

MiniMax-M2.5 es un nuevo modelo de lenguaje grande de MiniMax enfocado en la productividad y optimizado para programación, uso agéntico de herramientas y flujos de trabajo de oficina. Puedes invocarlo a través de la plataforma nativa de MiniMax o mediante agregadores de API como CometAPI. Solo necesitas obtener la clave de API de CometAPI para usar la API, ya que MiniMax-M2.5 también admite el formato de chat.
¿Qué es MiniMax-M2.5?
MiniMax-M2.5 es el último lanzamiento importante de modelos de MiniMax: una evolución de la familia M2 que la compañía posiciona como un modelo de propósito general, capaz de funcionar con agentes y con un rendimiento especialmente sólido en generación de código, uso de herramientas y razonamiento multi‑paso. La familia M2.5 se anunció como un lanzamiento de febrero de 2026 e incluye tanto la variante estándar M2.5 como las variantes “highspeed” optimizadas para menor latencia manteniendo las mismas capacidades centrales. La familia M2.5 mejoró las puntuaciones de benchmarks en evaluaciones de ingeniería de software y el comportamiento al interactuar con herramientas externas (búsqueda, agentes, etc.).
El proveedor posiciona M2.5 como un salto respecto a las versiones M2.x anteriores, con razonamiento más sólido, mejor generación de código y mayor fiabilidad en llamadas a herramientas. Las notas públicas de MiniMax a principios de febrero de 2026 señalaron M2.5 como un hito: ajuste de instrucciones refinado, mayor comprensión de código y mejoras medibles en varios benchmarks centrados en código. El lanzamiento incluye:
- Un modelo M2.5 estándar (enfatizando precisión y razonamiento).
- Una variante M2.5-highspeed con menor latencia para flujos de trabajo interactivos de desarrolladores.
- Orientación explícita y opciones de facturación para un “Coding Plan” dirigido a uso intensivo de generación de código.
Aspectos técnicos clave
- Arquitectura: MoE (gran número total de parámetros con un conjunto activo mucho más pequeño durante la inferencia), lo que habilita un punto óptimo costo/rendimiento para tareas pesadas.
