

Kling O1, lanzado como parte de la semana de lanzamiento "Omni" de Kling AI, se posiciona como un modelo de base de video multimodal único y unificado que acepta texto, imágenes y videos en la misma solicitud y puede generar y editar videos en flujos de trabajo iterativos a nivel de director. El equipo de Kling describe a O1 como el "primer modelo de video multimodal unificado a gran escala del mundo". Las pruebas internas de Kling muestran importantes avances frente a Veo 3.1 y Runway Aleph de Google.
¿Qué es Kling O1?
Kling O1 (a menudo comercializado como Vídeo O1 or omni uno) es un modelo de base de video recién lanzado por Kling AI que unifica la generación y edición de texto, imágenes y video dentro de un único marco basado en indicaciones. En lugar de tratar la conversión de texto a video, la conversión de imagen a video y la edición de video como procesos separados, Kling O1 acepta entradas mixtas (texto + varias imágenes + video de referencia opcional) en una sola indicación, razona sobre ellas y produce clips cortos coherentes o edita material existente con un control preciso. La compañía presentó el lanzamiento como parte de un "Lanzamiento Omni" y describe O1 como un "motor de video multimodal" basado en el paradigma del Lenguaje Visual Multimodal (LVM) y un proceso de razonamiento en Cadena de Pensamiento (CdP) para interpretar instrucciones creativas complejas y multifacéticas.
El mensaje de Kling se centra en tres flujos de trabajo prácticos: (1) generación de texto → vídeo, (2) imagen/elemento → vídeo (composición e intercambio de sujeto/objeto mediante referencias explícitas), y (3) edición de vídeo/continuación de toma (reestilización, adición/eliminación de objetos, control de fotograma inicial/final). El modelo admite indicaciones multielemento (incluida la sintaxis "@" para seleccionar imágenes de referencia específicas) e incluye controles de estilo director, como el anclaje de fotograma inicial/final y la continuación de vídeo para crear secuencias multitoma.
5 aspectos destacados de Kling O1
1) Entrada multimodal unificada verdadera (MVL)
La principal capacidad del Kling O1 es procesar texto, imágenes fijas (múltiples referencias) y vídeo como entradas simultáneas de primera clase. Los usuarios pueden proporcionar varias imágenes de referencia (o un breve clip de referencia). y una instrucción en lenguaje natural; el modelo analizará todas las entradas juntas para producir o editar una salida coherente. Esto reduce la fricción en la cadena de herramientas y permite flujos de trabajo como "usar el asunto de @image1, colóquelos en el entorno desde @image2, hacer coincidir el movimiento con ref_video.mp4, y aplicar el grado de color cinematográfico X”. Este marco de “lenguaje visual multimodal” (MVL) es fundamental para el discurso de Kling.
Por qué es importante: Los flujos de trabajo creativos reales suelen requerir la combinación de referencias: un personaje de un recurso, un movimiento de cámara de otro y una instrucción narrativa en texto. Unificar estas entradas permite la generación en una sola pasada y reduce los pasos de composición manual.
2) Edición + generación en un modelo (modo multielementos)
La mayoría de los sistemas anteriores separaban la generación (texto→vídeo) de la edición con precisión de fotograma. O1 las combina intencionalmente: el mismo modelo que crea un clip desde cero también puede editar el metraje existente (cambiando objetos, renovando la ropa, eliminando accesorios o ampliando una toma), todo mediante instrucciones en lenguaje natural. Esta convergencia simplifica considerablemente el flujo de trabajo para los equipos de producción.
El modelo O1 logra una integración profunda de múltiples tareas de video en su núcleo:
- Generación de texto a vídeo
- Generación de referencia de imagen/sujeto
- Edición de vídeo y retoque
- Rediseño de vídeo
- Generación de disparos siguiente/anterior
- Generación de vídeo restringida por fotogramas clave
La mayor importancia de este diseño reside en que procesos complejos que antes requerían múltiples modelos o herramientas independientes ahora pueden completarse con un solo motor. Esto no solo reduce significativamente los costos de creación y computación, sino que también sienta las bases para el desarrollo de un modelo unificado de comprensión y generación de video.
3) La coherencia de la generación de vídeo
Consistencia de identidad: El modelo O1 mejora las capacidades de modelado de consistencia intermodal, manteniendo la estabilidad de la estructura, el material, la iluminación y el estilo del sujeto de referencia durante el proceso de generación:
- Admite imágenes de referencia de múltiples vistas para modelado de sujetos;
- Admite consistencia de sujetos en tomas cruzadas (las características de los personajes, los objetos y la escena permanecen continuas en las diferentes tomas);
- Admite referencias híbridas de múltiples sujetos, lo que permite la generación de retratos grupales y la construcción de escenas interactivas.
