

Claude Opus 4.6 de Anthropic llegó en febrero de 2026 como un impulso claro y con un propósito definido hacia agentes de nivel empresarial, trabajo de conocimiento con contexto largo y programación autónoma más sólida. La versión combina ingeniería ambiciosa (un modo beta de contexto de un millón de tokens, una capacidad de “pensamiento adaptativo” y funciones de trabajo en equipo entre agentes) con una decisión comercial pragmática: Anthropic mantuvo los precios de la API consistentes con sus modelos anteriores de la familia Opus. Esa combinación —capacidades materialmente mejoradas sin un aumento de precio inmediato— es el titular.
¿Qué es exactamente Claude Opus 4.6?
Claude Opus 4.6 es el buque insignia de Anthropic en la línea Opus: un modelo de IA generativa a gran escala, centrado en la empresa, optimizado para flujos de trabajo orientados a agentes, programación y trabajo de conocimiento de largo alcance. Anthropic posiciona a Opus 4.6 como su modelo más inteligente para construir agentes y automatizaciones: algo diseñado no solo para responder preguntas, sino para planificar, llamar herramientas, coordinar subagentes y seguir tareas de múltiples pasos a través de grandes bases de código y corpus de documentos.
A diferencia de los chatbots orientados al consumidor, Opus 4.6 se dirige a integraciones empresariales: está disponible a través de la interfaz claude.ai de Anthropic, la API de Claude y vía CometAPI. La fortaleza de Opus 4.6 en tareas de codificación orientadas a agentes y en la invocación de herramientas. Para las empresas, esto significa que Opus 4.6 está posicionado como una actualización de reemplazo directo para asistentes agénticos, herramientas de migración de código, canalizaciones de revisión de documentos y flujos de trabajo analíticos que necesitan un contexto más amplio del que proporcionan las sesiones de chat típicas.
Análisis en profundidad de las nuevas funciones clave de Opus 4.6
Contexto de un millón de tokens (y modos prácticos)
Opus 4.6 admite una ventana de contexto predeterminada ampliada (publicitada en 200K tokens con una ventana de 1M tokens disponible en beta). Una ventana de un millón de tokens es transformadora sobre el papel: permite que el modelo contenga repositorios de código completos, extensos escritos legales, archivos de correo de varios años o grandes tablas de datos en una sola conversación, lo que reduce la necesidad de andamiaje de recuperación externo. Anthropic combina la ventana de contexto bruta con herramientas de “compactación de contexto” que ayudan a comprimir información relevante y reducir costos de tokens. En pocas palabras: Opus puede trabajar legítimamente con artefactos muy grandes sin cortarlos en fragmentos, lo que simplifica la construcción de agentes de larga duración.
¿Por qué importa?: para refactorización de código, revisión legal/financiera o proyectos de investigación que requieren razonamiento entre documentos, la ventana más grande reduce la sobrecarga de ingeniería (menos recuperaciones, menor gestión de estado) y mejora la coherencia en cadenas de razonamiento muy largas.
Pensamiento adaptativo y controles de razonamiento extendido
Opus 4.6 introduce lo que Anthropic llama “pensamiento adaptativo” (una evolución de sus anteriores ideas de “razonamiento extendido”). Es tanto una capacidad interna como un control de la API: los desarrolladores pueden ajustar los “niveles de esfuerzo” y la profundidad de planificación del modelo, permitiéndole dedicar más cómputo a planificaciones complicadas o mantener respuestas cortas y rápidas para tareas triviales.
¿Por qué importa?: los flujos de trabajo orientados a agentes son donde las mejoras marginales en calidad se componen: mejor planificación + coordinación significan menos correcciones humanas y una ejecución autónoma más confiable.
¿Qué es “equipos de agentes” y la orquestación agéntica?
