

xAI anunciado Grok 4 Fast, una variante optimizada en costos de su familia Grok que, según la compañía, ofrece un rendimiento de referencia cercano al buque insignia al tiempo que reduce el precio para lograr ese rendimiento. 98% en comparación con Grok 4. El nuevo modelo está diseñado para búsquedas de alto rendimiento y uso de herramientas agenticas, e incluye una ventana de contexto de 2 millones de tokens y variantes separadas de "razonamiento" y "no razonamiento" para permitir que los desarrolladores ajusten el cómputo a sus necesidades.
Características y beneficios principales
Modelo de inferencia rentable: Grok 4 Fast está construido a partir de la familia Grok 4 con un enfoque en la eficiencia del token y el uso de herramientas en tiempo real. xAI informa que el modelo requiere aproximadamente 40% menos de tokens "pensantes" En promedio, el Análisis Artificial, que monitorea la latencia, la velocidad de salida y la relación precio/rendimiento en diversos modelos públicos, sitúa a Grok 4 Fast en una posición destacada en la frontera entre inteligencia y coste, y confirma la rápida velocidad de salida del modelo y su favorable relación coste en las primeras pruebas.
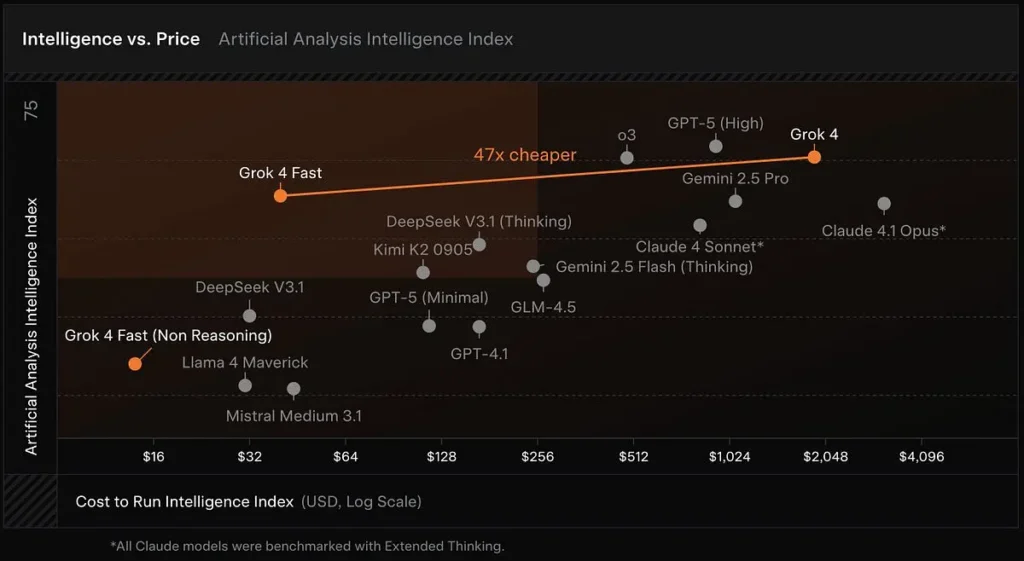
Ventanas de contexto grandes: Grok 4 Fast está diseñado para búsquedas de alto rendimiento y uso de herramientas de agente, e incluye una ventana de contexto de 2 millones de tokens y variantes separadas de "razonamiento" y "no razonamiento" para permitir que los desarrolladores ajusten el procesamiento a sus necesidades.
Capacidades nativas de uso de herramientas: Grok 4 Fast ofrece “capacidades de búsqueda web y X de vanguardia” que mejoran la recuperación, la navegación y la síntesis de contenido web durante flujos de trabajo de agencia, lo que posiciona a Grok 4 Fast como una herramienta de búsqueda práctica para aplicaciones que requieren recopilación de información en tiempo real y razonamiento en documentos largos, con un rendimiento líder en múltiples puntos de referencia de búsqueda, incluidos:
- BrowseComp (zh): 51.2% (frente al 45.0%) de Grok 4
- X Bench Deepsearch (zh): 74.0% (frente al 66.0%) de Grok 4
Arquitectura unificada: El mismo modelo admite los modos de inferencia y no inferencia, lo que elimina la necesidad de cambiar de modelo por separado. Su menor latencia y coste lo hacen ideal para aplicaciones en tiempo real (como búsqueda, respuesta a preguntas y asistencia en la investigación).
Comparación de rendimiento (principales puntos de referencia)
En una prueba privada de LMArena que xAI compartió, el grok-4-fast-search (nombre clave menlo) la variante encabeza el Search Arena con una calificación Elo de 1,163, mientras que la variante de texto (tahoe) se encuentra entre los diez primeros en Text Arena: resultados que xAI utiliza para respaldar sus afirmaciones sobre el rendimiento de las búsquedas.
Grok 4 coincide rápidamente o sigue de cerca a Grok 4 en múltiples puntos de referencia de frontera (por ejemplo: GPQA Diamond, AIME 2025 y HMMT 2025), al tiempo que supera a los modelos anteriores más pequeños en tareas de razonamiento: evidencia que xAI usa para justificar la afirmación de "rendimiento comparable".
