Gemini 2.5 Flash está diseñado para ofrecer respuestas rápidas sin comprometer la calidad del resultado. Admite entradas multimodales, incluidas texto, imágenes, audio y video, lo que lo hace adecuado para diversas aplicaciones. El modelo es accesible a través de plataformas como Google AI Studio y Vertex AI, proporcionando a los desarrolladores las herramientas necesarias para una integración fluida en diversos sistemas.
Información básica (Características)
Gemini 2.5 Flash introduce varias características destacadas que lo distinguen dentro de la familia Gemini 2.5:
- Razonamiento híbrido: Los desarrolladores pueden establecer el parámetro thinking_budget para controlar con precisión cuántos tokens dedica el modelo al razonamiento interno antes de generar la salida.
- Frontera de Pareto: Ubicado en el punto óptimo de costo-rendimiento, Flash ofrece la mejor relación precio-inteligencia entre los modelos 2.5.
- Compatibilidad multimodal: Procesa de forma nativa texto, imágenes, video y audio, lo que habilita capacidades conversacionales y analíticas más ricas.
- Contexto de 1 millón de tokens: Una longitud de contexto inigualable permite análisis profundos y comprensión de documentos extensos en una sola solicitud.
Versionado del modelo
Gemini 2.5 Flash ha pasado por las siguientes versiones clave:
- gemini-2.5-flash-lite-preview-09-2025: Usabilidad de herramientas mejorada: rendimiento mejorado en tareas complejas y de múltiples pasos, con un aumento del 5% en las puntuaciones de SWE-Bench Verified (de 48.9% a 54%). Eficiencia mejorada: al habilitar el razonamiento, se logra una salida de mayor calidad con menos tokens, reduciendo la latencia y los costos.
- Preview 04-17: Lanzamiento de acceso temprano con capacidad de “razonamiento”, disponible a través de gemini-2.5-flash-preview-04-17.
- Disponibilidad general estable (GA): A partir del 17 de junio de 2025, el endpoint estable gemini-2.5-flash reemplaza la vista previa, garantizando confiabilidad de nivel de producción sin cambios de API respecto a la vista previa del 20 de mayo.
- Retiro de la vista previa: Los endpoints de vista previa estaban programados para desactivarse el 15 de julio de 2025; los usuarios deben migrar al endpoint GA antes de esa fecha.
Desde julio de 2025, Gemini 2.5 Flash está disponible públicamente y es estable (sin cambios respecto a gemini-2.5-flash-preview-05-20). Si estás usando gemini-2.5-flash-preview-04-17, la tarifa de vista previa existente continuará hasta la retirada programada del endpoint del modelo el 15 de julio de 2025, cuando se cerrará. Puedes migrar al modelo de disponibilidad general "gemini-2.5-flash".
Más rápido, más barato, más inteligente:
- Objetivos de diseño: baja latencia + alto rendimiento + bajo costo;
- Aceleración general en razonamiento, procesamiento multimodal y tareas de texto largo;
- El uso de tokens se reduce entre un 20–30%, lo que reduce significativamente los costos de razonamiento.
Especificaciones técnicas
Ventana de contexto de entrada: hasta 1 millón de tokens, lo que permite una amplia retención de contexto.
Tokens de salida: capaz de generar hasta 8,192 tokens por respuesta.
Modalidades compatibles: texto, imágenes, audio y video.
Plataformas de integración: disponible a través de Google AI Studio y Vertex AI.
Precios: modelo de precios competitivo basado en tokens, que facilita un despliegue rentable.
Detalles técnicos
Bajo el capó, Gemini 2.5 Flash es un modelo de lenguaje grande basado en transformers, entrenado con una mezcla de datos de la web, código, imágenes y video. Las principales especificaciones técnicas incluyen:
Entrenamiento multimodal: Entrenado para alinear múltiples modalidades, Flash puede combinar sin problemas texto con imágenes, video o audio, útil para tareas como el resumen de video o la descripción de audio.
Proceso de razonamiento dinámico: Implementa un bucle de razonamiento interno en el que el modelo planifica y descompone indicaciones complejas antes de la salida final.
Presupuesto de razonamiento configurable: El thinking_budget se puede establecer desde 0 (sin razonamiento) hasta 24,576 tokens, lo que permite equilibrar latencia y calidad de respuesta.
Integración de herramientas: Admite Grounding with Google Search, Code Execution, URL Context y Function Calling, lo que posibilita acciones del mundo real directamente desde instrucciones en lenguaje natural.
