

El 17 de junio, el unicornio de inteligencia artificial de Shanghái, MiniMax, anunció oficialmente el código abierto. MiniMax‑M1, el primer modelo de inferencia de atención híbrida a gran escala y de peso abierto del mundo. Al combinar una arquitectura de Mezcla de Expertos (MoE) con el nuevo mecanismo de Atención Lightning, MiniMax-M1 ofrece importantes mejoras en velocidad de inferencia, manejo de contextos ultralargos y rendimiento en tareas complejas.
Antecedentes y evolución
Construyendo sobre la base de MiniMax-Texto-01MiniMax-M1, que introdujo la atención ultrarrápida en un marco de Mezcla de Expertos (MoE) para lograr contextos de un millón de tokens durante el entrenamiento y hasta cuatro millones en la inferencia, representa la nueva generación de la serie MiniMax-4. El modelo anterior, MiniMax-Text-1, contenía 01 mil millones de parámetros totales con 01 mil millones activados por token, lo que demuestra un rendimiento comparable al de los LLM de primer nivel, a la vez que amplía enormemente las capacidades de contexto.
Características principales de MiniMax‑M1
- Atención híbrida MoE + Lightning:MiniMax-M1 fusiona un diseño disperso de mezcla de expertos (456 mil millones de parámetros en total, pero solo 45.9 mil millones activados por token) con Lightning Attention, una atención de complejidad lineal optimizada para secuencias muy largas.
- Contexto ultralargo: Soporta hasta 1 millones tokens de entrada (aproximadamente ocho veces el límite de 128 K de DeepSeek-R1), lo que permite una comprensión profunda de documentos masivos.
- Eficiencia superior:Al generar 100 K tokens, Lightning Attention de MiniMax-M1 requiere solo entre el 25 % y el 30 % del cómputo utilizado por DeepSeek-R1.
Variantes de modelo
- MiniMax‑M1‑40K:1 M de contexto de token, 40 K de presupuesto de inferencia de token
- MiniMax‑M1‑80K:1 M de contexto de token, 80 K de presupuesto de inferencia de token
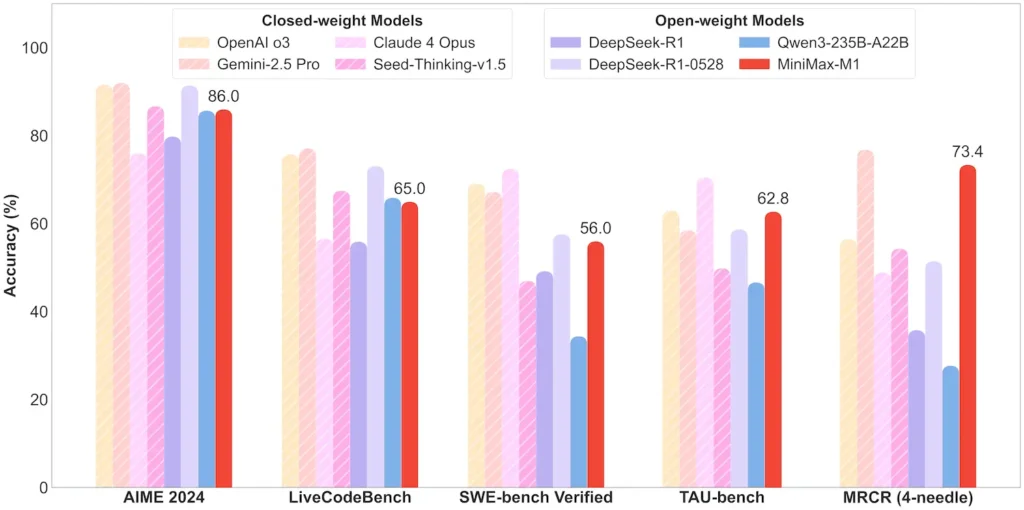
En los escenarios de uso de herramientas TAU-bench, la variante 40K superó a todos los modelos de peso abierto, incluido Gemini 2.5 Pro, lo que demuestra sus capacidades de agente.
