

La empresa china Z.ai (anteriormente Zhipu AI) ha vuelto a ser noticia con el lanzamiento de su serie GLM 4.5 de código abierto. Posicionada como una alternativa rentable y de alto rendimiento a los grandes modelos de lenguaje existentes, GLM-4.5 promete transformar la economía de tokens y democratizar el acceso para startups, empresas e instituciones de investigación. Este artículo exhaustivo explora los orígenes, la estructura de precios y el valor real de la serie GLM-4.5, abordando dos preguntas clave que preocupan a todos los interesados: ¿cuánto cuesta y si vale la pena?
¿Qué es la Serie GLM 4.5?
La serie GLM 4.5 de Z.ai se basa en un marco de IA "agentic", lo que significa que el modelo puede descomponer de forma autónoma tareas complejas en subtareas secuenciales más pequeñas, lo que mejora la precisión y reduce la computación redundante. Esto contrasta con los LLM más monolíticos que gestionan las indicaciones en una sola pasada. Según Z.ai, GLM 4.5 integra de forma nativa el razonamiento y la planificación de acciones en su arquitectura principal, lo que permite flujos de trabajo de varios pasos, como la generación de visualización de datos o el procesamiento integral de documentos, sin orquestación externa.
La serie GLM 4.5, desarrollada por Z.ai, representa la última generación de modelos de lenguaje grandes de código abierto de Mezcla de Expertos (MoE), diseñados para unificar el razonamiento avanzado, la generación de código y las capacidades de agencia en una única arquitectura. Está disponible en dos versiones principales: la versión insignia GLM 4.5 (355 B parámetros totales, 32 B activos) y el más ligero GLM 4.5‑Aire (106 mil millones en total, 12 mil millones activos). Ambas variantes utilizan un mecanismo de inferencia híbrido: «modo de pensamiento» para razonamiento complejo basado en herramientas y «modo sin pensamiento» para conclusiones rápidas y directas, lo que permite una amplia gama de casos de uso, desde desarrollo integral hasta flujos de trabajo con agentes autónomos.
Especificaciones técnicas principales:
- Parámetros:GLM 4.5 presenta 355 mil millones de parámetros, con un subconjunto activo de 32 mil millones involucrados por inferencia para optimizar el uso y el rendimiento del hardware.
- Mezcla de expertos (MoE):La serie aprovecha la arquitectura MoE, enrutando tokens a subredes expertas de forma dinámica para lograr eficiencia.
- Ventana de contexto:Se amplió a 128 K tokens en plataformas selectas (por ejemplo, SiliconFlow), lo que permite alojar documentos y bases de código de gran tamaño.
- Velocidad de generación:Las variantes de alta velocidad superan los 100 tokens/seg, lo que las hace adecuadas para aplicaciones en tiempo real.
- Modos de inferencia híbridosLos usuarios pueden alternar entre el modo “pensamiento” (activación completa del MoE para razonamiento profundo) y el modo “sin pensamiento” (activación mínima para respuestas rápidas sobre la marcha), lo que otorga a los desarrolladores un control preciso sobre el rendimiento frente a la velocidad.
¿Qué variantes existen dentro de la Serie?
- GLM 4.5 (Estándar):355 B en total / 32 B de parámetros activos. Diseñado principalmente para un rendimiento equilibrado en tareas de razonamiento, codificación y agencia.
- GLM 4.5‑Aire:Una versión liviana de 106 B en total / 12 B de parámetros activos, diseñada para escenarios con estrictas restricciones de hardware o latencia, que ofrece una precisión competitiva en su clase.
¿Cuanto cuesta la Serie GLM 4.5?
¿Cuáles son los precios de los tokens de entrada y salida?