- Fortalezas: rendimiento de vanguardia en programación, razonamiento multi‑turno, manejo de contexto largo e integraciones con agentes/herramientas.
- Variantes: MiniMax publica variantes (p. ej.,
MiniMax-M2.5yM2.5-highspeed) ajustadas para rendimiento vs latencia.
Por qué esto importa hoy: muchos equipos que construyen herramientas para desarrolladores, asistentes de programación y automatizaciones agénticas valoran un modelo que pueda razonar en múltiples turnos, llamar herramientas de forma segura y emitir código de alta calidad. M2.5 —por virtud de su arquitectura y elecciones de entrenamiento— se comercializa explícitamente para esos escenarios.
Benchmarking de MiniMax-M2.5
Dónde se sitúa M2.5 en benchmarks específicos de programación
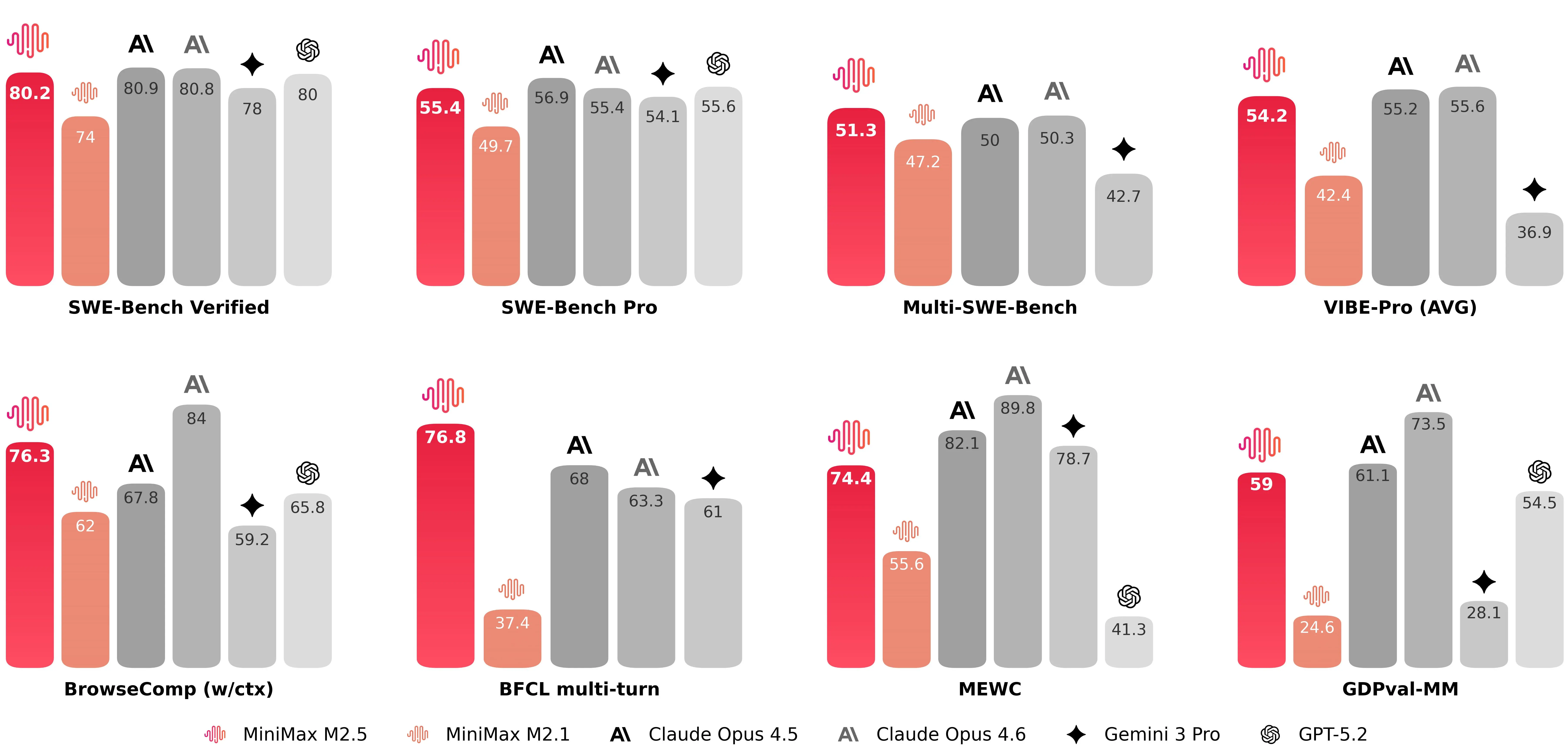
MiniMax-M2.5 logra 80.2% en SWE-Bench Verified, junto con buenas calificaciones en benchmarks de programación multitarea y con navegación aumentada (cifras destacadas publicadas por la compañía incluyen 51.3% en Multi-SWE-Bench y 76.3% en BrowseComp cuando la gestión de contexto está habilitada). Estas cifras posicionan a M2.5 entre los modelos de mayor rendimiento disponibles públicamente para generación de código y resolución de problemas en su lanzamiento. El lanzamiento de MiniMax-M2.5 corrobora que M2.5 compite con el máximo nivel de modelos de programación.
Para los desarrolladores, el beneficio es doble:
- Mayor tasa de éxito en el primer intento: menos rondas de correcciones, menos depuración manual y menor “supervisión” para agentes de programación autónomos.
- Mejor cobertura full‑stack: se describe que M2.5 admite flujos de trabajo full‑stack en aplicaciones de escritorio, móviles y toolchains multiplataforma, lo que significa que busca generar no solo fragmentos sino soluciones coherentes de múltiples archivos y scripts de construcción.
Diseñado para flujos de trabajo agénticos
Se describe que M2.5 está “diseñado de forma nativa para escenarios de agentes”. En la práctica, eso significa que la arquitectura y el régimen de entrenamiento priorizan:
- Fidelidad en la invocación de herramientas: realizar llamadas a API o ejecutar comandos shell/SQL con la sintaxis y parámetros correctos.
