

GLM-5 es el nuevo modelo fundacional de pesos abiertos, centrado en agentes, de Zhipu AI, creado para programación de largo horizonte y agentes multietapa. Está disponible a través de varias APIs alojadas (incluidos CometAPI y endpoints de proveedores) y como versión de investigación con código y pesos; puedes integrarlo usando llamadas REST estándar compatibles con OpenAI, streaming y SDKs.
¿Qué es GLM-5 de Z.ai?
GLM-5 es el modelo fundacional insignia de quinta generación de Z.ai diseñado para la ingeniería basada en agentes: planificación de largo horizonte, uso de herramientas en múltiples pasos y diseño de código/sistemas a gran escala. Lanzado públicamente en febrero de 2026, GLM-5 es un modelo de Mezcla de Expertos (MoE) con ~744 mil millones de parámetros totales y un conjunto de parámetros activos en el rango de 40B por pasada de inferencia; las decisiones de arquitectura y entrenamiento priorizan la coherencia en contextos largos, las llamadas a herramientas y la inferencia eficiente en costes para cargas de trabajo de producción. Estas decisiones de diseño permiten que GLM-5 ejecute flujos de trabajo orientados a agentes extendidos (por ejemplo: navegar → planificar → escribir/probar código → iterar) manteniendo el contexto sobre entradas muy largas.
Aspectos técnicos clave:
- Arquitectura MoE con ~744B totales / ~40B parámetros activos; preentrenamiento escalado (~28.5T tokens reportados) para cerrar la brecha con modelos cerrados de vanguardia.
- Compatibilidad y optimizaciones para contexto largo (atención dispersa profunda, DSA) para reducir el coste de despliegue frente al escalado denso ingenuo.
- Capacidades orientadas a agentes integradas: invocación de herramientas/funciones, compatibilidad con sesiones con estado y salidas integradas (capaz de producir artefactos
.docx,.xlsx,.pdfcomo parte de flujos de trabajo de agentes en interfaces de proveedores). - Disponibilidad de pesos abiertos (pesos publicados en hubs de modelos) y opciones de acceso alojadas (APIs de proveedores, microservicios de inferencia).
¿Cuáles son las principales ventajas de GLM-5?
Planificación orientada a agentes y memoria de largo horizonte
La arquitectura y el ajuste de GLM-5 priorizan un razonamiento coherente en múltiples pasos y la memoria a lo largo de los flujos de trabajo, lo que beneficia a:
- agentes autónomos (pipelines de CI, orquestadores de tareas),
- generación o refactorización de código a gran escala y en múltiples archivos, y
- inteligencia documental que necesita mantener historiales extensos.
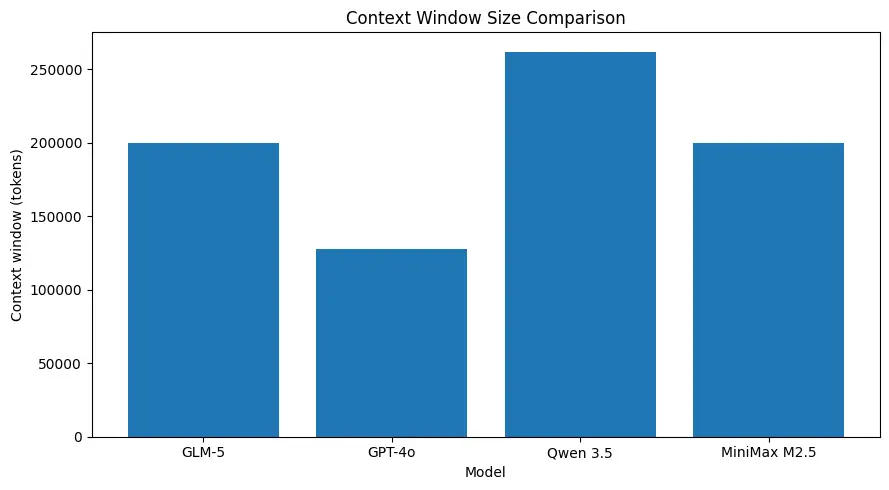
Ventanas de contexto grandes
GLM-5 admite tamaños de contexto muy grandes (del orden de ~200k tokens en las especificaciones publicadas del modelo), lo que te permite mantener más de una sesión en una sola solicitud y reduce la necesidad de fragmentación agresiva o memoria externa en muchos casos de uso. (Consulta la tabla comparativa más abajo.)