Según la información pública de precios de la API de Z.ai, el precio de GLM 4.5 es:
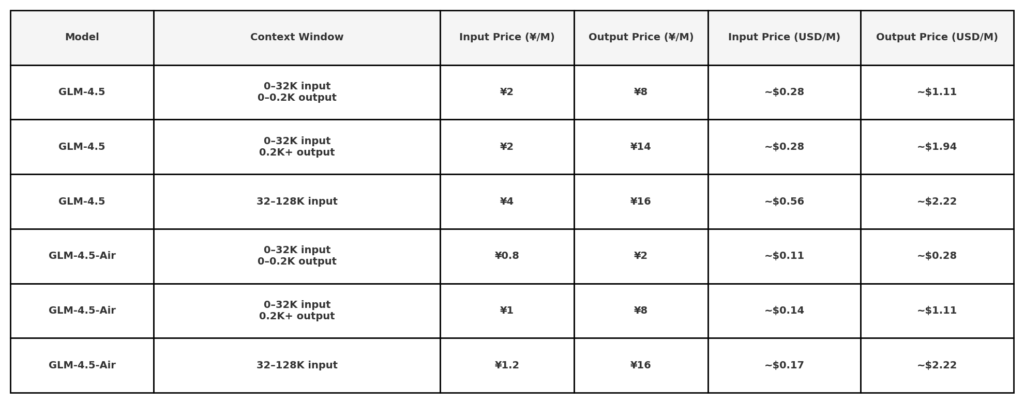
Nota: las tarifas muy bajas ($0.11/$0.28) pueden estar limitadas a pequeñas longitudes de tokens o promociones específicas. 50% de descuento en todos los modelos por tiempo limitado, válido hasta el 31 de agosto de 2025. Para otros modelos, consulte página de precios de oficina.
En CometAPI, la Serie se ofrece con precios escalonados ligeramente diferentes, consulte API GLM‑4.5:
| Modelo | introducir | Precio |
glm-4.5 | Nuestro modelo de razonamiento más poderoso, con 355 mil millones de parámetros | Tokens de entrada $0.48 Tokens de salida $1.92 |
glm-4.5-air | Rentable, ligero, de alto rendimiento | Tokens de entrada $0.16 Tokens de salida $1.07 |
glm-4.5-x | Alto rendimiento, razonamiento fuerte, respuesta ultrarrápida | Tokens de entrada $1.60 Tokens de salida $6.40 |
glm-4.5-airx | Ligero, fuerte rendimiento, respuesta ultrarrápida | Tokens de entrada $0.02 Tokens de salida $0.06 |
glm-4.5-flash | Alto rendimiento, excelente para razonamiento, codificación y agentes | Tokens de entrada $3.20 Tokens de salida $12.80 |
¿Cómo se compara el precio de GLM 4.5 con el de DeepSeek y los LLM occidentales?
En la Conferencia Mundial de IA de 2025, Z.ai posicionó explícitamente a GLM 4.5 como un rival para DeepSeek (el anterior líder en costos en China), prometiendo “una fracción del costo del token” y la mitad de la huella de hardware del modelo R1 de DeepSeek.
- Búsqueda profunda R1:Aproximadamente USD 0.14 de entrada y USD 0.60 de salida por millón de tokens.
- GLM 4.5Se afirma que su precio es entre un 20 % y un 30 % inferior al de DeepSeek, tanto en la entrada como en la salida.
- Puntos de referencia occidentales:GPT‑4 de OpenAI y Gemini de Google tienen un rango de precios que va desde USD 3 a USD 15 por millón de tokens, lo que posiciona a GLM 4.5 como una reducción de costos de un orden de magnitud.
Esta estrategia de precios refleja el modelo económico de IA más amplio de China: computación más eficiente, modelos más pequeños y una agresiva reducción de precios para capturar participación de mercado.
¿Merece la pena la serie GLM 4.5?