- Cambio de contexto y memoria: continuar una operación multi‑paso interrumpida sin perder el estado previamente calculado.
- Manipulación de archivos: producir y editar formatos de oficina comunes de forma programática (por ejemplo, generar un Powerpoint y luego revisarlo en función de una solicitud posterior).
Búsqueda y navegación mejoradas
Cuando M2.5 se combina con capas de navegación o recuperación, MiniMax reporta mejoras marcadas en benchmarks de navegación, reflejando un mejor rendimiento al integrar información externa y citas en las salidas. Eso hace a M2.5 adecuado para herramientas que deben obtener contenido actualizado, verificar resultados de API o aumentar la generación de código con datos del mundo real (por ejemplo, obtener la documentación más reciente de un SDK y usarla correctamente durante la generación de código). Estas capacidades importan para equipos que construyen funciones “agénticas” como QA automatizado, toolchains de CI o asistentes impulsados por documentos.

¿Cómo puedo usar la API de MiniMax-2.5 (a través de CometAPI)?
CometAPI es una plataforma de agregación de API que expone cientos de modelos a través de una única superficie REST compatible con OpenAI. Como la interfaz de CometAPI refleja los endpoints de chat/completions de OpenAI, a menudo puedes reutilizar clientes estilo OpenAI cambiando api_base y la clave de API. Si prefieres no integrarte directamente con la plataforma de MiniMax (por razones como facturación unificada, pruebas A/B multi‑modelo o abstracción del proveedor), puedes invocar MiniMax-M2.5 a través de la superficie de “chat” de CometAPI. La plataforma CometAPI proporciona un formato de solicitud consistente, un SDK y un playground web, y expone nombres por modelo y parámetros (para que selecciones la cadena exacta de proveedor/modelo al invocar).
A continuación se muestra una guía concisa y práctica para invocar MiniMax-M2.5 mediante CometAPI, con ejemplos en curl y Python.
¿Cuáles son los pasos básicos para empezar?
- Regístrate en una cuenta de CometAPI y obtén una clave de API. (CometAPI proporciona un playground y SDKs para probar modelos).
- Revisa la lista de modelos de CometAPI o el playground de CometAPI para encontrar el nombre exacto del modelo para MiniMax-M2.5.
- Realiza una solicitud POST autenticada con el parámetro
modelestablecido al modelo MiniMax seleccionado y una carga útil que siga el esquema de chat/completion de CometAPI. - Ajusta los parámetros (temperature, max_tokens, mensajes del sistema, streaming) según tu flujo de trabajo.
Autenticación y conceptos básicos de endpoints
- Base URL:
https://api.cometapi.com/v1(se admiten rutas estilo OpenAI como/chat/completions). - Header:
Authorization: Bearer YOUR_COMETAPI_KEY - Content-Type:
application/json - Campo Model: usa la cadena de modelo exacta del catálogo de modelos de CometAPI (examples:
"minimax-m2.5"
Ejemplo 1 — curl rápido (REST, estilo OpenAI)
# Replace $COMETAPI_KEY with your CometAPI key
curl -s -X POST "https://api.cometapi.com/v1/chat/completions" \
-H "Authorization: Bearer $COMETAPI_KEY" \
-H "Content-Type": "application/json" \
-d '{
"model": "minimax-m2.5",
"messages": [
{"role":"system","content":"You are a concise, safety-conscious coding assistant."},
{"role":"user","content":"Refactor this synchronous Python function to async and add basic error handling:\n\n```\ndef fetch(user_id):\n resp = http_get(f\"https://api.example.com/users/{user_id}\")\n return resp.json()\n```"}
],
"max_tokens": 800,
"temperature": 0.0,
"stream": false
}'
Notas:
- Usa la cadena de modelo exactamente como aparece en el catálogo de CometAPI; s.
- Se admite
stream: truepara transmitir salidas (maneja eventos enviados por el servidor o respuestas fragmentadas si quieres tokens parciales).
Ejemplo 2 — Python (requests) para un chat completion
import os, requests
COMET_KEY = os.environ.get("COMETAPI_KEY") # recommended
URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {COMET_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": "minimax-m2.5", # or "minimax/minimax-m2.5" — verify Comet's model page
"messages": [
{"role": "system", "content": "You are a helpful engineer who returns clear, tested code."},
{"role": "user", "content": "Write a pytest for the following function that asserts edge cases..."}
],
"temperature": 0.1,
"max_tokens": 1000,
}
r = requests.post(URL, json=payload, headers=headers, timeout=120)
r.raise_for_status()
out = r.json()
print(out["choices"][0]["message"]["content"])
Ejemplo 3 — Uso de litellm / integración con CometAPI (capa de conveniencia en Python)
CometAPI es compatible con varios SDKs y adaptadores de la comunidad. La documentación de liteLLM muestra un flujo compacto en el que configuras COMETAPI_KEY y llamas al modelo por nombre. Es ideal para prototipado:
import os
from litellm import completion
os.environ["COMETAPI_KEY"] = "your_cometapi_key_here"
messages = [{"role":"user", "content":"Explain async/await in Python in 3 bullets."}]
resp = completion(model="minimax-m2.5", messages=messages)
print(resp.choices[0].message.content)
Las integraciones de Litellm / Comet proporcionan utilidades útiles (streaming, async, parámetro api_key explícito) que reflejan muchos patrones existentes del SDK de OpenAI.
Cómo diseñar prompts y mensajes del sistema para M2.5
Sé explícito sobre el rol y las restricciones
Dale a M2.5 un rol de sistema claro al pedir código. Ejemplo:
{"role": "system","content": "You are MiniMax M2.5, an assistant specialized in robust, readable, and well-documented code. Use Python 3.11 conventions, include type hints, and provide brief unit tests."}
Usa descomposición por pasos para problemas complejos
Cuando pidas a M2.5 implementar funcionalidades complejas, usa una breve descomposición:
- Pide un esquema de diseño.
- Solicita las firmas de interfaz.
- Pide la implementación y las pruebas.
Esto reduce el riesgo de alucinaciones y produce salidas modulares y revisables.
Temperatura, max_tokens y seguridad
- Para código determinista: establece
temperaturecerca de 0.0. - Para diseño exploratorio: una
temperatureentre 0.2–0.5 puede ofrecer enfoques creativos. - Mantén
max_tokensgeneroso para grandes refactors o suites de pruebas extensas.
Pide pruebas unitarias y razonamiento
Al solicitar código, pide también pruebas unitarias y una breve explicación del algoritmo. Eso ayuda a detectar errores sutiles y obtener artefactos ejecutables al primer intento.
Inferencia de tareas largas y seguimiento de estado
El modelo M2.5 presenta un excelente mecanismo de seguimiento de estado, garantizando eficazmente la continuidad y direccionalidad del pensamiento en secuencias largas al enfocarse en un número limitado de objetivos cada vez en lugar de procesarlo todo en paralelo. M2.5 cuenta con funcionalidad consciente del contexto, lo que permite una ejecución eficiente de tareas y una gestión de contexto optimizada.
Consejos prácticos para usar M2.5 en producción
MiniMax-M2.5 está ajustado para herramientas multi‑paso y código. A continuación, consejos prácticos basados en experiencia para obtener los mejores resultados en producción.
Ingeniería de prompts y mensajes del sistema
- Usa mensajes del sistema explícitos para el rol y las restricciones. Para tareas de código, incluye el runtime y frameworks de pruebas requeridos (p. ej., “Devuelve un pytest compatible con Python 3.11”).
- Proporciona contexto: para trabajos agénticos o multi‑paso, incluye metadatos de pasos y descripciones de herramientas como JSON estructurado o listas con viñetas. M2.5 responde bien a entradas estructuradas porque está optimizado para el uso de herramientas.