Este mecanismo mejora significativamente la coherencia y la “consistencia de identidad” de la generación de video, lo que lo hace adecuado para escenarios con requisitos de consistencia extremadamente altos, como publicidad y generación de tomas a nivel de película.
Memoria mejorada: El modelo O1 también posee "memoria", lo que evita que su estilo de salida se vuelva inestable debido a contextos extensos o instrucciones cambiantes. Incluso puede:
- recordar varios caracteres simultáneamente;
- permitir que diferentes personajes interactúen en el vídeo;
- Mantener la coherencia en el estilo, la vestimenta y la postura.
4) Composición precisa con sintaxis “@” y control de fotogramas de inicio y fin
Kling introdujo una abreviatura de composición (reportada como un sistema de mención “@”) para que puedas hacer referencia a imágenes específicas en el mensaje (por ejemplo, @image1, @image2) para asignar roles a los recursos de forma fiable. Combinado con la especificación explícita de fotogramas de inicio y fin, esto permite al director controlar cómo los elementos transicionan, se mueven o se transforman en el clip generado: un conjunto de características enfocadas en la producción que diferencia a O1 de muchos generadores orientados al consumidor.
5) Alta fidelidad, salidas bastante largas y apilamiento de múltiples tareas
Se informa que Kling O1 produce salidas cinematográficas de 1080p (30 fps) y, con versiones anteriores de Kling como referente, la compañía promociona la generación de clips más largos (hasta 2 minutos en informes recientes del producto). También permite apilar múltiples tareas creativas en una sola solicitud (generar, añadir un sujeto, cambiar la iluminación y editar la composición). Estas propiedades lo hacen competitivo frente a los motores de texto→vídeo de gama alta.
Por qué es importante: Los clips más largos y de alta fidelidad y la capacidad de combinar ediciones reducen la necesidad de unir muchos clips cortos y simplifican la producción de principio a fin.
¿Cómo está diseñado Kling O1 y cuáles son los mecanismos subyacentes?
O1 alrededor de un Lenguaje visual multimodal (MVL) Núcleo: un modelo que aprende incrustaciones conjuntas para lenguaje + imágenes + señales de movimiento (fotogramas de vídeo y características de flujo óptico), y luego aplica decodificadores de difusión o basados en transformadores para sintetizar fotogramas temporalmente coherentes. El modelo se describe como... acondicionamiento en múltiples referencias (texto; imágenes de uno a muchos; videoclips cortos) para producir una representación de video latente que luego se decodifica en imágenes por cuadro mientras se preserva la consistencia temporal mediante atención entre cuadros o módulos temporales especializados.
1. Transformador multimodal + Arquitectura de contexto largo
El modelo O1 emplea la arquitectura Transformer multimodal desarrollada por Keling, que integra señales de texto, imagen y video y admite una memoria de contexto temporal largo (Multimodal Long Context).
Esto permite que el modelo comprenda la continuidad temporal y la consistencia espacial durante la generación de video.
2. MVL: Lenguaje visual multimodal
MVL es la innovación central de esta arquitectura.
Alinea profundamente el lenguaje y las señales visuales dentro del Transformer a través de una capa intermedia semántica unificada, de este modo:
- Permitir que un único cuadro de entrada mezcle instrucciones multimodales;
- Mejorar la comprensión precisa del modelo de las descripciones en lenguaje natural;
- Admite generación de vídeo interactivo altamente flexible.
La introducción de MVL marca un cambio en la generación de video, de “impulsada por texto” a “impulsada co-semántica-visual”.
3. Mecanismo de inferencia de cadena de pensamiento
El modelo O1 introduce una ruta de inferencia de “cadena de pensamiento” durante la etapa de generación de video.
Este mecanismo permite que el modelo realice la lógica de eventos y la deducción de tiempos antes de la generación, manteniendo así una conexión natural entre las acciones y los eventos dentro del video.
Canalizaciones de inferencia y edición
- Generacion: feed: (texto + referencias de imagen opcionales + referencias de video opcionales + configuraciones de generación) → el modelo produce cuadros de video latentes → decodifica a cuadros → posprocesamiento temporal/de color opcional.
- Edición basada en instrucciones: Feed: (video original + instrucciones de texto + referencias de imagen opcionales) → El modelo asigna internamente la edición solicitada a un conjunto de transformaciones de espacio de píxeles y luego sintetiza los fotogramas editados, conservando el contenido sin cambios. Dado que todo se encuentra en un solo modelo, se utilizan los mismos módulos de condicionamiento y temporales tanto para la creación como para la edición.