Costo de capacitación y configuración
MiniMax-M1 se entrenó de principio a fin mediante aprendizaje por refuerzo (RL) a gran escala en un conjunto diverso de tareas, desde razonamiento matemático avanzado hasta entornos de ingeniería de software basados en entornos aislados. Un nuevo algoritmo, CISPO (Muestreo de Importancia Recortado para la Optimización de Políticas) mejora aún más la eficiencia del entrenamiento al recortar los pesos del muestreo de importancia en lugar de actualizaciones a nivel de token. Este enfoque, combinado con la atención ultrarrápida del modelo, permitió completar el entrenamiento completo de RL en 512 GPU H800 en tan solo tres semanas, con un costo total de alquiler de $534,700.
Disponibilidad y precio
MiniMax-M1 se lanza bajo la Apache 2.0 licencia de código abierto y es inmediatamente accesible a través de:
- Repositorio GitHub, incluidos pesos del modelo, scripts de entrenamiento y puntos de referencia de evaluación.
- Nube de silicio hosting, que ofrece dos variantes: 40 K-token (“M1‑40K”) y 80 K-token (“M1‑80K”), con planes para habilitar el embudo completo de 1 M token.
- Precios actualmente establecidos en ¥4 por millón tokens para entrada y ¥16 por millón tokens para salida, con descuentos por volumen disponibles para clientes empresariales.
Los desarrolladores y las organizaciones pueden integrar MiniMax-M1 a través de API estándar, ajustar datos específicos del dominio o implementar localmente para cargas de trabajo sensibles.
Rendimiento a nivel de tarea
| Categoría de tarea | Destacar | Desempeño relativo |
|---|---|---|
| Matemáticas y lógica | AIME 2024: 86.0% | > Qwen 3, DeepSeek‑R1; código casi cerrado |
| Comprensión de contexto largo | Gobernante (4 K–1 M tokens): Nivel superior estable | Supera a GPT‑4 más allá de la longitud del token de 128 K |
| Ingeniería de Software | SWE-bench (errores reales de GitHub): 56 % | El mejor entre los modelos abiertos; segundo después del líder cerrado |
| Uso de agentes y herramientas | TAU-bench (simulación API) | 62–63.5% frente a Géminis 2.5, Claude 4 |
| Diálogo y Asistente | MultiChallenge: 44.7% | Coincide con Claude 4, DeepSeek‑R1 |
| Control de calidad de hechos | SimpleQA: 18.5% | Área de mejora futura |
Nota: porcentajes y puntos de referencia de la divulgación oficial de MiniMax y de informes de noticias independientes.
Innovaciones técnicas
- Pila de atención híbrida: Atención relámpago capas (costo lineal) intercaladas con Atención Softmax periódica (cuadrática pero más expresiva) para equilibrar la eficiencia y la potencia del modelado.
- Enrutamiento de MoE disperso:32 módulos expertos; cada token solo activa ~10% de los parámetros totales, lo que reduce el costo de inferencia y preserva la capacidad.
- Aprendizaje de refuerzo CISPO:Un novedoso algoritmo de “Optimización de políticas de peso IS recortado” que conserva tokens raros pero cruciales en la señal de aprendizaje, acelerando la estabilidad y la velocidad del RL.
El lanzamiento de peso abierto de MiniMax-M1 desbloquea una inferencia de contexto ultra largo y de alta eficiencia para todos, reduciendo la brecha entre la investigación y la IA a gran escala implementable.
Primeros Pasos
CometAPI proporciona una interfaz REST unificada que integra cientos de modelos de IA, incluida la familia ChatGPT, en un punto final consistente, con gestión de claves API integrada, cuotas de uso y paneles de facturación. En lugar de tener que gestionar múltiples URL y credenciales de proveedores.
Para comenzar, explore las capacidades de los modelos en el Playground y consultar el Guía de API Para obtener instrucciones detalladas, consulte la sección "Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave API".
La última integración de la API MiniMax-M1 pronto aparecerá en CometAPI, ¡así que permanezca atento! Mientras finalizamos la carga del modelo MiniMax-M1, explore nuestros otros modelos en Página de modelos o pruébalos en el Patio de juegos de IAEl último modelo de MiniMax en CometAPI son API de vista previa de Minimax ABAB7 y API de MiniMax Video-01 ,referirse a:
