original).
- En la práctica, la clase 120B cabe en aceleradores grandes individuales y la clase 20B está diseñada para funcionar en configuraciones de VRAM de 16 GB en tiempos de ejecución optimizados.
Los modelos de salvaguarda eran no capacitado con datos biológicos o de ciberseguridad adicionalesAdemás, los análisis de los peores escenarios de uso indebido realizados para la versión gpt-oss son aplicables, en líneas generales, a las variantes de salvaguarda. Los modelos están diseñados para la clasificación, no para la generación de contenido para usuarios finales.
¿Cuáles son los objetivos de gpt-oss-safeguard?
Objetivos
- Flexibilidad de las políticas: Permitir a los desarrolladores definir cualquier política en lenguaje natural y que el modelo la aplique sin necesidad de una colección de etiquetas personalizada.
- Explicabilidad: Exponer el razonamiento para que las decisiones puedan ser auditadas y las políticas iteradas.
- Accesibilidad: proporcionar una alternativa de peso abierto para que las organizaciones puedan ejecutar el razonamiento de seguridad localmente e inspeccionar los componentes internos del modelo.
Comparación con clasificadores clásicos
Ventajas frente a los clasificadores tradicionales
- No se requiere reentrenamiento para cambios de política: Si su política de moderación cambia, actualice el documento de política en lugar de recopilar etiquetas y volver a entrenar un clasificador.
- Razonamiento más rico: Los resultados de CoT pueden revelar interacciones políticas sutiles y proporcionar una justificación narrativa útil para los revisores humanos.
- Personalización: Un único modelo puede aplicar simultáneamente muchas políticas diferentes durante la inferencia.
Contras frente a clasificadores tradicionales
- Límites de rendimiento para algunas tareas: La evaluación de OpenAI señala que Los clasificadores de alta calidad entrenados con decenas de miles de ejemplos etiquetados pueden superar a gpt-oss-safeguard. En tareas de clasificación especializadas, cuando el objetivo es la precisión de la clasificación sin procesar y se dispone de datos etiquetados, un clasificador específico entrenado con esa distribución puede ser más adecuado.