Rendimiento en benchmarks
En evaluaciones rigurosas, Gemini 2.5 Flash demuestra rendimiento líder en la industria:
- LMArena Hard Prompts: Obtuvo el segundo lugar, solo por detrás de 2.5 Pro, en el exigente benchmark Hard Prompts, demostrando sólidas capacidades de razonamiento de múltiples pasos.
- Puntuación MMLU de 0.809: Supera el rendimiento promedio de los modelos con una precisión MMLU de 0.809, lo que refleja su amplio conocimiento de dominio y su capacidad de razonamiento.
- Latencia y rendimiento: Alcanza una velocidad de decodificación de 271.4 tokens/sec con un 0.29 s Time-to-First-Token, lo que lo hace ideal para cargas de trabajo sensibles a la latencia.
- Líder en relación precio-rendimiento: A \$0.26/1 M tokens, Flash supera en costos a muchos competidores al tiempo que los iguala o supera en benchmarks clave.
Estos resultados indican la ventaja competitiva de Gemini 2.5 Flash en razonamiento, comprensión científica, resolución de problemas matemáticos, programación, interpretación visual y capacidades multilingües:
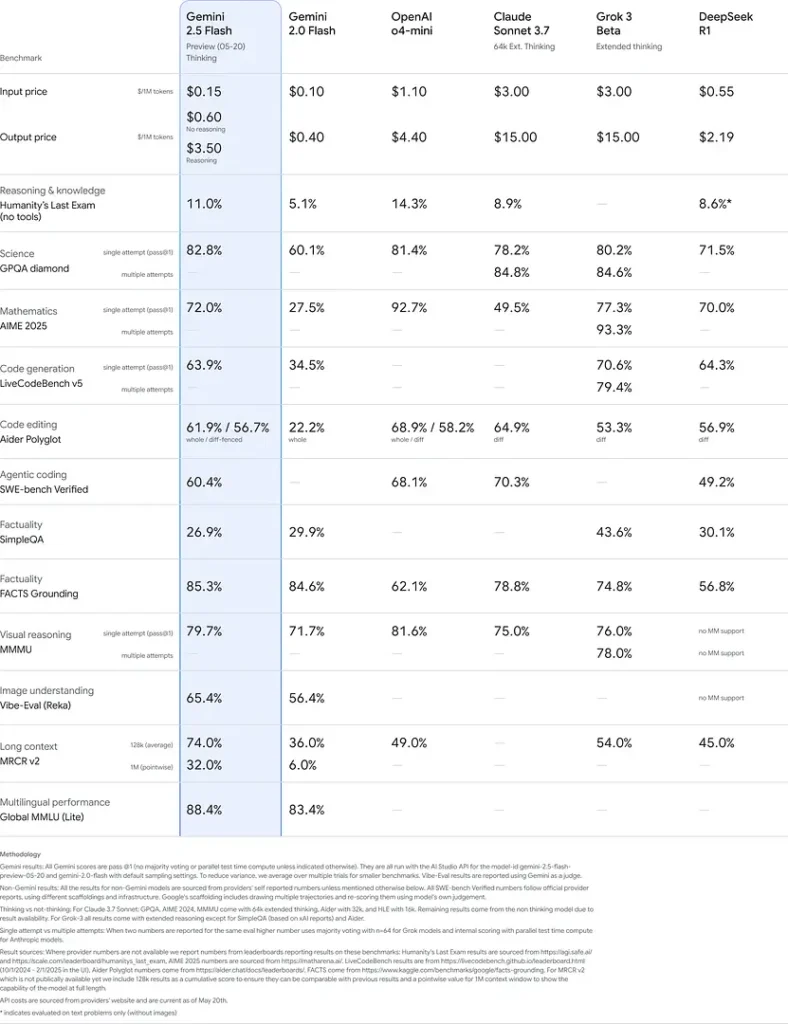
Limitaciones
- Riesgos de seguridad: El modelo puede exhibir un tono “moralizante” y puede producir salidas plausibles pero incorrectas o sesgadas (alucinaciones), especialmente en consultas de casos límite. La supervisión humana rigurosa sigue siendo esencial.
- Límites de tasa: El uso de la API está restringido por límites de tasa (10 RPM, 250,000 TPM, 250 RPD en los niveles predeterminados), lo que puede afectar el procesamiento por lotes o aplicaciones de alto volumen.
- Piso de inteligencia: Aunque es excepcionalmente capaz para un modelo «flash», sigue siendo menos preciso que 2.5 Pro en las tareas basadas en agentes más exigentes, como programación avanzada o coordinación multiagente.
- Compensaciones de costo: Aunque ofrece la mejor relación precio-rendimiento, el uso extensivo del modo de razonamiento aumenta el consumo total de tokens, elevando los costos para indicaciones que requieren razonamiento profundo.