

Grok-4-Fast es de xAI nuevo modelo de razonamiento rentable Diseñado para hacer que las capacidades de razonamiento y búsqueda web de alta calidad sean más económicas y rápidas tanto para el uso del consumidor como del desarrollador. xAI lo posiciona como un frontera oferta que preserva el rendimiento de referencia de Grok-4 al tiempo que mejora la eficiencia del token y ofrece dos variantes optimizadas para ambos. razonamiento or sin razonamiento cargas de trabajo.
Características principales (lista rápida)
- Dos variantes de modelo:
grok-4-fast-reasoningygrok-4-fast-non-reasoning(ajustable para profundidad vs. velocidad). - Ventana de contexto muy grande: hasta Tokens 2,000,000, lo que permite documentos extremadamente largos, transcripciones de varias horas y flujos de trabajo de múltiples documentos.
- Enfoque en la eficiencia y el costo del token: Informes de xAI ~40% menos de tokens de pensamiento en promedio contra Grok-4 y un reclamado ~98% de reducción en el costo para lograr el mismo rendimiento de referencia (sobre los informes de métricas xAI).
- Integración de herramientas nativas/navegación: Entrenado de extremo a extremo con RL de uso de herramientas para navegación web/X, ejecución de código y comportamientos de búsqueda de agentes.
- Llamada multimodal y de función: Admite imágenes y salidas estructuradas; la API admite llamadas de funciones y formatos de respuesta estructurados.
Detalles técnicos
Arquitectura de razonamiento unificado: Grok-4-Fast utiliza un base de peso de un solo modelo que se puede dirigir hacia razonamiento (larga cadena de pensamiento) o sin razonamiento (Respuestas rápidas) comportamiento mediante indicaciones del sistema o selección de variantes, en lugar de enviar dos modelos de red troncal completamente separados. Esto reduce la latencia de conmutación y el costo de tokens para cargas de trabajo mixtas.
Aprendizaje por refuerzo para la densidad de inteligencia: Informes xAI utilizando aprendizaje de refuerzo a gran escala centrado en densidad de inteligencia (maximizar el rendimiento por token), que es la base de las ganancias de eficiencia del token indicadas.
Acondicionamiento de herramientas y búsqueda agente: Grok-4-Fast fue entrenado y evaluado en tareas que requieren la invocación de herramientas (navegación web, búsqueda X, ejecución de código). El modelo se presenta como experto en la elección de Cuándo llamar a las herramientas y cómo combinar la evidencia de navegación para obtener respuestas.
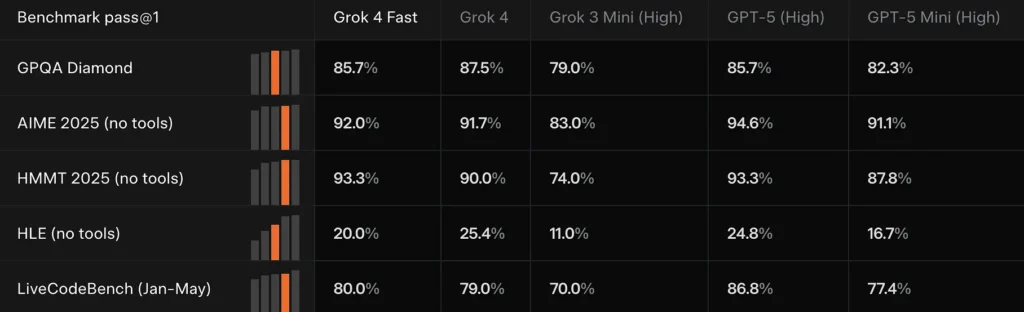
Rendimiento de referencia
IMejoras en BrowseComp (44.9 % aprobado en 1 frente al 43.0 % para Grok-4), **SimpleQA (95.0% frente al 94.0%)**y grandes ganancias en ciertas áreas de búsqueda y navegación en idioma chino. xAI también informa una clasificación superior en el Search Arena de LMArena para un grok-4-fast-search variante.
