Detalles técnicos
- Razonamiento adaptativo:
Gemini 2.5 Flash-Liteadmite razonamiento bajo demanda, lo que permite a los desarrolladores asignar recursos de cómputo solo cuando se requiere un razonamiento más profundo. - Integraciones de herramientas: Compatibilidad total con las herramientas nativas de Gemini 2.5, incluidas Grounding with Google Search, Code Execution, URL Context y Function Calling para flujos de trabajo multimodales sin problemas.
- Model Context Protocol (MCP): Aprovecha el MCP de Google para obtener datos web en tiempo real, garantizando respuestas actualizadas y contextualmente relevantes.
- Opciones de implementación: Disponible a través de CometAPI, Gemini API, Vertex AI y Google AI Studio, con un canal de vista previa para que los adoptantes tempranos experimenten y proporcionen comentarios.
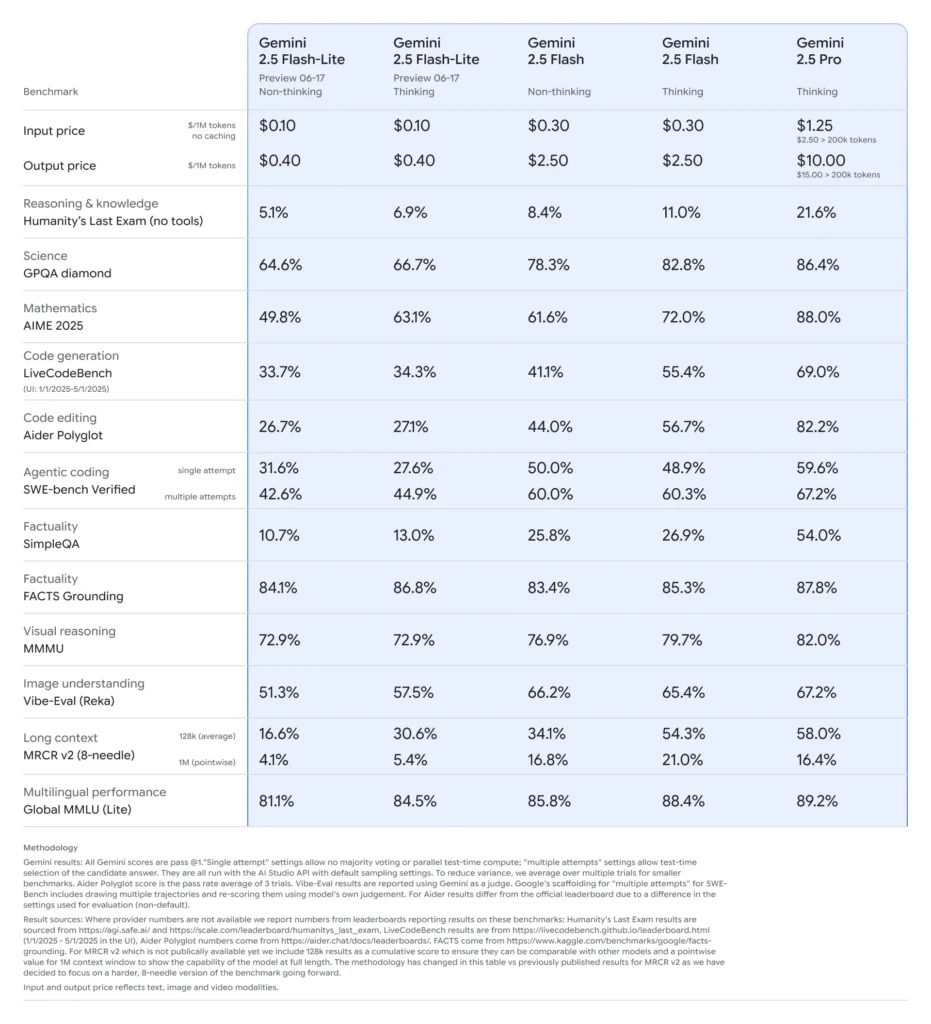
Rendimiento en benchmarks de Gemini 2.5 Flash-Lite
- Latencia: Logra hasta un 50% menos de tiempos de respuesta medianos en comparación con Gemini 2.5 Flash, con latencias inferiores a 100 ms en benchmarks estándar de clasificación y resumen.
- Rendimiento: Optimizado para cargas de trabajo de alto volumen, manteniendo decenas de miles de solicitudes por minuto sin degradación del rendimiento.
- Relación precio-rendimiento: Muestra una reducción del 25% en el costo por 1,000 tokens frente a su contraparte Flash, lo que lo convierte en la opción óptima de Pareto para implementaciones sensibles al costo.
- Adopción en la industria: Los primeros usuarios reportan una integración fluida en pipelines de producción, con métricas de rendimiento que se alinean o superan las proyecciones iniciales.
Casos de uso ideales
- Tareas de alta frecuencia y baja complejidad: etiquetado automático, análisis de sentimiento y traducción masiva
- Pipelines sensibles al costo: extracción de datos de grandes corpus de documentos, resumen periódico por lotes
- Escenarios en el edge y móviles: cuando la latencia es crítica pero los presupuestos de recursos son limitados
Limitaciones de Gemini 2.5 Flash-Lite
- Estado de vista previa: Puede sufrir cambios de API antes de GA; las integraciones deben considerar posibles aumentos de versión.
- Sin ajuste fino sobre la marcha: No permite cargar pesos personalizados; confía en el prompt engineering y los mensajes del sistema.
- Creatividad reducida: Ajustado para tareas deterministas y de alto rendimiento; menos adecuado para generación abierta o escritura “creativa”.
- Techo de recursos: Escala linealmente solo hasta ~16 vCPUs; más allá de esto, las ganancias de rendimiento disminuyen.
- Restricciones multimodales: Admite entradas de imagen/audio pero con fidelidad limitada; no es ideal para tareas intensivas de visión o transcripción de audio.
- Compromiso de ventana de contexto: Aunque acepta hasta 1 M tokens, la inferencia práctica a esa escala puede ver un rendimiento degradado.