- Latencia y coste: El razonamiento con CoT requiere un alto poder de cómputo y es más lento que un clasificador ligero; esto puede hacer que las canalizaciones basadas únicamente en salvaguardas resulten costosas a gran escala.
En resumen: gpt-oss-safeguard se utiliza mejor donde agilidad y auditabilidad de las políticas son prioritarias o cuando los datos etiquetados son escasos, y como componente complementario en flujos de trabajo híbridos, no necesariamente como un reemplazo directo para un clasificador optimizado para escala.
¿Qué rendimiento obtuvo gpt-oss-safeguard en las evaluaciones de OpenAI?
OpenAI publicó los resultados de referencia en un informe técnico de 10 páginas que resume las evaluaciones internas y externas. Conclusiones clave (métricas seleccionadas y fundamentales):
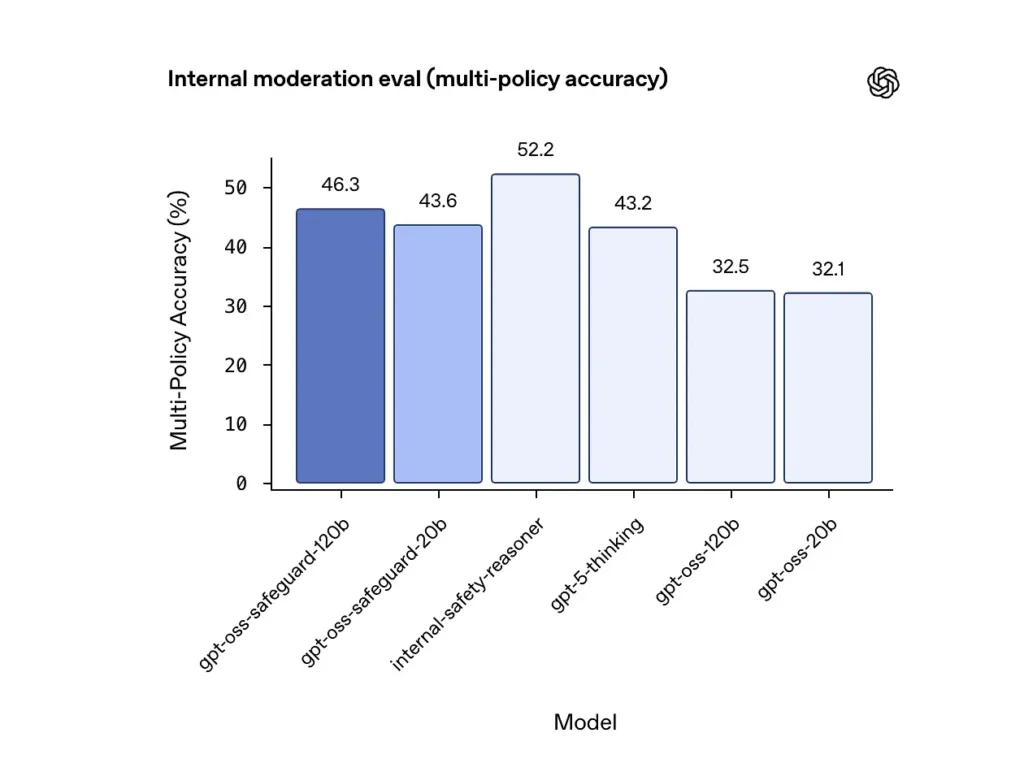
Precisión de múltiples políticas (evaluación interna)
OpenAI evaluó la precisión de múltiples políticas proporcionando el modelo una variedad políticas simultáneamente y considerando una predicción como correcta solo si coincidía con las etiquetas doradas en todo todas políticas. Resultados:
- gpt-oss-safeguard-120b: 46.3% precisión de múltiples políticas
- gpt-oss-safeguard-20b: 43.6%
- Para comparacion: Pensamiento GPT-5: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
El conjunto interno de modelos de seguridad de OpenAI obtuvo un 52.2 % en la misma prueba. Estos resultados demuestran que los modelos de seguridad superan con creces a sus modelos base gpt-oss en la tarea de políticas múltiples, e incluso superaron al modelo base gpt-5-thinking, de mayor tamaño, en la métrica interna de políticas múltiples.
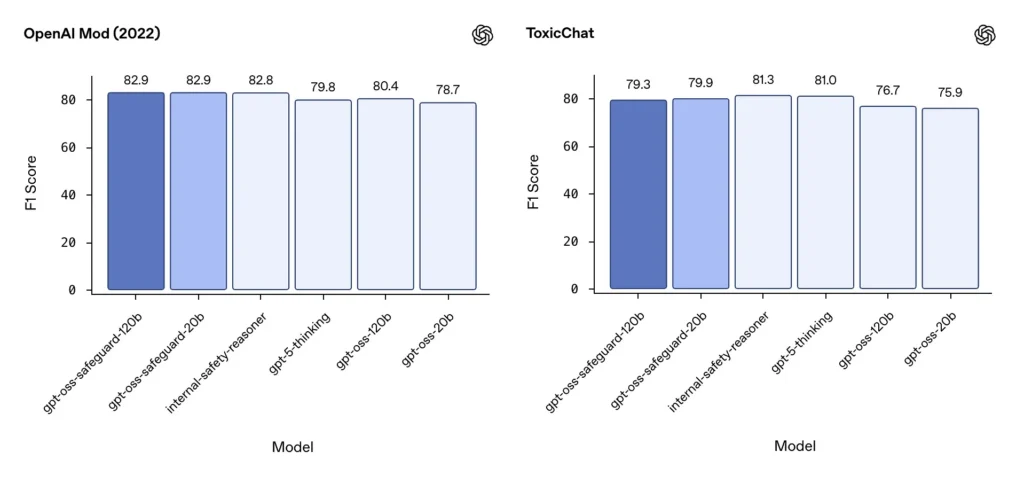
Moderación F1 (referencias externas)
En el conjunto de datos de moderación de OpenAI de 2022 y en el benchmark público ToxicChat, los modelos gpt-oss-safeguard lograron sólidas puntuaciones F1:
- Modificación OpenAI (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- Chat tóxico F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Estas puntuaciones sitúan a gpt-oss-safeguard cerca o ligeramente por detrás de los sistemas internos especializados de OpenAI en algunas pruebas de referencia, y generalmente por delante de sus homólogos gpt-oss no ajustados.