Gran rendimiento de programación para tareas a nivel de sistema
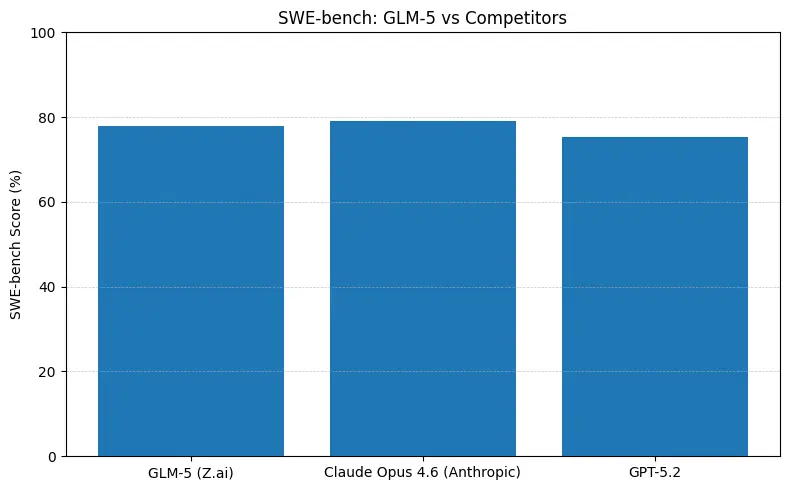
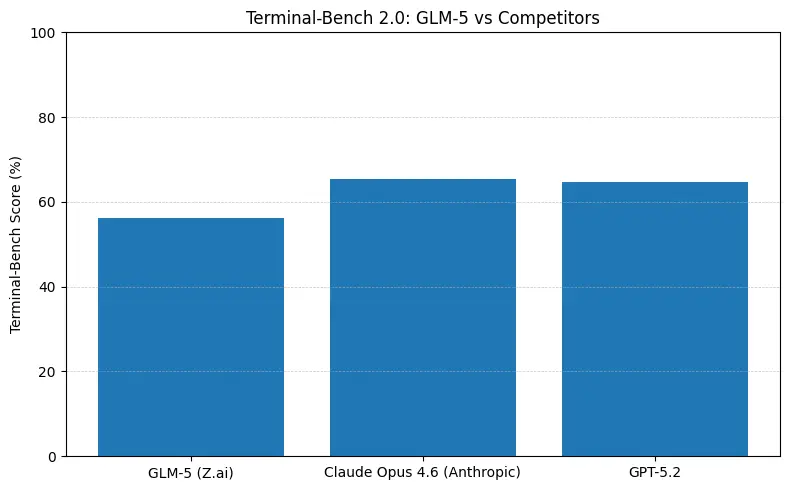
GLM-5 reporta un rendimiento de código líder entre los modelos de código abierto en benchmarks de ingeniería de software (SWE-bench y suites aplicadas de código + agentes). En SWE-bench-Verified reporta ~77.8%; en pruebas de agentes de estilo terminal/código (Terminal-Bench 2.0) las puntuaciones se agrupan en la franja media de los 50, evidencia de una capacidad práctica de programación que se acerca a los modelos propietarios de vanguardia. Estas métricas significan que GLM-5 es adecuado para tareas como generación de código, refactorización automatizada, razonamiento multiarchivo y escenarios de asistente para CI/CD.
Compromisos entre coste y eficiencia
Dado que GLM-5 utiliza MoE e innovaciones de atención “dispersa”, pretende reducir el coste de inferencia por unidad de capacidad frente al escalado denso por fuerza bruta. CometAPI ofrece precios competitivos que hacen de GLM-5 una opción atractiva para cargas de trabajo de agentes de alto rendimiento.
¿Cómo uso la API de GLM-5 a través de CometAPI?
Respuesta corta: trata CometAPI como una pasarela compatible con OpenAI: establece tu URL base y clave de API, elige glm-5 como modelo y llama al endpoint de chat/completions. CometAPI proporciona una superficie REST al estilo OpenAI (endpoints como /v1/chat/completions), además de SDKs y proyectos de ejemplo que hacen trivial la migración.