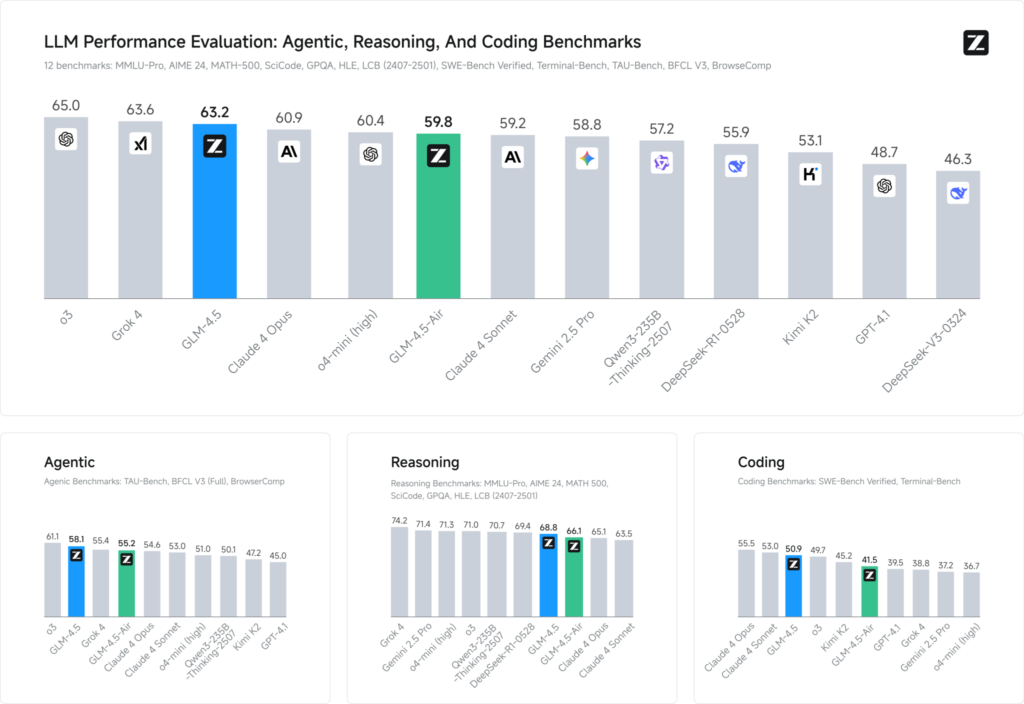
Las evaluaciones de referencia en 12 conjuntos de datos representativos (que abarcan MMLU Pro, MATH 500, SciCode, Terminal-Bench y TAU-Bench) revelan que GLM 4.5 asegura una clasificación global n.° 3 detrás de Grok 4 de xAI y o3 de OpenAI, pero ocupa el puesto n.° 1 entre las ofertas de código abierto.
En tareas de codificación (LiveCodeBench, SWE-Bench), el diseño Mixture-of-Experts de GLM 4.5 contribuye a una calidad de generación de código de primer nivel, mientras que en razonamiento (AIME 24, MMLU Pro), su planificación multipaso ofrece una precisión robusta comparable a la de sus homólogos de código cerrado. La versión ligera de Air mantiene puntuaciones competitivas dentro de su rango de parámetros (escala 100 B), lo que la convierte en una opción atractiva para implementaciones en el borde y sistemas embebidos.
Puntos de referencia de rendimiento
- Índice de inteligencia:Puntuaciones GLM 4.5 66 en un índice de inteligencia compuesto (MMLU Pro, MATH 500, AIME 24), superando a muchos modelos comerciales y de código abierto de nivel medio.
- Latencia de inferencia: Promedios de tiempo hasta el primer token 0.89 segundos, competitivo para tareas de razonamiento complejo, aunque ligeramente más lento en rendimiento (≈45.7 tokens/s) en comparación con algunos modelos optimizados de código cerrado.
- Flujo de trabajo de Agentic:Demuestra un sólido dominio del uso de herramientas de varios pasos y la generación dinámica de código, con índices de victorias cara a cara de ~54% contra Kimi K2 y 81% contra Qwen3‑Coder en evaluaciones de codificación independientes.
¿Qué casos de uso prácticos muestran el ROI?
- Desarrollo de pila completa:GLM-4.5 puede estructurar aplicaciones web completas (desde diseños frontend en HTML/CSS/JavaScript hasta esquemas de bases de datos backend) mediante indicaciones de múltiples turnos, reduciendo los ciclos de creación de prototipos de días a horas.
- Análisis de documentos complejosLa ventana de contexto ampliada de 128 K permite a las empresas legales, financieras y científicas analizar contratos de varias páginas o informes de investigación de una sola vez, lo que reduce la sobrecarga de segmentación.
- Flujos de trabajo de agentes automatizados:La inferencia híbrida permite la creación de scripts autónomos (por ejemplo, bots de raspado web, agentes comerciales) que razonan a través de procesos de múltiples pasos con una mínima intervención humana.
Los estudios de casos cuantitativos sugieren hasta 60 por ciento reducción de horas de desarrollo para tareas centradas en el código y 40 por ciento un análisis más rápido de contenidos de formato largo.
¿Cuáles son los posibles inconvenientes y consideraciones?
Ninguna tecnología está exenta de inconvenientes. Quienes la adopten deben tener en cuenta los factores regulatorios, operativos y del ecosistema.