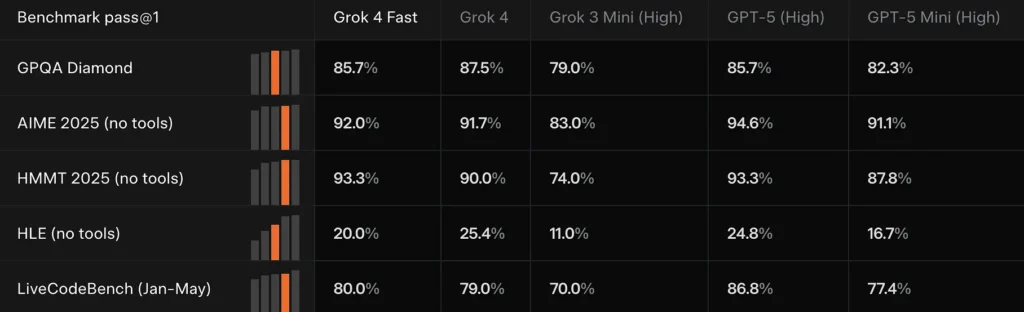
Comparar resultados
En comparación con Grok 4: más barato y con un consumo computacional menor, pero con un rendimiento similar.
Comparado con Grok 3 Mini: Más potente, capaz de razonamiento complejo y búsqueda en tiempo real.
En comparación con GPT-5/Gemini/Claude: gracias a su altísima eficiencia de token y sus capacidades de herramientas, es líder en rentabilidad y en algunas tareas de búsqueda.
Precios y disponibilidad
Contexto y tokens: Dos modelos de sabores: grok-4-fast-reasoning y grok-4-fast-non-reasoning, cada uno con contexto 2M.
Precios publicados (lista) en la publicación de lanzamiento (niveles de ejemplo):
- Tokens de entrada: $0.20 / 1M (<128k) — $0.40 / 1M (≥128k)
- Tokens de salida: $0.50 / 1M (<128k) — $1.00 / 1M (≥128k)
- Tokens de entrada almacenados en caché: $0.05 / 1M.
(Consulte el anuncio de xAI para conocer las reglas de facturación exactas y las promociones por tiempo limitado).
Disponibilidad del proveedor: xAI enumera la disponibilidad gratuita a corto plazo a través de OpenRouter y Vercel AI Gateway y la disponibilidad general a través de la API de xAI.
Qué significa esto para los usuarios y los equipos
- Gran ahorro de costes para uso en producción La combinación de un precio por token más bajo y un menor número de tokens "pensantes" permite a los equipos ejecutar más consultas o flujos de trabajo de contexto más amplio a una fracción del costo de Grok 4, lo que reduce significativamente las barreras para la experimentación y las implementaciones a gran escala. (Afirmación respaldada por la información sobre costo/rendimiento de xAI y análisis de costos de terceros).
- Funciona con documentos muy largos y razonamiento de varios pasos. — Los tokens de 2M hacen que sea práctico ingerir libros completos, grandes bases de código o expedientes legales/técnicos largos en una sola sesión, lo que mejora la precisión y la coherencia de las tareas que requieren un contexto de largo alcance (búsqueda de documentos, resumen, generación de código de formato largo, asistentes de investigación).
- Salidas más rápidas y de menor latencia para aplicaciones interactivas Al ser una variante "Rápida", está diseñada para un rendimiento de tokens más rápido y una latencia más baja, lo que beneficia a las interfaces de usuario de chat, los asistentes de programación y los bucles de agentes en tiempo real donde la capacidad de respuesta es crucial. (Artificial Analysis y las pruebas comparativas de proveedores destacan la velocidad de salida como un factor diferenciador).
- Buena relación precio/rendimiento para tareas de razonamiento comparativo — Para los equipos que evalúan modelos mediante parámetros académicos de vanguardia, Grok 4 Fast ofrece un sólido compromiso: precisión cercana a la frontera a un costo considerablemente menor, lo que lo hace atractivo para laboratorios de investigación y empresas que utilizan conjuntos de parámetros de referencia costosos con frecuencia.
Conclusión:
Grok 4 Fast posiciona a xAI para competir en relación precio-rendimiento y en aplicaciones de agentes centradas en la búsqueda. Si las afirmaciones de eficiencia y verificación de la compañía se confirman en pruebas independientes específicas del dominio, Grok 4 Fast podría redefinir las expectativas de costos para implementaciones LLM de alta capacidad basadas en herramientas, especialmente para aplicaciones que dependen de la recuperación web en vivo y el uso de herramientas de varios pasos.
Primeros Pasos
CometAPI es una plataforma API unificada que integra más de 500 modelos de IA de proveedores líderes, como la serie GPT de OpenAI, Gemini de Google, Claude de Anthropic, Midjourney, Suno y más, en una única interfaz intuitiva para desarrolladores. Al ofrecer autenticación, formato de solicitudes y gestión de respuestas consistentes, CometAPI simplifica drásticamente la integración de las capacidades de IA en sus aplicaciones. Ya sea que esté desarrollando chatbots, generadores de imágenes, compositores musicales o canales de análisis basados en datos, CometAPI le permite iterar más rápido, controlar costos y mantenerse independiente del proveedor, todo mientras aprovecha los últimos avances del ecosistema de IA.
Los desarrolladores pueden acceder Grok-4-rápido ( modelo: grok-4-fast-reasoning” / “grok-4-fast-reasoning) a través de CometAPI, la última versión del modelo Se actualiza constantemente con el sitio web oficial. Para empezar, explora las capacidades del modelo en el Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API". CometAPI Ofrecemos un precio muy inferior al oficial para ayudarte a integrarte.
¿Listo para ir?→ Regístrate en CometAPI hoy !