A continuación, un recetario práctico orientado a producción: autenticación, llamada básica de chat, streaming, invocación de funciones/herramientas y manejo de coste/respuestas.
Los pasos básicos para acceder a GLM-5 a través de CometAPI son:
- Regístrate en CometAPI y obtén una clave de API.
- Busca el identificador exacto del modelo para GLM-5 en el catálogo de CometAPI (
"glm-5"según el listado). - Envía una solicitud POST autenticada al endpoint chat/completions de CometAPI (estilo OpenAI).
Detalles base (patrones de CometAPI): la plataforma admite rutas al estilo OpenAI como https://api.cometapi.com/v1/chat/completions, autenticación Bearer, parámetro model, mensajes de system/user, streaming y ejemplos en curl/python en la documentación.
Ejemplo: finalización de chat rápida en Python (requests) con GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Ejemplo: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Respuestas en streaming (patrón práctico)
CometAPI admite streaming al estilo OpenAI (SSE / por fragmentos). El enfoque más simple en Python es solicitar "stream": true e iterar sobre los datos de respuesta a medida que llegan. Esto es importante cuando necesitas salida parcial de baja latencia (crear asistentes de desarrollo en tiempo real, UIs con streaming).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Referencia: documentación de streaming al estilo OpenAI y compatibilidad de CometAPI.
Invocación de funciones/herramientas (cómo llamar a una herramienta externa)
GLM-5 admite patrones de invocación de funciones o herramientas compatibles con convenciones de OpenAI/agregadores (la pasarela transmite llamadas a funciones estructuradas en la respuesta del modelo). Caso de uso de ejemplo: pedir a GLM-5 que llame a una herramienta local “run_tests”; el modelo devuelve una instrucción estructurada que puedes analizar y ejecutar.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Cuando el modelo devuelva una carga function_call, ejecuta la herramienta en el servidor y luego alimenta el resultado de la herramienta como un mensaje con rol "tool" para reanudar la conversación. Este patrón habilita invocaciones de herramientas seguras y flujos de agentes con estado. Consulta la documentación y los ejemplos de CometAPI para obtener ayudas concretas en los SDKs.
Parámetros prácticos y ajuste
function_call: úsalo para habilitar la invocación de herramientas estructurada y flujos de ejecución más seguros.
temperature: 0–0.3 para salidas deterministas a nivel de sistema (código, infraestructura), más alto para ideación.
max_tokens: ajusta según la longitud de salida esperada; GLM-5 admite salidas muy largas cuando está alojado (los límites del proveedor varían).
top_p / muestreo por núcleo: útil para limitar colas poco probables.
stream: true para UIs interactivas.
Comparación de GLM-5 con Claude Opus de Anthropic y otros modelos de vanguardia
Respuesta corta: GLM-5 reduce la brecha con los modelos cerrados de vanguardia en benchmarks de agentes y programación, a la vez que ofrece despliegue con pesos abiertos y, a menudo, mejor coste por token cuando está alojado por agregadores. El matiz: en algunos benchmarks absolutos de programación (SWE-bench, variantes de Terminal-Bench) Claude Opus (4.5/4.6) de Anthropic aún lidera por unos puntos en muchos rankings publicados, pero GLM-5 es altamente competitivo y supera a muchos otros modelos abiertos.
Qué significan los números en la práctica
- SWE-bench (~corrección de código / ingeniería): Claude Opus muestra una ventaja marginal (≈79% vs GLM-5 ≈77.8%) en los rankings publicados; para muchas tareas reales esa brecha se traducirá en menos ediciones manuales, pero no necesariamente en una elección de arquitectura distinta para prototipos o flujos de trabajo orientados a agentes a escala.
- Terminal-Bench (tareas de agentes en línea de comandos): Opus 4.6 lidera (≈65.4% vs GLM-5 ≈56.2%): si necesitas automatización de terminal robusta y máxima fiabilidad en operaciones de shell fuera de distribución, Opus suele ser mejor por un pequeño margen.