Kling Viedo o1 frente a Veo 3.1 frente a Runway Aleph
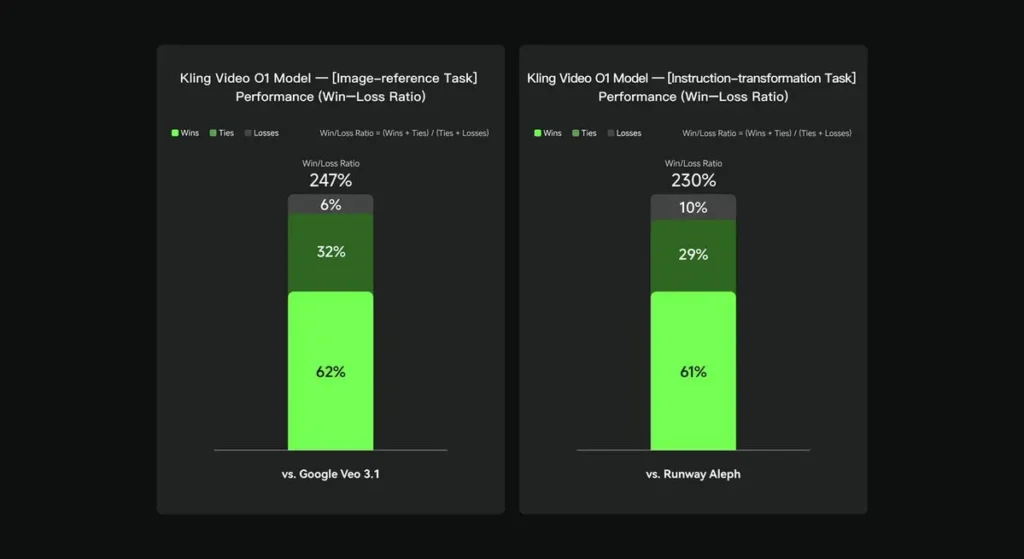
En evaluaciones internas, Keling Video O1 superó significativamente a sus homólogos internacionales en varias dimensiones clave. Resultados de rendimiento (basados en el conjunto de evaluación desarrollado por Keling AI):
- Tarea de “Referencia de imagen”: O1 supera a Google Veo 3.1 en general, con una tasa de éxito del 247 %;
- Tarea de “Transformación de instrucciones”: O1 supera a Runway Aleph, con una tasa de victorias del 230%.
Instantánea de la competencia (comparación a nivel de características)
| Capacidad / Modelo | Kling O1 | Google Veo 3.1 | Pista (Aleph / Gen-4.5) |
|---|---|---|---|
| Indicación multimodal unificada (texto + imágenes + vídeo) | Sí (argumento de venta principal). flujos multimodales de solicitud única. | Parcial: existen texto→video y referencias; menor énfasis en un único MVL unificado. | Runway se centra en la generación y edición, pero a menudo como modos separados; la última versión Gen-4.5 reduce la brecha. |
| Ediciones de píxeles conversacionales/basadas en texto | Sí — “editar como una conversación” (sin máscaras). | Parcial: existe edición, pero los flujos de trabajo con máscaras y fotogramas clave siguen siendo comunes. | Runway tiene herramientas de edición potentes; Runway afirma tener transformaciones de instrucciones potentes (varía según la versión). |
| Control de fotograma inicial/final y referencia de cámara | Sí — Se describen explícitamente los movimientos de la cámara de referencia y el cuadro de inicio y fin. | Limitado/en evolución | Pista: mejorando los controles; no exactamente la misma UX. |
| Generación de clips largos (alta fidelidad) | hasta ~2 minutos (1080p, 30 fps) en materiales de productos y publicaciones de la comunidad; | Veo 3.1: fuerte coherencia, pero las versiones anteriores tenían valores predeterminados más cortos; varía según el modelo/configuración. | Runway Gen-4.5: tiene como objetivo una alta calidad; la longitud y la fidelidad varían. |
Conclusión:
El reclamo público a la fama de Kling O1 es unificación del flujo de trabajo: otorgar a un único modelo la capacidad de comprender texto, imágenes y vídeo, y de realizar tanto la generación como la edición basada en instrucciones dentro del mismo sistema semántico. Para creadores y equipos que frecuentemente alternan entre los pasos de "crear", "editar" y "extender", esta consolidación puede simplificar drásticamente la velocidad de iteración y la complejidad de las herramientas. Mejora de la consistencia temporal, control de fotogramas de inicio y fin e integraciones pragmáticas con plataformas que lo hacen accesible a los creadores.
La API de Kling Video o1 pronto estará disponible en CometAPI.
Los desarrolladores pueden acceder Kling 2.5 Turb y API de Veo 3.1 atravesar CometAPILos últimos modelos listados corresponden a la fecha de publicación del artículo. Para comenzar, explore las capacidades del modelo en el Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API". CometAPI Ofrecemos un precio muy inferior al oficial para ayudarte a integrarte.
¿Listo para ir?→ Regístrate en CometAPI hoy !
Si quieres conocer más consejos, guías y novedades sobre IA síguenos en VK, X y Discord!