Opus 4.6 introduce compatibilidad mejorada para flujos de trabajo agénticos: la capacidad de crear, coordinar y supervisar múltiples subagentes que dividen y conquistan tareas. Los materiales de Anthropic (y reportes tempranos de socios) enfatizan que Opus puede crear proactivamente subagentes, asignar subtareas, monitorizar su progreso y finalizar o cambiar estrategias según sea necesario, actuando efectivamente como un orquestador ligero para trabajos complejos de ingeniería o análisis de múltiples pasos. Esta estrecha integración entre planificación, uso de herramientas y corrección de errores es un argumento clave para equipos con mucha automatización.
Mejoras de la API y las herramientas para la integración empresarial
Anthropic amplió los controles de API para compactación, persistencia y llamadas a herramientas. El modelo admite límites de salida más grandes (Anthropic menciona hasta 128K tokens de salida), una semántica de recuperación más fina e integraciones empresariales para Microsoft 365 y entornos de desarrollo. El resultado práctico es menos “código de integración” al conectar Opus con hojas de cálculo, presentaciones y cadenas de herramientas internas. Anthropic ha integrado Opus 4.6 en herramientas de nivel superior como Claude Cowork (interfaces sin código) y actualizaciones de Claude Code que permiten a usuarios no técnicos acceder a la automatización.
¿Cómo se desempeña Opus 4.6 en los benchmarks?
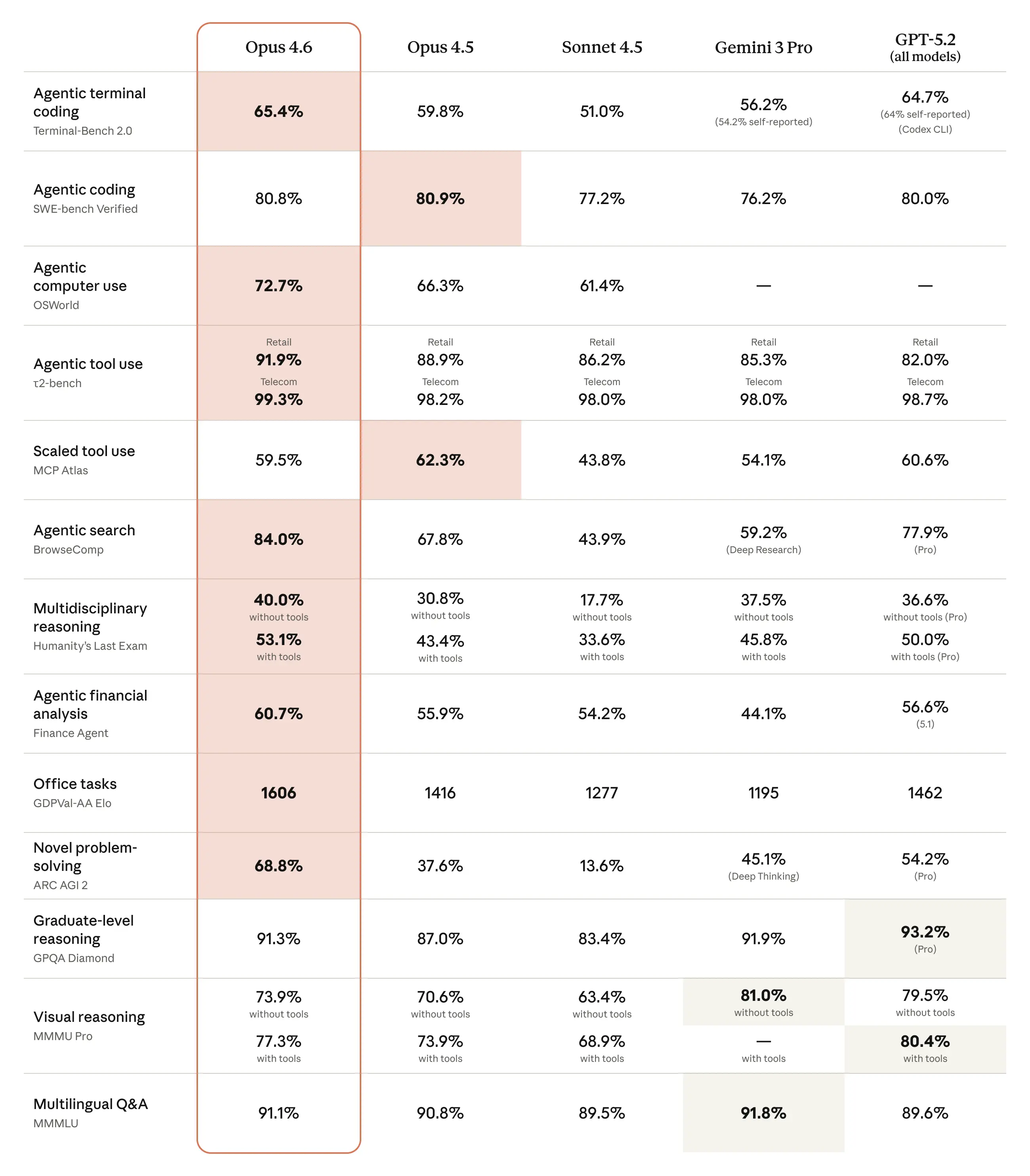
Opus 4.6 obtiene mejoras frente a Opus 4.5 y muestra posiciones competitivas frente a modelos recientes de OpenAI y Google en una mezcla de conjuntos de codificación, razonamiento y dominios específicos. Ejemplos informados brevemente:
- BigLaw Bench: Opus 4.6 alcanzó ~90.2% en el BigLaw Bench de Anthropic (razonamiento legal).
- Terminal-Bench 2.0 / métricas GDPval: coberturas independientes listan puntuaciones de Terminal-Bench 2.0 y calificaciones Elo de GDPval-AA que ubican a Opus 4.6 por delante de Opus 4.5 y competitivo con algunos lanzamientos recientes de rivales. Un informe enumeró una puntuación de Terminal-Bench 2.0 de 65.4% y un Elo GDPval-AA ~1,606.