Limitaciones observadas
OpenAI señala dos limitaciones prácticas:
- Los clasificadores entrenados con conjuntos de datos etiquetados grandes y específicos para cada tarea aún pueden superar a los modelos de salvaguarda. cuando la precisión de la clasificación es el único objetivo.
- Costes de computación y latencia: El razonamiento CoT aumenta el tiempo de inferencia y el consumo de computación, lo que complica la escalabilidad al tráfico a nivel de plataforma a menos que se combine con clasificadores de triaje y canalizaciones asíncronas.
paridad multilingüe
gpt-oss-safeguard funciona a la par con los modelos gpt-oss subyacentes en muchos idiomas en pruebas de estilo MMMLU, lo que indica que las variantes de safeguard ajustadas conservan una amplia capacidad de razonamiento.
¿Cómo pueden los equipos acceder e implementar gpt-oss-safeguard?
OpenAI proporciona los pesos bajo Apache 2.0 y enlaces para la descarga de los modelos (Hugging Face). Dado que gpt-oss-safeguard es un modelo de pesos abiertos, se recomienda su implementación local y autogestionada (para mayor privacidad y personalización).
- Descargar pesos de modelos (de OpenAI / Hugging Face) y alójelas en sus propios servidores o máquinas virtuales en la nube. Apache 2.0 permite la modificación y el uso comercial.
- RuntimeUtilice entornos de ejecución de inferencia estándar que admitan modelos de transformadores grandes (ONNX Runtime, Triton o entornos de ejecución optimizados del proveedor). Entornos de ejecución de la comunidad como Ollama y LM Studio ya están incorporando compatibilidad con familias gpt-oss.
- FerreteríaLa arquitectura de 120B suele requerir GPU con mucha memoria (p. ej., A100/H100 de 80 GB o particionamiento multi-GPU), mientras que la de 20B puede ejecutarse de forma más económica y cuenta con opciones optimizadas para configuraciones de 16 GB de VRAM. Planifique la capacidad teniendo en cuenta el rendimiento máximo y los costes de evaluación de múltiples políticas.
entornos de ejecución gestionados y de terceros
Si utilizar tu propio hardware resulta poco práctico, CometAPI Se está incorporando rápidamente compatibilidad con modelos GPT-OSS. Estas plataformas pueden facilitar la escalabilidad, pero reintroducen las desventajas de la exposición de datos de terceros. Evalúe la privacidad, los SLA y los controles de acceso antes de elegir entornos de ejecución gestionados.
Estrategias de moderación efectivas con gpt-oss-safeguard
1) Utilizar un proceso híbrido (clasificación → justificación → resolución)
- Capa de triaje: Los clasificadores (o reglas) pequeños y rápidos filtran los casos triviales. Esto reduce la carga en el costoso modelo de protección.
- Capa de protección: Ejecute gpt-oss-safeguard para comprobaciones ambiguas, de alto riesgo o con múltiples políticas donde los matices de las políticas sean importantes.
- Adjudicación humana: Se escalan los casos excepcionales y las apelaciones, almacenando el CoT como prueba de transparencia. Este diseño híbrido equilibra el rendimiento y la precisión.
2) Ingeniería de políticas (no ingeniería de avisos)
- Trata las políticas como artefactos de software: crea versiones, pruébalas con conjuntos de datos y mantenlas explícitas y jerárquicas.
- Redacte políticas con ejemplos y contraejemplos. Cuando sea posible, incluya instrucciones para evitar ambigüedades (por ejemplo, “Si la intención del usuario es claramente exploratoria e histórica, etiquétela como X; si la intención es operativa y en tiempo real, etiquétela como Y”).
3) Configurar el esfuerzo de razonamiento dinámicamente
- Use poco esfuerzo para el procesamiento a granel y gran esfuerzo para contenido marcado, apelaciones o verticales de alto impacto (legal, médico, financiero).