Versiones y nombres de modelos
Nombres públicos anunciados por xAI: grok-4-fast-reasoning y **grok-4-fast-non-reasoning**Cada variante informa lo mismo 2 millón de tokens límite de contexto. La plataforma también continúa albergando el anterior Grok-4 buque insignia (por ejemplo, grok-4-0709 variantes utilizadas anteriormente).
Limitaciones y consideraciones de seguridad
- Preocupaciones sobre la seguridad del contenido: Informes de medios de investigación indican que la familia Grok de xAI (y algunas de sus funciones) se desarrollaron con opciones de contenido permisivo y que algunos flujos de trabajo internos expusieron a los anotadores a material altamente perturbador. Existe una preocupación explícita sobre la robustez de la moderación y la denuncia de contenido ilegal a las autoridades. Estos problemas de seguridad y cumplimiento normativo son relevantes al implementar cualquier variante de Grok en producción.
- Verificación independiente: Muchas de las afirmaciones de rendimiento/economía de xAI son autoevaluadas; aún se publican evaluaciones comparativas independientes y revisiones por pares. Considere las afirmaciones de rentabilidad como proporcionadas por el proveedor hasta que esté disponible una réplica de terceros.
- Riesgos operacionales: Debido a que Grok-4-Fast está diseñado para la navegación por agentes, los usuarios deben tener en cuenta alucinación, límites de frescura de los datos (a pesar de la capacidad de navegación), y política de privacidad Consideraciones cuando el modelo se utiliza con herramientas externas o consultas web en vivo.
Casos de uso típicos y recomendados
- Búsqueda y recuperación de alto rendimiento — agentes de búsqueda que necesitan un razonamiento web rápido de múltiples saltos.
- Asistentes y bots agentes — agentes que combinan navegación, ejecución de código y llamadas de herramientas asincrónicas (donde esté permitido).
- Implementaciones de producción sensibles a los costos — servicios que requieren muchas llamadas y desean una economía de token a utilidad mejorada en comparación con un modelo base más pesado.
- Experimentación de desarrolladores — creación de prototipos de flujos multimodales o aumentados mediante la web que se basan en consultas rápidas y repetidas.
Como llamar grok-4-fast API de CometAPI
grok-code-fast-1 Precios de API en CometAPI: 20 % de descuento sobre el precio oficial.
| grok-4-fast-no-razonamiento | Tokens de entrada: $0.16/M tokens Tokens de salida: $0.40/M tokens |
| grok-4-razonamiento-rápido | Tokens de entrada: $0.16/M tokens Tokens de salida: $0.40/M tokens |
Pasos requeridos
- Inicia sesión en cometapi.comSi aún no eres nuestro usuario, por favor regístrate primero.
- Obtenga la clave API de credenciales de acceso de la interfaz. Haga clic en "Agregar token" en el token API del centro personal, obtenga la clave del token: sk-xxxxx y envíe.
Método de uso
- Seleccione la opción "
grok-4-fast-reasoning"/"grok-4-fast-reasoningPunto final para enviar la solicitud de API y configurar el cuerpo de la solicitud. El método y el cuerpo de la solicitud se obtienen de la documentación de la API de nuestro sitio web. Nuestro sitio web también ofrece la prueba de Apifox para su comodidad. - Reemplazar con su clave CometAPI real de su cuenta.
- Inserte su pregunta o solicitud en el campo de contenido: esto es lo que responderá el modelo.
- . Procesa la respuesta de la API para obtener la respuesta generada.
CometAPI proporciona una API REST totalmente compatible para una migración fluida. Detalles clave para Documento API:
- URL base: https://api.cometapi.com/v1/chat/completions
- Nombres de modelos:"
grok-4-fast-reasoning"/"grok-4-fast-reasoning" - Autenticación: Token portador a través de
Authorization: Bearer YOUR_CometAPI_API_KEYencabezamiento - Tipo de contenido:
application/json.
Integración de API y ejemplos
Fragmento de Python para un Finalización de chat Llamada a través de CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-4-fast's main features."}
]
response = openai.ChatCompletion.create(
model="grok-4-fast-reasoning",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Vea también Grok 4