Limitaciones
Soporte y SLAEs posible que los proveedores de código abierto no ofrezcan SLA de nivel empresarial o soporte 24 horas al día, 7 días a la semana, a diferencia de sus contrapartes comerciales.
Restricciones de rendimiento:Si bien la ventana de contexto es enorme, las tasas de tokens por segundo están por detrás de algunas contrapartes de código cerrado optimizadas para inferencia, lo que potencialmente afecta las aplicaciones en tiempo real.
Gastos operativosLos modelos MoE autohospedados requieren una orquestación cuidadosa (enrutamiento experto, administración de memoria) para evitar cuellos de botella en el rendimiento y sobrecostos.
¿Qué inversiones en infraestructura se requieren?
- Huella de cómputo: Incluso con la eficiencia de MoE, alojar la variante estándar de GLM-4.5 exige GPU con ≥80 GB de memoria e interconexiones NVLink robustas para una inferencia de baja latencia.
- Ajuste fino de gastos generales: La personalización del modelo para tareas específicas del dominio puede requerir ciclos de GPU sustanciales, lo que aumenta los costos iniciales antes de que se materialicen los ahorros en la facturación de tokens.
- Mantenimiento: Las implementaciones locales transfieren la responsabilidad de las actualizaciones, los parches de seguridad y el escalamiento del proveedor a los equipos de DevOps internos.
¿Cómo puedo empezar a utilizar GLM‑4.5?
Iniciar una integración de GLM-4.5 implica unos pocos pasos sencillos, especialmente considerando el manual de código abierto y el amplio soporte de terceros.
¿Qué API y plataformas admiten GLM‑4.5?
- CometAPI API:Punto final totalmente compatible con OpenAI, con SDK en Python, JavaScript y Java.
- Punto final directo de Z.ai:Ofrece soporte oficial y funciones de acceso temprano como orquestación de múltiples agentes.
- Espejos de la comunidad:Un conjunto de entornos de ejecución de código abierto en rápido crecimiento (por ejemplo, Ollama, AutoGPT-CLI) que permiten la inferencia local.
¿Dónde pueden los desarrolladores encontrar herramientas y documentación?
- Documentos oficiales de Z.ai: Guías completas sobre instalación, ingeniería rápida y optimización de MoE.
- Repositorios de GitHub: Cuadernos de muestra para generación de código, generación aumentada por recuperación (RAG) y marcos de agentes compatibles con las principales herramientas de orquestación.
- Foros de la comunidad: Foros de discusión activos en plataformas como Hugging Face, donde los profesionales comparten recetas de ajuste, bibliotecas de indicaciones y puntos de referencia de rendimiento.
Conclusión
La serie GLM‑4.5 se impone con fuerza en el hipercompetitivo panorama actual de la IA: una relación calidad-precio inigualable para desarrolladores, empresas e instituciones de investigación. Con precios de tokens tan bajos como 0.11 $ por millón de tokens de entrada y 0.28 $ por millón de tokens de salida (reducidos aún más con un descuento promocional del 50 %), y un rendimiento de referencia que rivaliza o supera a los modelos propietarios más grandes, GLM‑4.5 ofrece un ROI sustancial para aplicaciones centradas en código, comprensión de formatos largos y flujos de trabajo con agentes.
Primeros Pasos
CometAPI es una plataforma API unificada que integra más de 500 modelos de IA de proveedores líderes, como la serie GPT de OpenAI, Gemini de Google, Claude de Anthropic, Midjourney, Suno y más, en una única interfaz intuitiva para desarrolladores. Al ofrecer autenticación, formato de solicitudes y gestión de respuestas consistentes, CometAPI simplifica drásticamente la integración de las capacidades de IA en sus aplicaciones. Ya sea que esté desarrollando chatbots, generadores de imágenes, compositores musicales o canales de análisis basados en datos, CometAPI le permite iterar más rápido, controlar costos y mantenerse independiente del proveedor, todo mientras aprovecha los últimos avances del ecosistema de IA.
Los desarrolladores pueden acceder API de aire GLM-4.5 y API GLM‑4.5 atravesar CometAPILas últimas versiones de los modelos Claude que se muestran corresponden a la fecha de publicación del artículo. Para comenzar, explore las capacidades del modelo en... Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API". CometAPI Ofrecemos un precio muy inferior al oficial para ayudarte a integrarte.