- Agentes y largo horizonte: GLM-5 rinde extremadamente bien en simulaciones de negocios de largo horizonte (Vending-Bench 2 balance $4,432 reportado) y muestra una fuerte coherencia de planificación para flujos de trabajo multietapa. Si tu producto es un agente de larga duración (finanzas, operaciones), GLM-5 es sólido.
¿Cómo diseño prompts y sistemas para obtener resultados fiables con GLM-5?
Mensajes de sistema y restricciones explícitas
Asigna a GLM-5 un rol y restricciones estrictas, especialmente para tareas de código o invocación de herramientas. Ejemplo:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Pide pruebas y un razonamiento breve para cada cambio no trivial.
Descomponer tareas complejas
En lugar de “escribe el producto completo”, pide:
- esquema de diseño,
- firmas de interfaces,
- implementación y pruebas,
- script final de integración.
Esta descomposición por etapas reduce las alucinaciones y aporta puntos de control deterministas que puedes validar.
Usa temperatura baja para código determinista
Al solicitar código, configura temperature en 0–0.2 y max_tokens a un límite superior seguro. Para escritura creativa o lluvia de ideas de diseño, aumenta la temperatura.
Mejores prácticas al integrar GLM-5 (vía CometAPI o hosts directos)
Ingeniería de prompts y prompts de sistema
- Usa instrucciones de system explícitas que definan roles de agente, políticas de acceso a herramientas y restricciones de seguridad. Ejemplo: “Eres un arquitecto de sistemas: solo propone cambios cuando las pruebas unitarias pasan localmente; enumera los comandos exactos de CLI a ejecutar.”
- Para tareas de código, proporciona contexto del repositorio (lista de archivos, fragmentos clave) y adjunta salidas de pruebas unitarias si es posible. El manejo de contexto largo de GLM-5 ayuda, pero coloca siempre el contexto esencial primero (rol, tarea) y luego los artefactos de soporte.
Gestión de sesión y estado
- Usa IDs de sesión para conversaciones largas de agentes y mantén una “memoria” compactada de pasos previos (resúmenes) para evitar el crecimiento del contexto. CometAPI y pasarelas similares proporcionan ayudas de sesión/estado, pero la compactación de estado a nivel de aplicación es esencial para agentes de larga duración.
Herramientas y llamadas a funciones (seguridad + fiabilidad)
- Expón un conjunto reducido y auditable de herramientas. No permitas ejecución de shell arbitraria sin supervisión humana. Usa definiciones de funciones estructuradas y valida sus argumentos en el servidor.
- Registra siempre las llamadas a herramientas y las respuestas del modelo para trazabilidad y depuración posterior.
Control de costes y batching
- Para agentes de alto volumen, enruta el procesamiento en background a variantes de modelo más baratas cuando los compromisos de calidad sean aceptables (CometAPI te permite cambiar de modelo por nombre). Agrupa solicitudes similares y reduce
max_tokenscuando sea posible. Supervisa la relación de tokens de entrada vs salida: los tokens de salida suelen ser más caros.
Ingeniería de latencia y rendimiento
- Usa streaming para sesiones interactivas. Para trabajos de agentes en background, prefiere runtimes asíncronos, colas de trabajo y limitadores de tasa. Si alojas por tu cuenta (pesos abiertos), ajusta tu topología de aceleradores a la arquitectura MoE: opciones FPGA / Ascend / silicio especializado pueden aportar ventajas de coste.
Notas finales
GLM-5 representa un paso práctico y de pesos abiertos hacia la ingeniería basada en agentes: sus grandes ventanas de contexto, capacidades de planificación y sólido desempeño en código lo hacen atractivo para herramientas de desarrollador, orquestación de agentes y automatización a nivel de sistema. Usa CometAPI para una integración rápida o un “jardín” de modelos en la nube para hosting gestionado; valida siempre en tu carga de trabajo e instrumenta exhaustivamente para controlar costes y alucinaciones.
Los desarrolladores pueden acceder a GLM-5 a través de CometAPI ahora. Para empezar, explora las capacidades del modelo en el Playground y consulta la guía de la API para instrucciones detalladas. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y obtenido la clave de API. CometAPI ofrece un precio muy inferior al oficial para ayudarte a integrar.
¿Listo para empezar?→ Regístrate en M2.5 hoy
Si quieres conocer más consejos, guías y noticias sobre IA, síguenos en VK, X y Discord.