Llamadas a funciones/herramientas
- Si usas CometAPI como pasarela para llamadas a herramientas, asegúrate de que tus campos extra (p. ej.,
function_callal estilo OpenAI) coincidan con las expectativas de CometAPI/modelo. Confirma el soporte del modelo en la página del modelo de Comet, ya que la semántica de herramientas puede variar según el proveedor. - Para una orquestación robusta, divide las tareas grandes en llamadas más pequeñas y mantén puntos de control deterministas. M2.5 es fuerte siguiendo instrucciones multi‑paso, pero obtendrás el comportamiento más fiable validando tras cada paso.
Temperatura, max_tokens y control de costos
- Para generación o refactorización de código, configura una
temperaturebaja (0.0–0.2) y usamax_tokensadaptado al tamaño de salida esperado. - Para prompts exploratorios, eleva la
temperaturepero controla el mayor uso de tokens. Al enrutar vía CometAPI, compara el precio por proveedor y las reglas de fallback: CometAPI lista precios por tokens para cada instancia de modelo en su catálogo.
Ventana de contexto y documentos largos
- Las variantes de M2.5 suelen admitir contextos largos (revisa la especificación del modelo para la longitud de contexto). Para documentos muy largos, divide en fragmentos y resume; luego incluye los resúmenes más los fragmentos relevantes, en lugar de enviar archivos completos en una sola llamada.
Seguridad, contenido tóxico y mitigación de alucinaciones
- Usa barandillas: mensajes del sistema, validadores externos y suites de pruebas (p. ej., pruebas unitarias para el código generado) reducen riesgos.
- Valida referencias externas: si el modelo cita hechos o código de la web, verifica programáticamente antes de confiar o desplegar esos resultados.
Errores comunes y cómo evitarlos
Error común: confiar demasiado en una única salida del modelo
Mitigación: Ejecuta pruebas, checks estáticos y, para lógica crítica, solicita múltiples completions independientes y compáralas. CometAPI permite alternar entre múltiples modelos, y puedes cambiar entre ellos en cualquier momento usando el formato de chat de OpenAI.
Error común: usar una temperatura alta para código en producción
Mitigación: Mantén la temperature baja; si necesitas alternativas creativas, solicita múltiples variaciones de baja temperatura o pide al modelo que explique las diferencias.
Error común: ignorar el versionado del modelo
Mitigación: Rastrea los nombres de modelo y cadenas de proveedor en tus manifiestos de despliegue. Al cambiar de MiniMax-M2.5 a MiniMax-M2.5-highspeed o a otro proveedor, trátalo como un cambio de release y ejecuta pruebas de regresión.
Recomendaciones finales y expectativas realistas
MiniMax-M2.5 es un avance notable para LLMs centrados en código y agentes: promete una sólida generación de código, razonamiento multi‑turno y comportamiento seguro en el uso de herramientas. Si las prioridades de tu equipo son construir herramientas para desarrolladores robustas, frameworks de agentes o asistentes de código, M2.5 merece un lugar en tu matriz de comparación. Usar CometAPI como una pasarela unificada puede acelerar la experimentación y permitir cambiar de proveedor o hacer A/B testing sin rehacer toda tu integración.
Algunas conclusiones pragmáticas:
- Prototipa rápidamente usando el playground de CometAPI y luego fija los identificadores de modelo en el código.
- Usa una temperatura baja, pide pruebas y explicaciones, y ejecuta siempre validación automatizada.
- Trata al modelo como un co‑desarrollador potente, no infalible: aplica revisión humana, pipelines de CI y telemetría.
Los desarrolladores pueden acceder a MInimax-M2.5 a través de CometAPI ahora. Para empezar, explora las capacidades del modelo en el Playground y consulta la guía de la API para obtener instrucciones detalladas. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y obtenido la clave de API. CometAPI ofrece un precio muy inferior al oficial para ayudarte a integrar.
¿Listo para empezar?→ Sign up fo M2.5 today !
Si quieres conocer más consejos, guías y noticias sobre IA, síguenos en VK, X y Discord!