

Comenzar con Gemini 2.5 Flash-Lite a través de CometAPI es una excelente oportunidad para aprovechar uno de los modelos de IA generativa más rentables y de baja latencia disponibles actualmente. Esta guía combina los últimos anuncios de Google DeepMind, especificaciones detalladas de la documentación de Vertex AI y pasos prácticos de integración con CometAPI para ayudarle a ponerse en marcha de forma rápida y eficaz.
¿Qué es Gemini 2.5 Flash-Lite y por qué debería considerarlo?
Descripción general de la familia Gemini 2.5
A mediados de junio de 2025, Google DeepMind lanzó oficialmente la serie Gemini 2.5, que incluye las versiones GA estables de Gemini 2.5 Pro y Gemini 2.5 Flash, junto con la vista previa de un modelo totalmente nuevo y ligero: Gemini 2.5 Flash-Lite. Diseñada para equilibrar velocidad, coste y rendimiento, la serie 2.5 representa el esfuerzo de Google por cubrir una amplia gama de casos de uso, desde cargas de trabajo de investigación intensivas hasta implementaciones a gran escala con costos ajustados.
Características principales de Flash-Lite
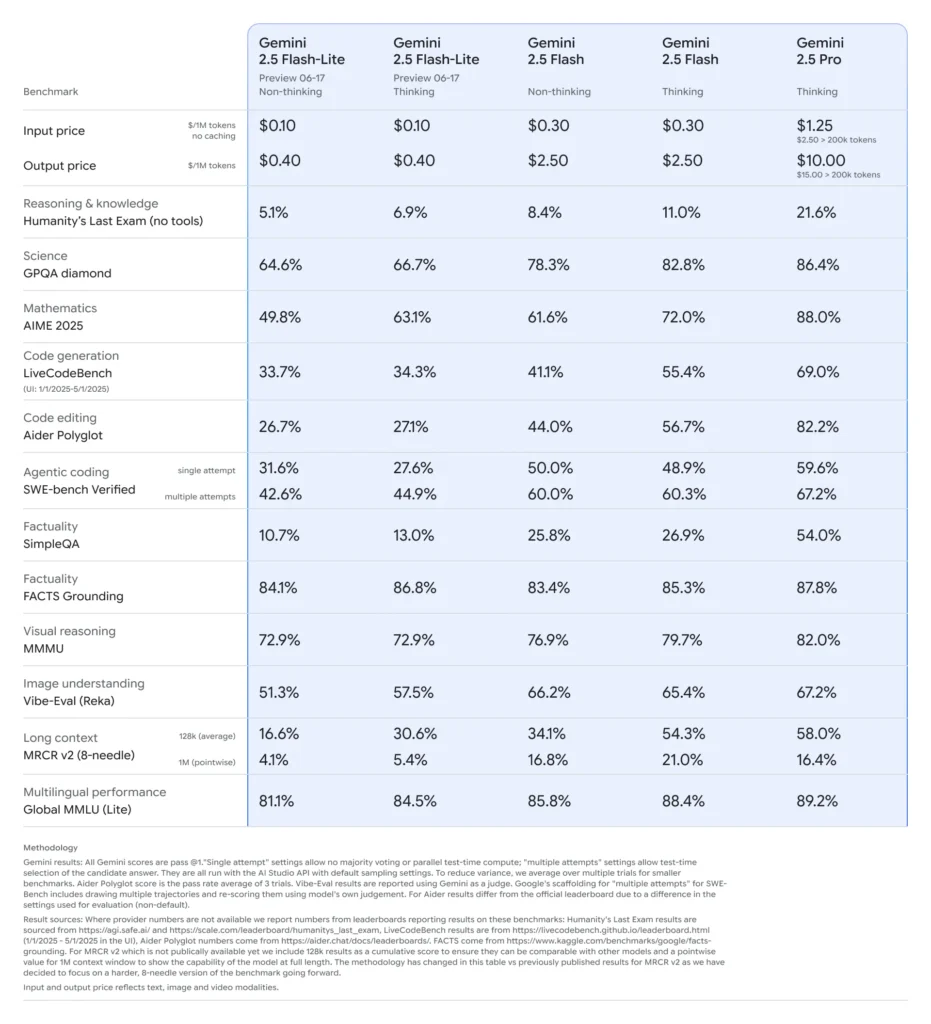
Flash-Lite se distingue por ofrecer capacidades multimodales (texto, imágenes, audio, vídeo) con una latencia extremadamente baja, con una ventana de contexto que admite hasta un millón de tokens e integraciones con herramientas como la Búsqueda de Google, la ejecución de código y la llamada a funciones. Es fundamental que Flash-Lite introduzca el control de presupuesto de pensamiento, que permite a los desarrolladores equilibrar la profundidad de razonamiento con el tiempo de respuesta y el coste mediante el ajuste de un parámetro interno de presupuesto de tokens.
Posicionamiento en la gama de modelos
En comparación con sus versiones similares, Flash-Lite se sitúa en la frontera de Pareto en cuanto a rentabilidad: con un precio aproximado de $0.10 por millón de tokens de entrada y $0.40 por millón de tokens de salida durante la versión preliminar, supera a Flash (a $0.30/$2.50) y Pro (a $1.25/$10), conservando la mayor parte de su capacidad multimodal y compatibilidad con llamadas de funciones. Esto hace que Flash-Lite sea ideal para tareas de alto volumen y baja complejidad, como resumen, clasificación y agentes conversacionales ligeros.
¿Por qué los desarrolladores deberían considerar Gemini 2.5 Flash-Lite?
Puntos de referencia de rendimiento y pruebas del mundo real
En comparaciones directas, Flash-Lite demostró:
- Rendimiento 2 veces más rápido que Gemini 2.5 Flash en tareas de clasificación.
- 3× ahorro de costes para canales de resumen a escala empresarial.
- Precisión competitiva en puntos de referencia de lógica, matemáticas y código, igualando o superando las vistas previas de Flash-Lite anteriores.
Casos de uso ideales
- Chatbots de alto volumen:Ofrezca experiencias conversacionales consistentes y de baja latencia a millones de usuarios.
- Generación automatizada de contenido:Resumen, traducción y creación de microcopias de documentos a escala.
- Canalizaciones de búsqueda y recomendación:Aproveche la inferencia rápida para la personalización en tiempo real.
- Procesamiento de datos por lotes:Anote grandes conjuntos de datos con costos computacionales mínimos.
¿Cómo obtener y administrar el acceso a la API para Gemini 2.5 Flash-Lite a través de CometAPI?
¿Por qué utilizar CometAPI como su puerta de entrada?
CometAPI integra más de 500 modelos de IA, incluida la serie Gemini de Google, en un punto final REST unificado, lo que simplifica la autenticación, la limitación de velocidad y la facturación entre proveedores. En lugar de tener que gestionar múltiples URL base y claves API, todas las solicitudes se dirigen a... https://api.cometapi.com/v1, especifique el modelo de destino en la carga útil y administre el uso a través de un único panel.
Prerrequisitos e inscripción
- Inicia sesión en cometapi.comSi aún no eres nuestro usuario, por favor regístrate primero.
- Obtenga la clave API de credenciales de acceso de la interfaz. Haga clic en "Agregar token" en el token API del centro personal, obtenga la clave del token: sk-xxxxx y envíe.
- Obtenga la URL de este sitio: https://api.cometapi.com/
Administrar sus tokens y cuotas
El panel de CometAPI proporciona cuotas de tokens unificadas que se pueden compartir entre Google, OpenAI, Anthropic y otros modelos. Utilice las herramientas de monitorización integradas para configurar alertas de uso y límites de velocidad para no exceder las asignaciones presupuestadas ni incurrir en cargos inesperados.
¿Cómo configura su entorno de desarrollo para la integración de CometAPI?
Instalación de las dependencias necesarias
Para la integración de Python, instale los siguientes paquetes:
pip install openai requests pillow
- openai:SDK compatible para comunicarse con CometAPI.
- solicitudes :Para operaciones HTTP como la descarga de imágenes.
- almohada:Para el manejo de imágenes al enviar entradas multimodales.
Inicializando el cliente CometAPI
Utilice variables de entorno para mantener su clave API fuera del código fuente:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Esta instancia de cliente ahora puede apuntar a cualquier modelo compatible especificando su ID (por ejemplo, gemini-2.5-flash-lite-preview-06-17) en sus solicitudes.
Configuración del presupuesto de pensamiento y otros parámetros
Cuando envía una solicitud, puede incluir parámetros opcionales:
- temperatura/superior_p:Controlar la aleatoriedad en la generación.
- recuento de candidatos:Número de salidas alternativas.
- tokens_max: Límite de token de salida.
- presupuesto de pensamiento:Parámetro personalizado para Flash-Lite para equilibrar profundidad, velocidad y costo.
¿Cómo se ve una solicitud básica a Gemini 2.5 Flash-Lite a través de CometAPI?
Ejemplo de solo texto
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Esta llamada devuelve un resumen conciso en menos de 200 ms, ideal para chatbots o canales de análisis en tiempo real.
Ejemplo de entrada multimodal
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite procesa imágenes de hasta 7 MB y devuelve descripciones contextuales, lo que lo hace adecuado para la comprensión de documentos, el análisis de la interfaz de usuario y los informes automatizados.
¿Cómo puedes aprovechar funciones avanzadas como la transmisión y la llamada de funciones?
Respuestas de transmisión para aplicaciones en tiempo real
Para interfaces de chatbot o subtítulos en vivo, utilice la API de transmisión:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Esto proporciona resultados parciales a medida que están disponibles, lo que reduce la latencia percibida en las interfaces de usuario interactivas.
Llamada de función para salida de datos estructurados
Defina esquemas JSON para imponer respuestas estructuradas:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Este enfoque garantiza resultados compatibles con JSON, lo que simplifica las integraciones y las canalizaciones de datos posteriores.
¿Cómo optimizar el rendimiento, el costo y la confiabilidad al utilizar Gemini 2.5 Flash-Lite?
Ajuste del presupuesto de pensamiento
El parámetro de presupuesto de pensamiento de Flash-Lite permite ajustar la cantidad de "esfuerzo cognitivo" que el modelo realiza. Un presupuesto bajo (p. ej., 0) prioriza la velocidad y el coste, mientras que valores más altos permiten un razonamiento más profundo a costa de la latencia y los tokens.
Gestión de límites de tokens y rendimiento mínimo
- Fichas de entrada:Hasta 1,048,576 tokens por solicitud.
- Fichas de salida:Límite predeterminado de 65,536 tokens.
- Entradas multimodales:Hasta 500 MB en recursos de imagen, audio y video.
Implemente el procesamiento por lotes del lado del cliente para cargas de trabajo de gran volumen y aproveche el escalamiento automático de CometAPI para manejar ráfagas de tráfico sin intervención manual.
Estrategias de coste-eficiencia
- Agrupe tareas de baja complejidad en Flash-Lite y reserve Flash Pro o estándar para trabajos pesados.
- Utilice límites de velocidad y alertas de presupuesto en el panel de CometAPI para evitar gastos descontrolados.
- Supervise el uso por ID de modelo para comparar el costo por solicitud y ajustar su lógica de enrutamiento en consecuencia.
¿Cuáles son las mejores prácticas y los próximos pasos después de la integración inicial?
Monitoreo, registro y seguridad
- Inicio de sesión:Capturar metadatos de solicitud/respuesta (marcas de tiempo, latencias, uso de token) para auditorías de rendimiento.
- Alertas:Configure notificaciones de umbral para tasas de error o sobrecostos en CometAPI.
- Seguridad:Rote las claves API periódicamente y almacénelas en bóvedas seguras o variables de entorno.
Patrones de uso comunes
- ChatbotsUtilice Flash-Lite para consultas rápidas de usuarios y recurra a Pro para seguimientos complejos.
- Procesamiento de documentos:Análisis de archivos PDF o imágenes por lotes durante la noche con un presupuesto más bajo.
- Análisis en tiempo real:Transmita datos financieros u operativos para obtener información instantánea a través de la API de transmisión.
Explorando más
- Experimente con indicaciones híbridas: combine entradas de texto e imágenes para obtener un contexto más rico.
- Prototipo RAG (Recuperación-Generación Aumentada) mediante la integración de herramientas de búsqueda vectorial con Gemini 2.5 Flash-Lite.
- Realizar una evaluación comparativa con las ofertas de la competencia (por ejemplo, GPT-4.1, Claude Sonnet 4) para validar las compensaciones entre costos y rendimiento.
Escalado en producción
- Aproveche el nivel empresarial de CometAPI para obtener grupos de cuotas dedicados y garantías de SLA.
- Implemente estrategias de implementación azul-verde para probar nuevos avisos o presupuestos sin interrumpir a los usuarios en vivo.
- Revise periódicamente las métricas de uso del modelo para identificar oportunidades de mayores ahorros de costos o mejoras de calidad.
Primeros Pasos
CometAPI proporciona una interfaz REST unificada que integra cientos de modelos de IA en un único punto de conexión, con gestión de claves API integrada, cuotas de uso y paneles de facturación. En lugar de tener que gestionar múltiples URL y credenciales de proveedores.
Los desarrolladores pueden acceder API de Gemini 2.5 Flash-Lite (versión preliminar)(Modelo: gemini-2.5-flash-lite-preview-06-17) A través CometAPILos últimos modelos listados corresponden a la fecha de publicación del artículo. Para comenzar, explore las capacidades del modelo en el Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API". CometAPI Ofrecemos un precio muy inferior al oficial para ayudarte a integrarte.
En tan solo unos pasos, puede integrar Gemini 2.5 Flash-Lite a través de CometAPI en sus aplicaciones, lo que le permitirá disfrutar de una potente combinación de velocidad, asequibilidad e inteligencia multimodal. Siguiendo las pautas anteriores (que abarcan configuración, solicitudes básicas, funciones avanzadas y optimización), estará en la mejor posición para ofrecer experiencias de IA de última generación a sus usuarios. El futuro de la IA rentable y de alto rendimiento ya está aquí: comience hoy mismo con Gemini 2.5 Flash-Lite.