Anthropic reporta grandes ganancias en tareas de codificación agéntica, con mejor planificación, menos iteraciones y un rendimiento más sólido en bases de código enormes, incluyendo afirmaciones de planificar y ejecutar migraciones en repositorios de varios millones de líneas en menos tiempo. Se enfatiza la capacidad mejorada del modelo para “autodetectar” errores y sostener el razonamiento a lo largo de muchos pasos.
¿Cuánto cuesta Opus 4.6?
Respuesta corta — precios por token
- Estándar (prompts ≤ 200K tokens): $5 / 1M tokens de entrada y $25 / 1M tokens de salida.
- Prompts grandes (prompts > 200K tokens): $10 / 1M de entrada y $37.50 / 1M de salida.
- Modo rápido (vista previa de investigación): un nivel premium — $30 / 1M de entrada y $150 / 1M de salida (inferencias más rápidas).
Consideraciones prácticas de costo:
- Los flujos de trabajo agénticos tienden a ser costosos en tokens. La planificación de múltiples pasos, las llamadas a herramientas y salidas largas aumentan los tokens de salida; el uso cuidadoso de la compactación y las lecturas de caché es importante para controlar la facturación.
- El procesamiento por lotes ahorra dinero. Si tu carga se ajusta al procesamiento asíncrono por lotes, los precios de la API de lotes de Anthropic pueden reducir materialmente el costo por token.
- El contexto premium es más caro. Si dependes con frecuencia del beta de 1M tokens, planifica cargos por token más altos. Muchas organizaciones combinarán modos: contextos grandes solo cuando sea absolutamente necesario y sesiones ligeras en otros casos.
¿Buscas soluciones más económicas para usar la API de Claude?
CometAPI es una buena opción. La API de Opus 4.6 también proviene de Anthropic, pero su precio de API es el 20% del precio oficial, y esto no cambia con variaciones en la longitud del contexto.
¿Cómo se compara Opus 4.6 con GPT-5.3 y Google Gemini 3?
Opus 4.6 vs GPT-5.3 de OpenAI
El reciente GPT-5.3 de OpenAI (marcado por OpenAI en la línea “Codex” para tareas de codificación/agentes) está explícitamente ajustado para codificación profunda y flujos de trabajo estilo agente y afirma puntuaciones líderes en la industria en varios benchmarks de ingeniería (SWE-Bench Pro, Terminal-Bench). Coberturas tempranas sugieren que GPT-5.3-Codex impulsa el estado del arte en benchmarks de ingeniería de software y planificación agéntica, posicionándose como el rival más cercano de Opus 4.6 en tareas puras de codificación y agentes. Opus 4.6 —en contraste— enfatiza un contexto extremadamente largo y la orquestación multiagente como diferenciadores. En resumen: GPT-5.3 parece optimizado para profundidad de ingeniería bruta y dominio de benchmarks centrados en desarrolladores; Opus 4.6 enfatiza la amplitud a través de flujos de trabajo empresariales de largo contexto y razonamiento por dominios.
¿Opus 4.6 vs Google Gemini 3?
Gemini 3 de Google (y sus variantes Gemini 3 Pro / Deep Think) ha sido destacado por un rendimiento sólido en razonamiento abstracto, resolución visual de problemas y ciertos benchmarks de QA científica; también ha avanzado el razonamiento multimodal respecto a sus predecesores. Las coberturas posicionan a Gemini 3 como particularmente fuerte en conjuntos de razonamiento científico y visual, mientras que la fortaleza de Opus 4.6 está en código de contexto largo y trabajo legal/empresarial. Para organizaciones que necesitan razonamiento científico multimodal o tareas avanzadas de lógica visual, Gemini 3 puede tener ventaja; para trabajo sostenido de conocimiento con contexto largo y automatización multiagente, Opus 4.6 sienta posición.
¿Quién “gana” en enfrentamientos directos?
Ningún proveedor “gana” universalmente: la elección depende del flujo de trabajo que te importe. Comparaciones independientes tempranas muestran a Opus 4.6 superando a Opus 4.5 de forma significativa en tareas de largo horizonte y de dominio, mientras GPT-5.3 y Gemini 3 mantienen ventajas en ciertos bancos de pruebas de codificación y multimodales. Como en cualquier generación en rápida evolución, el ganador es el cliente que asigna las fortalezas del modelo a cargas de trabajo y a la integración de herramientas del mundo real, no el modelo con la puntuación más alta en un único benchmark.
¿Vale la pena Claude Opus 4.6?
Respuesta corta: Sí — si tus problemas principales son el razonamiento con contexto largo, flujos de trabajo de agentes autónomos o cumplimiento empresarial. Las fortalezas de Opus 4.6 son reales y relevantes: las ventanas de 200K (y 1M en beta), el pensamiento adaptativo, los equipos de agentes y las integraciones empresariales son mejoras tangibles que reducen la complejidad de ingeniería de producto y amplían la clase de problemas que puedes automatizar.
Si, en cambio, tu carga de trabajo es predominantemente de microtareas cortas y altamente repetitivas donde el costo unitario y la latencia son primordiales, Opus 4.6 puede ser excesivo frente a un modelo especializado de horizonte corto (p. ej., GPT-5.3 Codex), a menos que planees combinarlos y enrutar las tareas adecuadamente.
CometAPI es una plataforma de agregación integral para APIs de modelos grandes, que ofrece integración y gestión fluidas de servicios de API. Admite la invocación de diversos modelos de IA de uso común. Esto incluye generación de imágenes, generación de video, chat, TTS y STT, todo en una sola plataforma.
También puedes elegir el modelo que desees según el costo y las capacidades del modelo, y cambiar entre ellos en cualquier momento, como Gemini 3 Flash, GPT 5.3 o Opus 4.6. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y de haber obtenido la clave de la API. CometAPI ofrece un precio muy inferior al oficial para ayudarte a integrar.
¿Listo para empezar?→ Regístrate hoy
Si quieres conocer más consejos, guías y noticias sobre IA, síguenos en VK, X y Discord!