- Ajusta los umbrales con la retroalimentación de revisiones humanas para encontrar el punto óptimo entre costo y calidad.
4) Validar el CoT y estar atento al razonamiento alucinatorio.
El CoT es valioso, pero puede ser engañoso: la información que proporciona es una justificación generada por un modelo, no una verdad absoluta. Es fundamental auditar periódicamente los resultados del CoT e implementar detectores para identificar citas erróneas o razonamientos incoherentes. OpenAI documenta las cadenas de pensamiento engañosas como un problema observado y sugiere estrategias para mitigarlas.
5) Crear conjuntos de datos a partir del funcionamiento del sistema
Se registran las decisiones del modelo y las correcciones humanas para crear conjuntos de datos etiquetados que pueden mejorar los clasificadores de priorización o fundamentar la revisión de políticas. Con el tiempo, un conjunto de datos etiquetados pequeño y de alta calidad, junto con un clasificador eficiente, suele reducir la dependencia de la inferencia completa de CoT para el contenido rutinario.
6) Supervisar el cálculo y los costes; emplear flujos asíncronos
Para aplicaciones de baja latencia orientadas al consumidor, considere realizar comprobaciones de seguridad asíncronas con una experiencia de usuario conservadora a corto plazo (por ejemplo, ocultar temporalmente el contenido mientras se revisa) en lugar de ejecutar comprobaciones de seguridad de alta complejidad de forma síncrona. OpenAI señala que Safety Reasoner utiliza flujos asíncronos internamente para gestionar la latencia en los servicios de producción.
7) Considere la privacidad y la ubicación de la implementación.
Dado que los pesos son abiertos, puede ejecutar la inferencia completamente en sus propias instalaciones para cumplir con las estrictas normas de gobernanza de datos o reducir la exposición a las API de terceros, lo cual resulta valioso para las industrias reguladas.
Conclusión:
gpt-oss-safeguard es una herramienta práctica, transparente y flexible para razonamiento de seguridad basado en políticasBrilla cuando lo necesitas decisiones auditables vinculadas a políticas explícitas, cuando sus políticas cambian con frecuencia o cuando desea mantener controles de seguridad en las instalaciones. Es no Una solución milagrosa que reemplace automáticamente a los clasificadores especializados de alto volumen: las propias evaluaciones de OpenAI demuestran que los clasificadores dedicados, entrenados con grandes corpus etiquetados, pueden superar a estos modelos en precisión bruta para tareas específicas. En cambio, considere gpt-oss-safeguard como un componente estratégico: el motor de razonamiento explicable en el núcleo de una arquitectura de seguridad por capas (triaje rápido → razonamiento explicable → supervisión humana).
Primeros Pasos
CometAPI es una plataforma API unificada que integra más de 500 modelos de IA de proveedores líderes, como la serie GPT de OpenAI, Gemini de Google, Claude de Anthropic, Midjourney, Suno y más, en una única interfaz intuitiva para desarrolladores. Al ofrecer autenticación, formato de solicitudes y gestión de respuestas consistentes, CometAPI simplifica drásticamente la integración de las capacidades de IA en sus aplicaciones. Ya sea que esté desarrollando chatbots, generadores de imágenes, compositores musicales o canales de análisis basados en datos, CometAPI le permite iterar más rápido, controlar costos y mantenerse independiente del proveedor, todo mientras aprovecha los últimos avances del ecosistema de IA.
La última integración gpt-oss-safeguard aparecerá pronto en CometAPI, ¡así que estad atentos! Mientras finalizamos la carga del modelo gpt-oss-safeguard, los desarrolladores pueden acceder API GPT-OSS-20B y API GPT-OSS-120B a través de CometAPI, la última versión del modelo Se actualiza constantemente con el sitio web oficial. Para empezar, explora las capacidades del modelo en el Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API". CometAPI Ofrecemos un precio muy inferior al oficial para ayudarte a integrarte.
¿Listo para ir?→ Regístrate en CometAPI hoy !
Si quieres conocer más consejos, guías y novedades sobre IA síguenos en VK, X y Discord!